






论文:ImageNet Classification with Deep Convolutional Neural Networks
2012 年, AlexNet 横空出世。这个模型的名字来源于论⽂第一作者的姓名 Alex Krizhevsky。AlexNet 使⽤了 8 层卷积神经⽹络,并以很⼤的优势赢得了 ImageNet 2012 图像识别挑战赛冠军。
下面这张图片是AlexNet的模型,因为当时原作者是用了两张GPU(GTX580 3GB),将模型分为两半,分别放在两个GPU上,所以模型看起来比较复杂。而在现在来说,因为GPU的运算速度大大提高,我们一般都只在一个GPU上训练了。
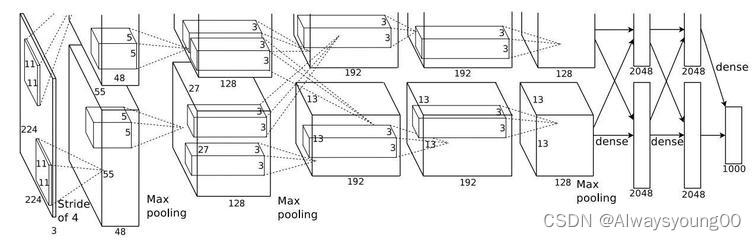
特点:
- 在每个卷机后面添加了Relu激活函数,而不是sigmoid或者tanh,使收敛更快。但是从现在来讲,大家发现其实没有太大的影响。
- 丢弃法(dropout)选择性地忽略训练中的单个神经元。这个技术当时作者来讲,是说由于随机在全连接层丢弃一些单元,相当于混合了许多不同的模型,达到混合模型的效果。但现在来看,其实是相当于正则化的效果。
- 添加了归一化LRN(Local Response Normalization,局部响应归一化)层,使准确率更高。
- 重叠最大池化(overlapping max pooling),即池化范围 z 与步长 s 存在关系 z>s 避免平均池化(average pooling)的平均效应。
总结:
提出方法:
- 直接用原始图片rgb进行训练(作者没有重点强调,但在现在看来,端对端是一个很大的优点)。
- 对模型的切割在不同GPU上训练(现在不这么做,但是对当前自然语言处理NLP领域,类似bert的大模型有启发作用)。
解决的问题:
- 在ImageNet数据集2012图像识别挑战赛上获得冠军,并且精确度遥遥领先。
仍待解决的问题:
- 使用ReLU激活函数,ReLU关闭了右边,从而会使得很多的隐层输出为0,即网络变得稀疏,起到了类似L1的正则化作用,可以在一定程度上缓解过拟合。但是很容易导致某些隐藏节点永无翻身之日,而且会很容易改变数据的分布,因此ReLU后加Batch Normalization也是常用的改进的方法。















 903
903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









