








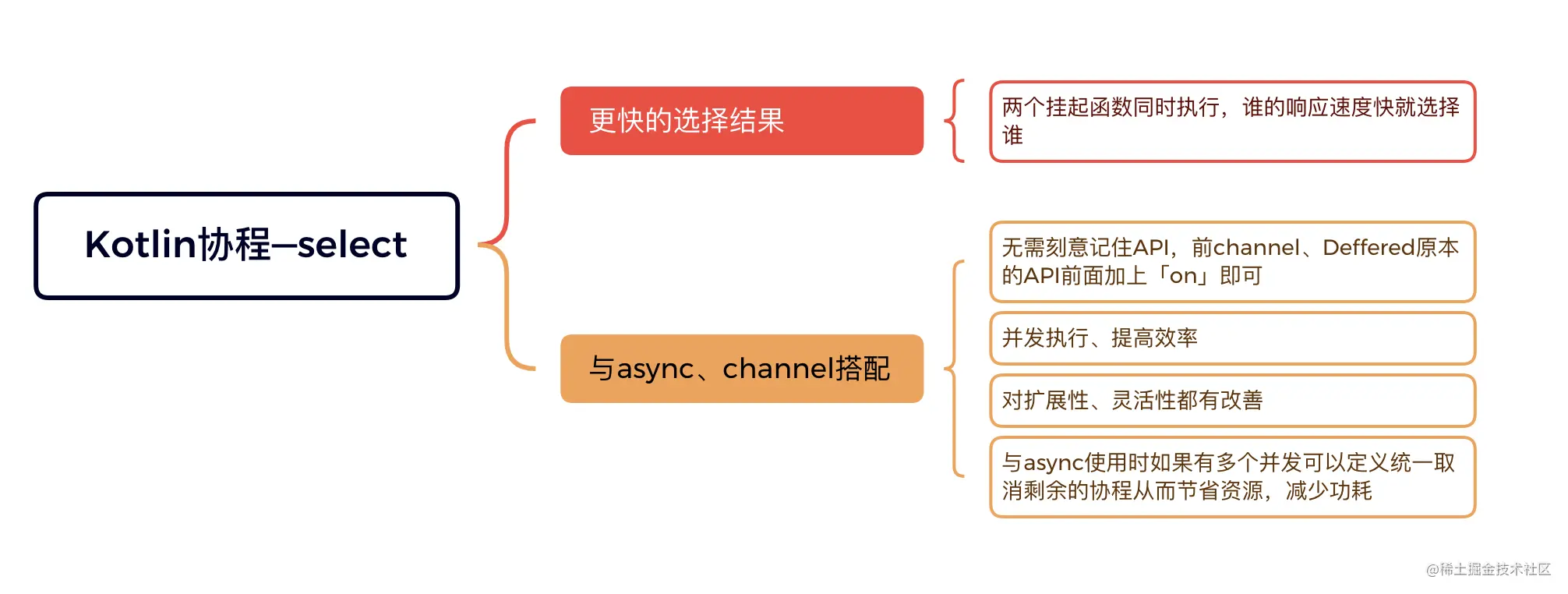
select在1.6的版本中还是一个实验性的特性,但是如果select与Deferred、Channel结合使用的话可以显著的提高程序运行的效率以及改善程序的灵活性和可扩展性。今天主要来聊一聊select的使用。
1.select就是选择「更快」的结果
举个例子,现在要获取用户信息进行展示,有缓存获取和网络请求获取两种方式,正常情况下缓存获取是最快的但是信息不一定是最新的,网络获取比前者慢但是确实最新的,他们的代码逻辑可以这么写:
fun main() = runBlocking {
val startTime = System.currentTimeMillis()
val cacheUserInfo = getCacheUserInfo("张三")
updateUI(cacheUserInfo)
println("cache 耗时:${(System.currentTimeMillis() - startTime)}")
val networkUserInfo = getNetworkUserInfo("李四")
updateUI(networkUserInfo)
println("network 耗时:${(System.currentTimeMillis() - startTime)}")
}
/**
* 从缓存获取用户信息
*/
suspend fun getCacheUserInfo(name: String): User {
delay(1000)
return User(name, 20)
}
/**
* 从网络获取用户信息
*/
suspend fun getNetworkUserInfo(name: String): User {
delay(1500)
return User(name, 44)
}
fun updateUI(user: User) {
println("${user.name}:${user.age}")
}
data class User(
val name: String,
val age: Int
)
//输出结果:
//张三:20
//cache 耗时:1011
//李四:44
//network 耗时:2515
上面代码流程是先从缓存中获取信息,再从网络连接中获取信息,主要分为四步:
- 第一步:查询缓存信息;
- 第二步:缓存服务返回信息,更新 UI;
- 第三步:查询网络服务;
- 第四步:网络服务返回信息,更新 UI。
但是上面这段代码是建立在缓存获取信息没有问题或者比网络请求快的前提下,假如说这里的缓存出现了超时的问题那么网络请求的函数是无法被执行的,因为getCacheUserInfo是一个挂起函数,它在没有被恢复的时候后面的函数是无法被执行的,这里假设缓存出现了超时情况,将getCacheUserInfo函数中的delay(1000)改为delay(2000),那输出的结果如下:
//输出结果
//张三:20
//cache 耗时:2005
//李四:44
//network 耗时:3511
看的出来networkUserInfo最终获取到的时间也会被延长,那么如果将getCacheUserInfo()和getNetworkUserInfo()两个函数的执行改为并行的话即使缓存出现问题用户信息也是可以正常获取的,只不过走的是网络请求:
fun main() = runBlocking {
val startTime = System.currentTimeMillis()
val cacheDeffered = async {
val cacheUserInfo = getCacheUserInfo("张三")
updateUI(cacheUserInfo)
println("cache 耗时:${(System.currentTimeMillis() - startTime)}")
}
val networkDeffered = async {
val networkUserInfo = getNetworkUserInfo("李四")
updateUI(networkUserInfo)
println("network 耗时:${(System.currentTimeMillis() - startTime)}")
}
}
//输出结果:
//李四:44
//network 耗时:1595
//张三:20
//cache 耗时:2085
从结果看的出来并行之后不存在getNetworkUserInfo被阻塞的情况,那么如果我想要的是这两种方式谁最先返回就用谁的数据呢要怎么实现,这里就进入倒了今天的主体:select。
2.select和async
用select将上面async实现并行的代码进行改造:
fun main() = runBlocking {
val startTime = System.currentTimeMillis()
val userInfo = select<User> {
async { getCacheUserInfo("张三") }
.onAwait { it } //这里是重点
async { getNetworkUserInfo("李四") }
.onAwait { it } //这里是重点
}
if(userInfo!=null){
updateUI(userInfo)
println("select 耗时:${(System.currentTimeMillis() - startTime)}")
}
}
这里首先使用 select 这个高阶函数包裹了两次查询的服务,同时传入了泛型参数 User,代表我们要选择的数据类型是 User,然后在async后面添加了onAwait { it },这里的目的是为了将结果传递给select,select才能将结果返回给变量并在后面更新UI。
至于它的输出结果其实就是根据谁先有响应就输出谁的结果,比如说缓存获取时间为delay(1000)网络请求时间为delay(1500)得到的结果就是缓存的响应, 反过来的话得到的结果就是网络请求的响应, 所以select的作用就是选择最快有响应的哪一个结果进行输出, 这样就避免了等待太长的时间,得到糟糕的体验。
这里还存在一个问题,就是如果缓存获取不出现问题,那么缓存的获取是一定会比网络请求快的,用了select之后每次获取到的信息都是旧的了,这里要怎么解决?解决这个问题其实就是加一个标识,这里我贴上完整代码:
/**
* 从缓存获取用户信息
*/
suspend fun getCacheUserInfo(name: String): User {
delay(1000)
return User(name, 20)
}
/**
* 从网络获取用户信息
*/
suspend fun getNetworkUserInfo(name: String): User {
delay(1500)
return User(name, 44)
}
fun updateUI(user: User) {
println("${user.name}:${user.age}")
}
data class User(
val name: String,
val age: Int,
val isCache: Boolean = false
)
fun main() = runBlocking {
val startTime = System.currentTimeMillis()
val cacheUserInfo = async { getCacheUserInfo("张三") }
val networkUserInfo = async { getNetworkUserInfo("李四") }
val userInfo = select<User> {
cacheUserInfo.onAwait { it?.copy(isCache = true) }
networkUserInfo.onAwait { it?.copy(isCache = false) }
}
if (userInfo != null) {
updateUI(userInfo)
println("select 耗时:${(System.currentTimeMillis() - startTime)}")
}
if (userInfo != null && userInfo.isCache) {
val network = networkUserInfo.await()?: return@runBlocking
updateUI(network)
println("network 耗时: ${System.currentTimeMillis() - startTime}")
}
}
//输出结果
//张三:20
//select 耗时:1057
//李四:44
//network 耗时: 1571
通过isCache这个标识,当获取的是缓存数据时要再进行网络数据的请求,这样缓存中的数据就是重视最新的了。
3.select和channel
前面在channel使用篇讲过,channel可以发送多条数据,假设这里有这样一个需求,后台下发一个任务,每执行一步都要先在屏幕上展示,再写入本地文件(这两件事可以做成一件,这里主要为了举例),只用channel来实现的话大概是这样:
fun main() = runBlocking {
val startTime = System.currentTimeMillis()
val channelUI = produce {
send("UI展示:任务启动")
delay(100)
send("UI展示:任务执行")
delay(100)
send("UI展示:任务终止")
delay(100)
}
val channelFile = produce {
send("写入文件:任务启动")
delay(100)
send("写入文件:任务执行")
delay(100)
send("写入文件:任务终止")
delay(100)
}
channelUI.consumeEach{
println(it)
}
channelFile.consumeEach{
println(it)
}
println("耗时: ${System.currentTimeMillis() - startTime}")
}
//输出结果
//UI展示:任务启动
//UI展示:任务执行
//UI展示:任务终止
//写入文件:任务启动
//写入文件:任务执行
//写入文件:任务终止
//耗时: 686
从输出结果可以看到好像是实现这个需求,但是写入文件的操作是在UI展示完成后才开始执行,那么加入UI展示有很多呢?是不是就意味着写入文件这一操作什么时候执行也不知道了。
如果用select实现会是怎么样的结果呢:
fun main() = runBlocking {
val startTime = System.currentTimeMillis()
val channelUI = produce {
send("UI展示:任务启动")
delay(100)
send("UI展示:任务执行")
delay(100)
send("UI展示:任务终止")
delay(100)
}
val channelFile = produce {
send("写入文件:任务启动")
delay(100)
send("写入文件:任务执行")
delay(100)
send("写入文件:任务终止")
delay(100)
}
//1
repeat(6) {
selectChannel(channelUI, channelFile)
}
println("耗时: ${System.currentTimeMillis() - startTime}")
}
suspend fun selectChannel(
channelUI: ReceiveChannel<String>,
channelFile: ReceiveChannel<String>
):String = select<String>{
//2
channelUI.onReceive{ it.also { println(it) } }
channelFile.onReceive{ it.also { println(it) } }
}
//输出结果
//UI展示:任务启动
//写入文件:任务启动
//UI展示:任务执行
//写入文件:任务执行
//UI展示:任务终止
//写入文件:任务终止
//耗时: 400
先对上面的几个注释进行说明:
- 注释1:执行6次,链各个管道中各有3条数据,执行6次的主要目的是将管道中的数据全部消耗掉;
- 注释2:
onReceive{}是Channel在select当中的语法,当Channel当中有数据以后,它就会被回调,通过这个 Lambda,我们也可以将结果传出去
前后两种方式的执行结果对比可以发现,select的实现比Channel的实现耗费的时间更少,并且他们是交替执行的。那么此时如果channelUI遇到问题了channelFile是否会执行呢?
fun main() = runBlocking {
val startTime = System.currentTimeMillis()
val channelUI = produce<String> {
delay(100000)
}
val channelFile = produce {
send("写入文件:任务启动")
delay(100)
send("写入文件:任务执行")
delay(100)
send("写入文件:任务终止")
delay(100)
}
repeat(6) {
selectChannel(channelUI, channelFile)
}
println("耗时: ${System.currentTimeMillis() - startTime}")
}
suspend fun selectChannel(channelUI: ReceiveChannel<String>, channelFile: ReceiveChannel<String>):String = select<String>{
channelUI.onReceive{ it.also { println(it) } }
channelFile.onReceive{ it.also { println(it) } }
}
//输出结果
//写入文件:任务启动
//写入文件:任务执行
//写入文件:任务终止
//Exception in thread "main" kotlinx.coroutines.channels.ClosedReceiveChannelException: Channel was closed
可以看到这里正常的输出了channelFile的数据,这说明select加入后即使另一个管道没有数据也不会影响整个任务的执行。
在输出结果的同时还爆出了一个错误,这个错误的原因是,channel中只有三个数据,当他们发送完毕后就被关闭了,而第4次调用时因为channel已经被关闭了所以爆出了这个错误,如果把【6】改成【3】这个错误就不会出现了。但是在这个需求中并不知道具体有多少数据,那要解决这个问题就要使用onReceiveCatching{}了。
fun main() = runBlocking {
val startTime = System.currentTimeMillis()
val channelUI = produce<String> {
delay(100000)
}
val channelFile = produce {
send("写入文件:任务启动")
delay(100)
send("写入文件:任务执行")
delay(100)
send("写入文件:任务终止")
delay(100)
}
repeat(6) {
val result = selectChannel(channelUI, channelFile)
//打印结果
println(result)
}
println("耗时: ${System.currentTimeMillis() - startTime}")
}
suspend fun selectChannel(channelUI: ReceiveChannel<String>, channelFile: ReceiveChannel<String>):String = select<String>{
//这里做了改动
channelUI.onReceiveCatching{ it.getOrNull() ?: "channelUI is closed!" }
channelFile.onReceiveCatching{it.getOrNull() ?: "channelFile is closed!" }
}
//输出结果
//写入文件:任务启动
//写入文件:任务执行
//写入文件:任务终止
//channelFile is closed!
//channelFile is closed!
//channelFile is closed!
//耗时: 442
这时候,即使不知道管道里有多少个数据,我们也不用担心崩溃的问题了。在 onReceiveCatching{} 这个高阶函数当中,我们可以使用 it.getOrNull() 来获取管道里的数据,如果获取的结果是 null,就代表管道已经被关闭了。不过,上面的代码仍然还有一个问题,那就是,得到所有结果以后,程序不会立即退出,因为我们的 channelUI 一直在 delay()。这时候,完成 6 次repeat()调用以后,将 channelUI、channelFile 取消即可。
//在repeat()后添加即可
channelUI.cancel()
channelFile.cancel()
4.select和channel、Deffered之间的联系
通过前面的分析可以发现,当select加入后,它们原本的 API 会多一个 on 前缀。
所以,只要记住了 Deferred、Channel 的 API,你是不需要额外记忆 select 的 API 的,只需要在原本的 API 的前面加上一个 on 就行了。另外还要注意的是,当 select 与 Deferred 结合使用的时候,当并行的 Deferred 比较多的时候,你往往需要在得到一个最快的结果以后,去取消其他的 Deferred。
比如说,对于 Deferred1、Deferred2、Deferred3、Deferred4、Deferred5,其中 Deferred2 返回的结果最快,这时候,我们往往会希望取消其他的 Deferred,以节省资源。那么在这个时候,我们可以使用类似这样的方式:
fun main() = runBlocking {
suspend fun <T> fastest(vararg deferreds: Deferred<T>): T = select {
fun cancelAll() = deferreds.forEach { it.cancel() }
for (deferred in deferreds) {
deferred.onAwait {
cancelAll()
it
}
}
}
val deferred1 = async {
delay(100L)
println("done1") // 没机会执行
"result1"
}
val deferred2 = async {
delay(50L)
println("done2")
"result2"
}
val deferred3 = async {
delay(10000L)
println("done3") // 没机会执行
"result3"
}
val deferred4 = async {
delay(2000L)
println("done4") // 没机会执行
"result4"
}
val deferred5 = async {
delay(14000L)
println("done5") // 没机会执行
"result5"
}
val result = fastest(deferred1, deferred2, deferred3, deferred4, deferred5)
println(result)
}
/*
输出结果
done2
result2
*/
5.总结
- select,就是选择“更快的结果”。
- 当 select 与 async、Channel 搭配以后,可以并发执行协程任务,以此大大提升程序的执行效率甚至用户体验,并且还可以改善程序的扩展性、灵活性。
- 关于 select 的 API,不需要去刻意记忆,只需要在 Deferred、Channel 的 API 基础上加上 on 这个前缀即可。
作者:无糖可乐爱好者
链接:https://juejin.cn/post/7181792189532831801
最后
如果想要成为架构师或想突破20~30K薪资范畴,那就不要局限在编码,业务,要会选型、扩展,提升编程思维。此外,良好的职业规划也很重要,学习的习惯很重要,但是最重要的还是要能持之以恒,任何不能坚持落实的计划都是空谈。
如果你没有方向,这里给大家分享一套由阿里高级架构师编写的《Android八大模块进阶笔记》,帮大家将杂乱、零散、碎片化的知识进行体系化的整理,让大家系统而高效地掌握Android开发的各个知识点。
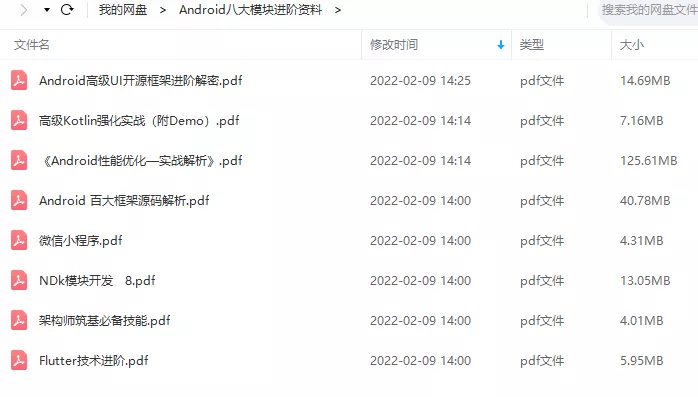
相对于我们平时看的碎片化内容,这份笔记的知识点更系统化,更容易理解和记忆,是严格按照知识体系编排的。
全套视频资料:
一、面试合集
二、源码解析合集
三、开源框架合集

欢迎大家一键三连支持,若需要文中资料,直接点击文末CSDN官方认证微信卡片免费领取↓↓↓















 529
529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









