







0.Word2Vec和Embeddings
Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型
-
Word2Vec其实就是通过学习文本来用词向量的方式表征词的语义信息,即通过一个嵌入空间使得语义上相似的单词在该空间内距离很近。
- 主要有Skip-Gram和CBOW两种模型,从直观上理解,Skip-Gram是给定input word来预测上下文。而CBOW是给定上下文,来预测input word
- Skip-Gram和CBOW两种模型的运行方式

- Word2Vec的整个建模过程实际上与自编码器(auto-encoder)的思想很相似,即先基于训练数据构建一个神经网络,当这个模型训练好以后,我们并不会用这个训练好的模型处理新的任务,我们真正需要的是这个模型通过训练数据所学得的参数,例如隐层的权重矩阵——后面我们将会看到这些权重在Word2Vec中实际上就是我们试图去学习的“word vectors”。
- 训练模型的真正目的是获得模型基于训练数据学得的隐层权重
-
自编码器(auto-encoder):通过在隐层将输入进行编码压缩,继而在输出层将数据解码恢复初始状态,训练完成后,我们会将输出层“砍掉”,仅保留隐层。
-
Embedding其实就是一个映射,将单词从原先所属的空间映射到新的多维空间中,也就是把原先词所在空间嵌入到一个新的空间中去。
1.Deepwalk
-
每个节点通过随机游走的方式,得到图上所有语调的信息

-
采用skip-gram的方式
- 第一部分为建立模型,第二部分是通过模型获取嵌入词向量
- 给定v4节点的情况下,计算v2v3v5v6同时出现的概率,通过这种方法,算出最终每个节点的embdding

-
Deepwalk算法流程

- windows size 窗口左右选取的宽度,embedding size 所要求出的embedding的大小,
- walks per vertex 每个节点循环的次数,walk length随机游走的长度
- 首先,对每个节点进行γ次的随机游走采样
- 其次,对节点进行一个打乱
- 再次对每个节点进行一个长度为t的随机游走,生成一个随机游走的序列
- 再通过SkipGram,去学习每个节点的embedding
2.LINE: Large-scale Information Network Embedding

Deepwalk在无向图上,LINE也可以在有向图上使用
一阶相似性:
求i,j节点的联合概率分布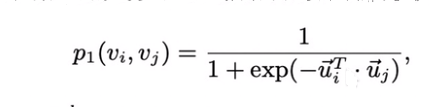
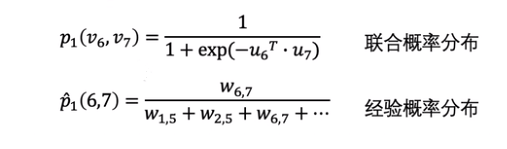
概率分布的距离越小,节点的embedding越好
KLdiversion KL散度:求两个分布的距离



二阶相似性

- u为节点的向量表示,u’为节点作为其他节点的邻居节点的向量表示
一阶二阶embedding训练完成之后,如何将其组合成一个embedding:直接拼接

3.Node2Vec
同质性:节点与周围节点的embedding相似
结构等价性:节点在图上所处的位置相似,embedding相似

采用了一种有策略的随机游走方式

- 定义了:图G+(V,E,W),graph embedding长度d,随机游走节点γ,随机游走的长度l,窗口数量k,返回的p,输入的q
- π = 在p,q的条件下图G的随机游走的概率
- 遍历每个节点,遍历γ次
- 对每个节点都采用node2vevwalk的随机游走方式
- 得到一个随机游走的序列,再将所有序列都组合在一起
- 再采用随机下降的算法,求个每个节点的embedding
提高效率的方法

- 每次取一个邻居,通过一次随机游走,得到多个序列,再根据得到的序列再以此往后类推,就可以提升随机游走的效率
结果
- DFS,即q值小,探索强。会捕获homophily同质性节点,即相邻节点表示类似
- BFS,即p值小,保守周围,会捕获结构性,即某些节点的图上结构类似
影响因素结果图

节点的embedding如何做一些边的embedding(平均,L1,L2范数)

4.Struct2Vec


f k ( u , v ) = f k − 1 ( u , v ) f_k(u,v) = f_{k-1}(u,v) fk(u,v)=fk−1(u,v)+u节点和v节点的距离的度量
动态时间规整:通过不断地压缩和拓展x轴,使得这两个节点的距离最小

- 动态时间规整算两个序列相似性,两个序列是两个节点k跳邻居的度产生序列,由此得到两个节点的结构相似性刻画
构造多层带权重图

顶点采样序列

p为人为定值, e − f k ( u , v ) 为 当 前 节 点 k 跳 某 一 邻 居 边 的 权 重 w , Z k ( u ) 为 与 节 点 k 跳 的 所 有 的 边 的 权 重 和 e^{-f_{k}(u,v)}为当前节点k跳某一邻居边的权重w,Z_k(u)为与节点k跳的所有的边的权重和 e−fk(u,v)为当前节点k跳某一邻居边的权重w,Zk(u)为与节点k跳的所有的边的权重和
使用skip-gram生成embedding

- Struct2vec适用于节点分类中,其结构标识比邻居标识更重要时,采用Struct2vec效果更好
5. SDNE:Structural Deep Network Embedding
-
之前的Deepwalk,LINE,node2vec,struc2vec都使用了浅层的结构,浅层模型往往不能捕获高度非线性的网络结构。、
-
因此产生了SDNE方法,使用多个非线性层来捕获node的embedding

-
xi表示图的邻接矩阵第i行的值(与i节点相连接的关系),将其带入到一个encoder里边(y),encoder可以是多层的
-
学习到了中间的一个向量 y i K y_i^{K} yiK,即压缩之后所要学习的一个embedding,
-
再将这个embedding decoder成与之前长度一样的向量
-
之后计算输入输出向量的结构性误差
-
学习到了节点的二阶相似性的度量
- 二阶相似性:一堆节点领域有多相似
GraphEmbedding算法总结
-
DeepWalk:采用随机游走,形成序列,采用skip-gram方式生成节点embedding。
-
node2vec:不同的随机游走策略,形成序列,类似skip-gram方式生成节点embedding。
-
LINE:捕获节点的一阶和二阶相似度,分别求解,再将一阶二阶拼接在一起,作为节点的embedding
-
struc2vec:对图的结构信息进行捕获,在其结构重要性大于邻居重要性时,有较好的效果。
-
SDNE:采用了多个非线性层的方式捕获一阶二阶的相似性。














 845
845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









