






前言
这是大模型面试里针对 Flash Attention 的一个面试连环炮,如果你能全部答出,至少能淘汰 80% 的面试竞争者。
本文我将从面试官视角,详细拆解这些题目,如果你正在准备大模型面试,也可以尝试着回答一下,看能够撑到第几关?
问题一:Self Attention是怎么计算的,写出对应的公式
面试官心理分析
第一个问题一般不难,上来先热身。面试官问这个问题,主要是考察我们 Self Attention 公式,以及解释一下关键参数的涵义。
所以这里按要求写出公式就 OK 了,标准的 Self-Attention 公式如下图:
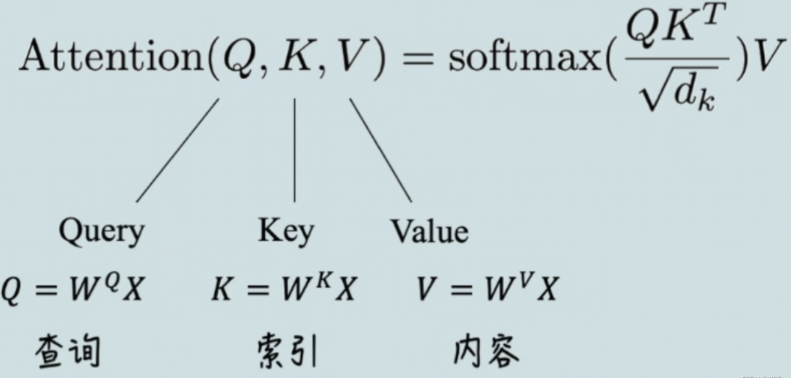
其中 Q,K,V 都是 N * dk 的 2D 矩阵,N 为序列长度,dk 为头的维度。
问题二:接下来面试官可能会继续追问:按照 softmax 公式的计算有什么问题,一般在工程实现的时候是怎么做的呢?
面试官心理分析
面试官问这个问题,主要是想看看你是否在实际工程中有用到并思考过这个问题。
我们知道,标准的 softmax 公式如下图:
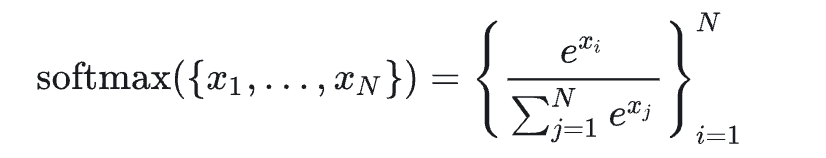
因为包含了幂指数计算,所以它有一个明显的问题:数值溢出。对于大模型常用的半精度 fp16 来说,最大值也才 65536,所以当 xi 大于 11 的时候,e 的 12 次方等于 162754.7914 ,大于 65536。
所以实际工程实现相对于原生的 softmax,它先要减去一个 max 的值,确保计算过程中不会导致数值溢出,如下图:
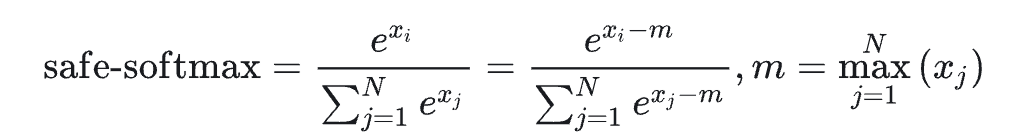
由于 xi-m ≤0 所以不会出现溢出,这种实现方案也叫 safe-softmax。
所以总结一下,对于这个问题,我们要沿着面试官的心理,首先答出标准 softmax 公式导致的问题:数值溢出。
再回答实际工程的解决方案:safe-softmax,并结合相应的公式进行回答。
此外对于标准的 softmax 计算,需要 3 步,计算最大值 m,计算分母,最后再依此计算分子。
所以如果不做任何优化的话,它至少要和 GPU 进行 6 次通信(3 次写入,3 次写出)。
问题三:所以这里我们自然就引出了下一个问题:那你能够降低 softmax 的 GPU 访存复杂度吗?如果可以,怎么做?
面试官心理分析
这个问题面试官希望你回答什么呢?其实就两点,第一,你知不知道 softmax 可以通过流式计算降低 GPU 访存复杂度。第二,能否阐述一下流式计算的核心思想。
首先我们明确一点,就是 softmax 是可以做成流式计算的,18 年 NVIDIA 发表的一篇论文,就提出了 online-softmax 算法,下图展示了其核心计算过程。

softmax 能做到流式计算,核心思想就是把 softmax 分母的计算做了一个优化,让它不依赖全局的最大值 mN,而是依赖局部的最大值 mi,这样就把前两个步骤合并成了一个。
所以最终我们可以借助 GPU 的 share memory 来存储中间结果,将上面的两步只用一个 kernel 实现,这样就只需要与 global memory 通信两次,一次写入数据,一次读取结果。
不过这里要注意,就是由于第二步的计算仍然需要依赖第一步计算的分母 dN,所以还是需要两步,换句话说,不能做成 one pass。
问题四:好,那下一个问题自然就来了:既然 softmax 不能做到 one-pass,为什么 Flash Attention 可以,解释一下背后的核心思想?
面试官心理分析
首先 Flash Attention 能做到 one-pass 计算,其核心思想是 Flash Attention 让 Attention 的所有计算都符合加法结合律,这样就可以充分利用 GPU 的并行优势,这是面试官希望我们答出的第一个点。
虽然单独的 softmax 运算不能做到 one-pass,但是 self-Attention 中的 softmax 求完之后,它的每一项的值会与 V 中向量相乘,然后累加。
这里的累加很关键,有了这个累加的操作,所有的计算又符合结合律了,这就是 FlashAttention 并行加速的的理论核心思想。如果没有这个累加,比如单纯的计算 softmax,反而没有办法并行。
所以用类似 Online Softmax 的方法,就可以将 Attention 所有的操作,都放到一个 for 循环里(一个 Kernel 就可以实现)。
我们可以推导一下输出的关系:
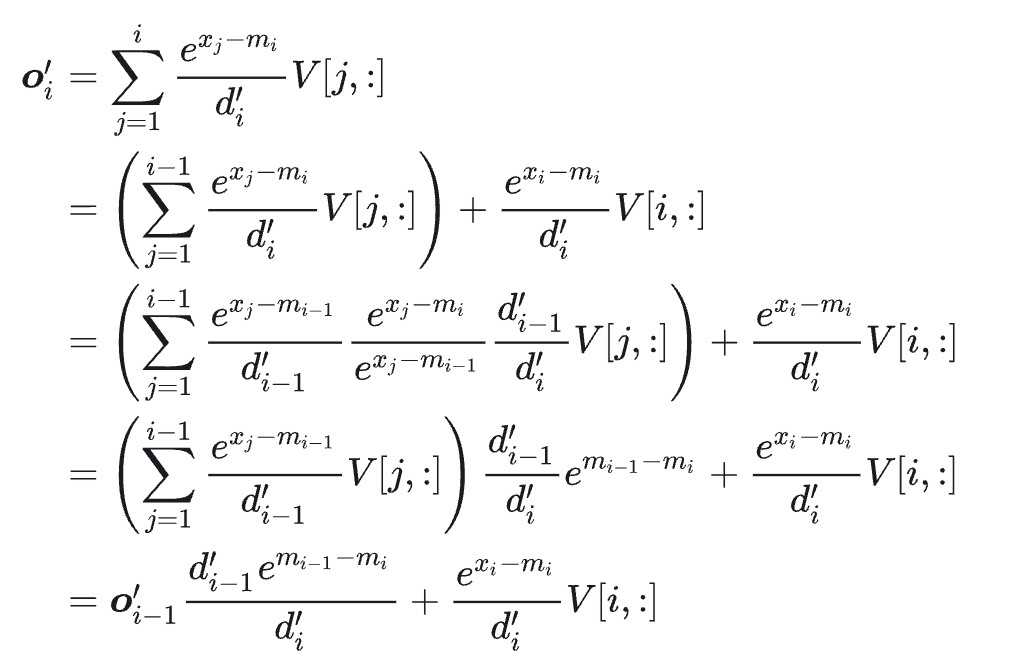
从上面式子可以看到,oi 只依赖 oi-1, mi, mi-1,所以可以实现递归计算。
更进一步,分析 Flash Attention 计算过程可以发现,Flash Attention 其实并没有减少 Attention 的计算量,也不影响精度,但是却比标准的 Attention 运算快 2~4 倍的运行速度,同时减少了 5~20 倍的内存使用量。
问题五:详细解释一下 Flash Attention 中的 tiling 策略?
面试官心理分析
面试官问这个问题,首先是想考察你,知不知道什么是 tiling,为什么要使用它?以及使用之后有什么作用?其次在 Flash Attention 中的 tiling 策略是如何做的,能否说一下它的整个流程以及具体的效果?
面试题解析
tiling 说白了就是对矩阵分块,分块策略的主要动机,是通过将大矩阵分解为更小的块,以此来减少内存访问的开销,同时提高计算效率。
分块策略允许我们在处理大矩阵时,只加载和处理一部分数据,而不是一次性加载整个矩阵,这样可以减少内存带宽的压力。
而具体到 Flash Attention 中,就是将 Q,K,V 分成更多个小块,其中 K,V 在外循环,Q 在内循环。在计算注意力分数的时候,通常需要进行 softmax 操作。
为了避免一次性计算整个 softmax,Flash Attention 会采用局部归一化策略。
对于每个块,我们只计算这个块内部的 softmax,并在累加结果的时候进行适当的归一化。
所以通过逐块计算,减少了全局内存的访问次数,这样就降低了内存带宽的压力。这种策略特别适用于处理长序列的注意力机制,能够显著加速计算过程。
问题六:FlashAttention 对 MQA 和 GQA 是怎么处理的?
面试官心理分析
面试官想考察的,首先是你是否知道 MQA 和 GQA,如果你都不知道这两个概念,这道题目也就无从答起。我们来看这张图。
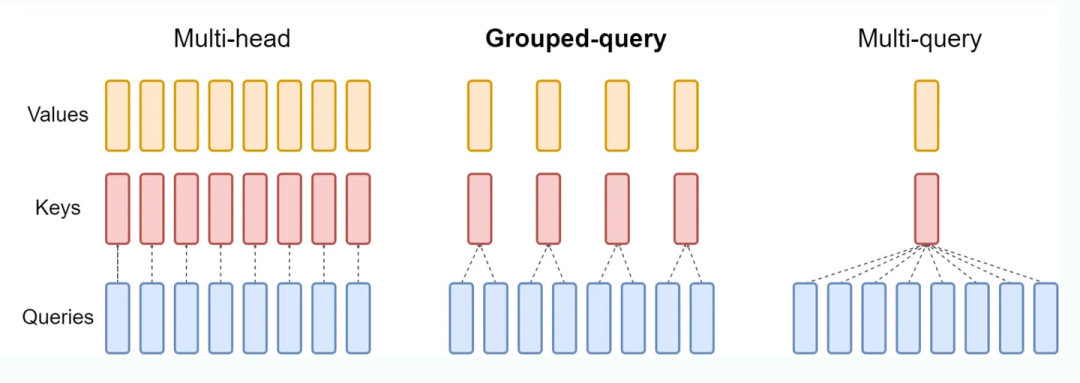
之前我们讲过,MQA 只保留了一个 KV Head,多个 Query Heads 共享相同的 KV Head。
而 GQA 与 MQA 不同,它采取了折中的做法,GQA 把 Query Heads 进行分组,每组 Query Heads 对应一个 KV Head。
举个例子,我们把 8 个 Query Heads 分成 4 组,每个 Group 包含 2 个 Query Heads,对应一个 KV Head 此时总共有 4 个 KV Heads。
问题七:那在 Flash Attention 中对 MQA/GQA 是如何处理呢?
这里面试官要听到的一个关键词,就是 Indexing 思想。对于 MQA 和 GQA,FlashAttention 采用了 Indexing 的方式,而不是直接复制多份 KV Head 的内容到显存然后再进行计算。
Indexing 的思想,就是通过传入 KV Head 索引到 GPU Kernel 中,然后根据内存地址,直接从内存中读取 KV。
最后
为了助力朋友们跳槽面试、升职加薪、职业困境,提高自己的技术,本文给大家整了一套涵盖AI大模型所有技术栈的快速学习方法和笔记。目前已经收到了七八个网友的反馈,说是面试问到了很多这里面的知识点。
由于文章篇幅有限,不能将全部的面试题+答案解析展示出来,有需要完整面试题资料的朋友,可以扫描下方二维码免费领取哦!!! 👇👇👇👇

面试题展示
1、请解释一下BERT模型的原理和应用场景。
答案:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,通过双向Transformer编码器来学习文本的表示。它在自然语言处理任务中取得了很好的效果,如文本分类、命名实体识别等。
2、什么是序列到序列模型(Seq2Seq),并举例说明其在自然语言处理中的应用。
答案:Seq2Seq模型是一种将一个序列映射到另一个序列的模型,常用于机器翻译、对话生成等任务。例如,将英文句子翻译成法文句子。
3、请解释一下Transformer模型的原理和优势。
答案:Transformer是一种基于自注意力机制的模型,用于处理序列数据。它的优势在于能够并行计算,减少了训练时间,并且在很多自然语言处理任务中表现出色。
4、什么是注意力机制(Attention Mechanism),并举例说明其在深度学习中的应用。
答案:注意力机制是一种机制,用于给予模型对不同部分输入的不同权重。在深度学习中,注意力机制常用于提升模型在处理长序列数据时的性能,如机器翻译、文本摘要等任务。
5、请解释一下卷积神经网络(CNN)在计算机视觉中的应用,并说明其优势。
答案:CNN是一种专门用于处理图像数据的神经网络结构,通过卷积层和池化层提取图像特征。它在计算机视觉任务中广泛应用,如图像分类、目标检测等,并且具有参数共享和平移不变性等优势。
6、请解释一下生成对抗网络(GAN)的原理和应用。
答案:GAN是一种由生成器和判别器组成的对抗性网络结构,用于生成逼真的数据样本。它在图像生成、图像修复等任务中取得了很好的效果。
7、请解释一下强化学习(Reinforcement Learning)的原理和应用。
答案:强化学习是一种通过与环境交互学习最优策略的机器学习方法。它在游戏领域、机器人控制等领域有广泛的应用。
8、请解释一下自监督学习(Self-Supervised Learning)的原理和优势。
答案:自监督学习是一种无需人工标注标签的学习方法,通过模型自动生成标签进行训练。它在数据标注困难的情况下有很大的优势。
9、解释一下迁移学习(Transfer Learning)的原理和应用。
答案:迁移学习是一种将在一个任务上学到的知识迁移到另一个任务上的学习方法。它在数据稀缺或新任务数据量较小时有很好的效果。
10、请解释一下模型蒸馏(Model Distillation)的原理和应用。
答案:模型蒸馏是一种通过训练一个小模型来近似一个大模型的方法。它可以减少模型的计算和存储开销,并在移动端部署时有很大的优势。
11、请解释一下LSTM(Long Short-Term Memory)模型的原理和应用场景。
答案:LSTM是一种特殊的循环神经网络结构,用于处理序列数据。它通过门控单元来学习长期依赖关系,常用于语言建模、时间序列预测等任务。
12、请解释一下BERT模型的原理和应用场景。
答案:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,通过双向Transformer编码器来学习文本的表示。它在自然语言处理任务中取得了很好的效果,如文本分类、命名实体识别等。
13、什么是注意力机制(Attention Mechanism),并举例说明其在深度学习中的应用。
答案:注意力机制是一种机制,用于给予模型对不同部分输入的不同权重。在深度学习中,注意力机制常用于提升模型在处理长序列数据时的性能,如机器翻译、文本摘要等任务。
14、请解释一下生成对抗网络(GAN)的原理和应用。
答案:GAN是一种由生成器和判别器组成的对抗性网络结构,用于生成逼真的数据样本。它在图像生成、图像修复等任务中取得了很好的效果。
15、请解释一下卷积神经网络(CNN)在计算机视觉中的应用,并说明其优势。
答案:CNN是一种专门用于处理图像数据的神经网络结构,通过卷积层和池化层提取图像特征。它在计算机视觉任务中广泛应用,如图像分类、目标检测等,并且具有参数共享和平移不变性等优势。
16、请解释一下强化学习(Reinforcement Learning)的原理和应用。
答案:强化学习是一种通过与环境交互学习最优策略的机器学习方法。它在游戏领域、机器人控制等领域有广泛的应用。
17、请解释一下自监督学习(Self-Supervised Learning)的原理和优势。
答案:自监督学习是一种无需人工标注标签的学习方法,通过模型自动生成标签进行训练。它在数据标注困难的情况下有很大的优势。
18、请解释一下迁移学习(Transfer Learning)的原理和应用。
答案:迁移学习是一种将在一个任务上学到的知识迁移到另一个任务上的学习方法。它在数据稀缺或新任务数据量较小时有很好的效果。
19、请解释一下模型蒸馏(Model Distillation)的原理和应用。
答案:模型蒸馏是一种通过训练一个小模型来近似一个大模型的方法。它可以减少模型的计算和存储开销,并在移动端部署时有很大的优势。
20、请解释一下BERT中的Masked Language Model(MLM)任务及其作用。
答案:MLM是BERT预训练任务之一,通过在输入文本中随机mask掉一部分词汇,让模型预测这些被mask掉的词汇。
由于文章篇幅有限,不能将全部的面试题+答案解析展示出来,有需要完整面试题资料的朋友,可以扫描下方二维码免费领取哦!!! 👇👇👇👇




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









