






Background & Motivation
文章认为特征聚合的关键是语义和空间信息的聚合。
Semantic fusion, or aggregating across channels and depths, improves inference of what.
Spatial fusion, or aggregating across resolutions and scales, improves inference of where.
更多的非线性,更大的感受野提高了精度但是给优化和计算带来困难。分层精度比较、可迁移分析和表征可视化都显示更深的层数可以提取到更多的语义信息,但是这些并不能证明网络最后一层的语义特征就是最终的表征。因此 Aggregation 是模型的一个至关重要的维度。
Deep Layer Aggregation(DLA)
layer、block 和 stage 之间的关系:
Layers are grouped into blocks, which are then grouped into stages by their feature resolution.

上图中的(b)与 FPN 的做法相同但它不是 FPN,而是作为 backbone,也就是说(b)中的结构可以跟 FPN 结合起来。
We define aggregation as the combination of different layers throughout a network.
We call a group of aggregations deep if it is compositional, nonlinear, and the earliest aggregated layer passes through multiple aggregations.
DLA 包含两个部分:iterative deep aggregation(IDA)和 hierarchical deep aggregation(HDA)。前者更关注融合分辨率和尺度,后者关注各个特征层和通道之间的聚合。
Iterative Deep Aggregation(IDA)
根据特征分辨率将 block 分为不同的 stage,更深层的 stage 包含更多的语义信息而丢失了细节信息。IDA 的做法是:
Aggregation begins at the shallowest, smallest scale and then iteratively merges deeper, larger scales.

这样浅层的特征就被每个不同尺度下 stage 的特征不断地 refine。我认为的 IDA 与 Fig.1 中(b)的不同之处在于:IDA 的主体是从第一个 stage 中聚合出来的 Aggregation Node,refine 第一个 Aggregation Node;而后者的主体是最后一个 stage 中聚合出来的 Aggregation Node,refine 最后一个 Aggregation Node。
Hierarchical Deep Aggregation(HDA)
IDA 聚合了 stage 之间的特征,但是并没有聚合各个 block 之间的特征。DHA 采用树的结构保存和融合 block 之间的特征:

在这个基础上增加了 Aggregation Node 与 backbone 之间的连接,将聚合到的特征 refine 到 backbone 上,再来聚合下一个 Aggregation Node:

这样就聚合了在此之前所有块的特征,而不只是其前面的那一个块。更简洁的做法:

网络整体架构如下:

Architectural Elements
- Aggregation Nodes
作用是聚合和压缩输入,选择并映射那些重要的特征来完成聚合。
In our architectures IDA nodes are always binary, while HDA nodes have a variable number of arguments depending on the depth of the tree.
具体实现:一个卷积后跟 BN 层和非线性的激活函数,在分类任务中采用1*1卷积,语义分割任务中采用3*3卷积。

Aggregation Nodes 中也可以采用残差连接模块:

但是文章中说目前尚不清楚对特征聚合是否是必要的,但在 HDA 中会缓解梯度消失和爆炸的问题。
In our experiments, we find that residual connection in node can help HDA when the deepest hierarchy has 4 levels or more, while it may hurt for networks with smaller hierarchy.
- Blocks and Stages
DLA 是通用的并且与大部分 backbone 是兼容的,并且对 block 和 stage 内的结构没有要求。使用到了三种类型的卷积块:Basic block 即带残差连接的卷积;Bottleneck blocks 即通过1*1卷积减少维度来正则化卷积块;Split block 用在 ResNeXT 上,将特征分为不同 cardinality 的卷积块。
Applications
这段没看太懂:
Our results do without ensembles for recognition and context modeling or dilation for resolution. Aggregation of semantic and spatial information matters for classification and dense prediction alike.
Classification Networks
ResNet 的介绍写的挺好,记一下:
These are staged networks, which group blocks by spatial resolution, with residual connections within each block. The end of every stage halves resolution, giving six stages in total, with the first stage maintaining the input resolution while the last stage is 32× downsampled. The final feature maps are collapsed by global average pooling then linearly scored. The classification is predicted as the softmax over the scores.
为了与 ResNet 系列更公平地对比,提出了与 ResNet 系列对标的 DLA 模型,但是为了保证 DLA 结构的完整性并没有严格对齐。后缀带 C 的都为压缩过的模型。
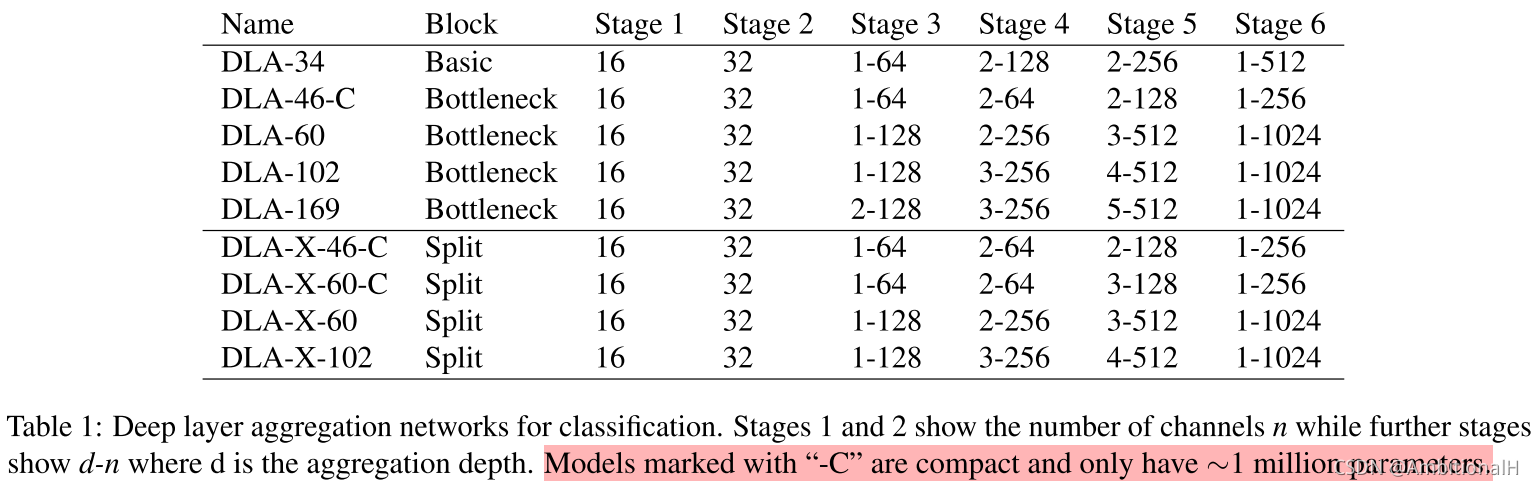
下图是 arXiv 上论文 v1 版本里找出来的参数比较,可以看出 DLA62 对标的是 ResNet50。

Dense Prediction Networks
从分类 DLA 迁移到全卷积的 DLA 比其他模型要简单的多,通过插值和增强 IDA 实现。

首先将 stage3~stage6 的输出映射到32维,之后将其插值到与 stage2 相同大小的分辨率,采用双线性插值。在两个地方使用了 IDA:第一次是聚合特征时,第二次是升采样重建分辨率时。
Results
ImageNet Classification
batch size 为256;lr 初始为0.1每30个 epoch 除以10,共训练120个 epoch。

可以看到 DLA 参数更小,错误率更低。
We usually expect diminishing returns of performance of deeper networks.
Fine-grained Recognition
batch size 为256,lr 初始为0.01,每50个 epoch 除以10,共训练110个 epoch。
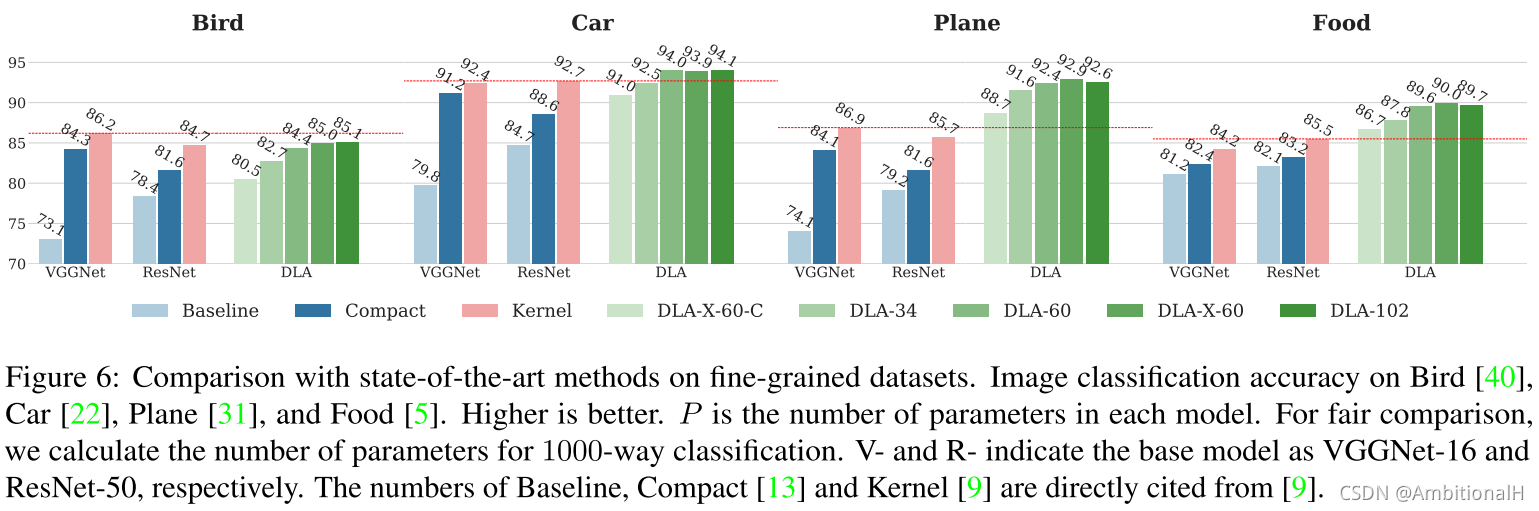
However, our results are not better than state-of-the-art on Birds, although note that this dataset has fewer instances per class so further regularization might help.
在 Bird 数据集上的表现不好,文章分析是因为平均每一个类别的目标太少。(30,还好

Semantic Segmentation
在 CamVid 数据集上 lr 初始值为0.01,每800个 epoch 除以10。

在 Cityscapes 数据集上 batch size 是16,初始 lr 是0.01,按下面公式衰减:
![]()

可以看到 DLA34 的指标跟 DLA102 不相上下。
Boundary Detection
Boundary detection is an exacting task of localization.
Although as a classification problem it is only a binary task of whether or not a boundary exists, the metrics require precise spatial accuracy.



We also find that deeper networks does not continue improving the prediction performance on BSDS.
Conclusion
感觉要比 ResNet 在一定参数范围下精度要高,而且比 ResNet 进行了更复杂的特征聚合,对小目标的性能要高于 ResNet。
附加
Mean Intersection over Union(MIoU,均交并比):为语义分割的标准度量。其计算两个集合的交集和并集之比,在语义分割的问题中,这两个集合为真实值(ground truth)和预测值(predicted segmentation)。这个比例可以变形为正真数(intersection)比上真正、假负、假正(并集)之和。在每个类上计算IoU,之后平均。

直观理解:如下图所示,红色圆代表真实值,黄色圆代表预测值。橙色部分红色圆与黄色圆的交集,即真正(预测为1,真实值为1)的部分,红色部分表示假负(预测为0,真实为1)的部分,黄色表示假正(预测为1,真实为0)的部分,两个圆之外的白色区域表示真负(预测为0,真实值为0)的部分。

ODS(optimal dataset scale),也称为全局最佳、固定阈值。即数据集固定比例 、检测指标数据集尺度上最优,简单说就是为所有图像设置同样的阈值,即选取一个固定的阈值 η 应用于所有图片, 使得整个数据集上的 F-score 最大;
OIS(optimal image scale),也称为单图最佳、每幅图像的最佳阈值。即在每一张图片上均选取不同使得该图片 F-score 最大的阈值 η。
- F-score
对于 Precision 和 Recall,虽然从计算公式来看,并没有什么必然的相关性关系,但是,在大规模数据集合中,这2个指标往往是相互制约的。理想情况下做到两个指标都高当然最好,但一般情况下,Precision 高,Recall 就低,Recall 高,Precision 就低。所以在实际中常常需要根据具体情况做出取舍,例如一般的搜索情况,在保证召回率的条件下,尽量提升精确率。而像癌症检测、地震检测、金融欺诈等,则在保证精确率的条件下,尽量提升召回率。所以,很多时候我们需要综合权衡这2个指标,这就引出了一个新的指标 F-score。这是综合考虑 Precision 和 Recall 的调和值。
















 3844
3844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









