






前言
在之前我制作了几个 RAG,但都是吃文字吐文字的。一想到我的 RAG 只能看到冰冷的文字,而看不到类似猫娘的图片时,我就替 AI 感到惋惜。
那么本文就手把手制作一个能吃图片的 RAG,打造一个能够进行图像检索的 RAG。
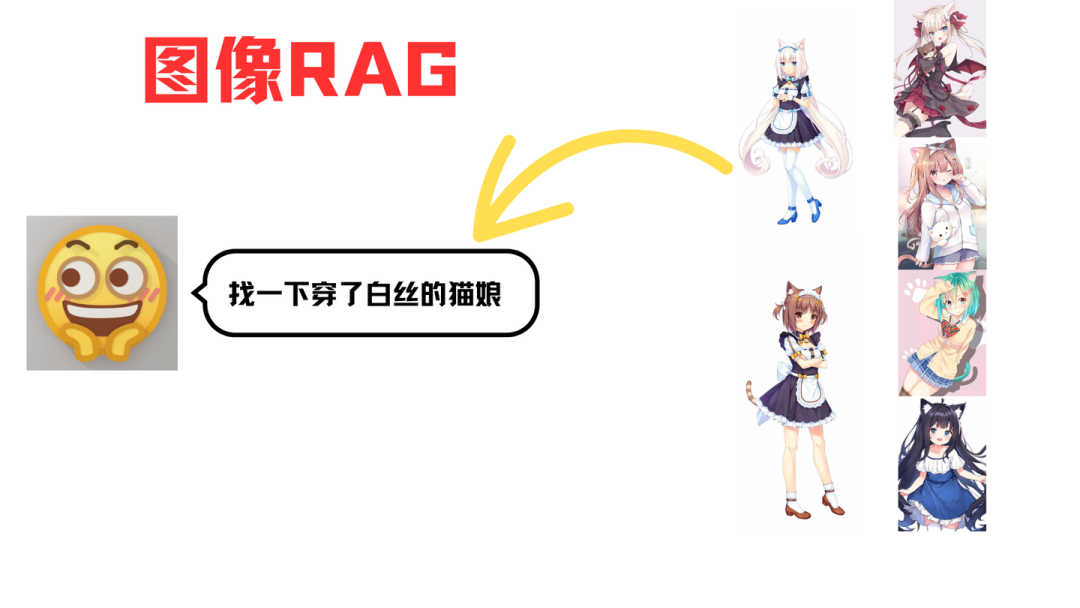
既然可以检索图片,那么不失一般性地,我们可以用这玩意挑选符合我们要求的猫娘(doge)。
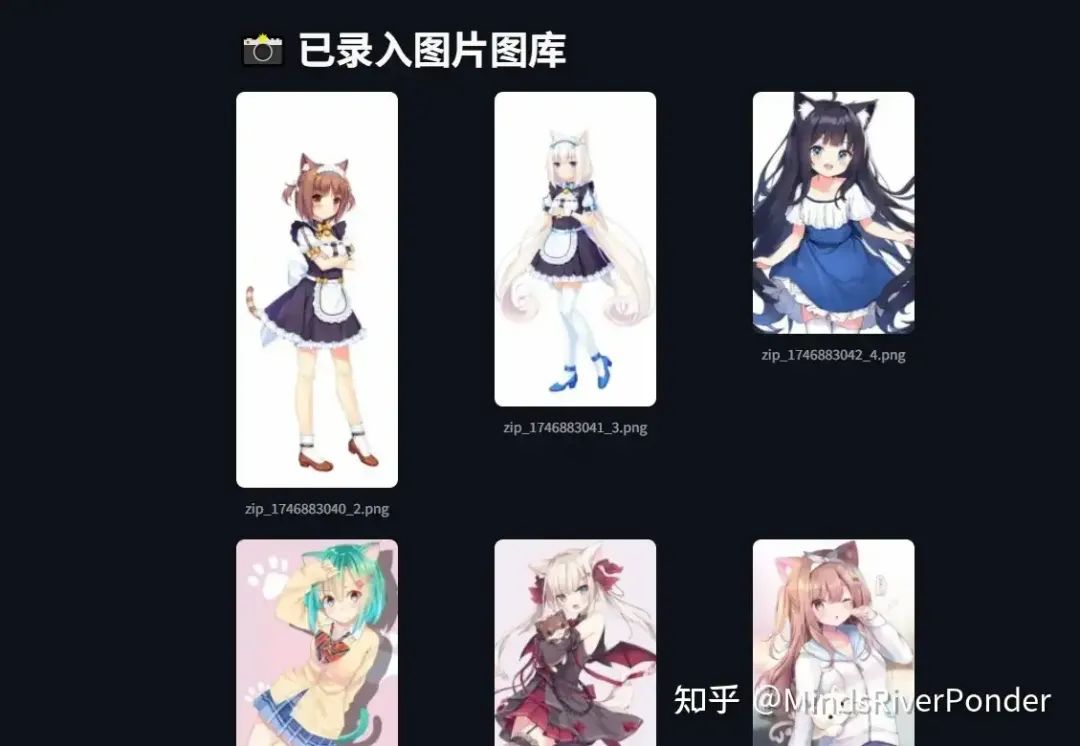
先来看一看最后的效果,我制作了页面。首先,我已经把这些猫娘的图片上传到系统里面了。
我现在描述一下我喜欢的猫娘类型,之后点击“检索并回答”。

它返回的结果如下:(原图有点长)

这个还真的很符合咱们的要求咧(手动傲娇)。上面这个图片太长了,猫娘上方的文字回复如下所示:

为了避免偶然性,提高准确性,我们再测试一番:

结果如下:


都说了大模型看人很准吧(叉腰)。
但是当我们尝试问一些与所有图片都无关的内容时:

我们会直接调用 Qwen3-235b-a22b 进行回答。


01、涉及的一些主要模型
(1)将图片转化为向量表示
为了判断一张图片是否与用户的提问匹配,我们会把图片和提问都映射到同一个“语义空间”中,得到各自的向量表示。
在这个空间里,语义相近的内容对应的向量距离会更小,然后,只需用常见的相似度度量(例如余弦相似度)来计算两者向量的相似度,就能快速评估提问与图片之间的匹配程度。
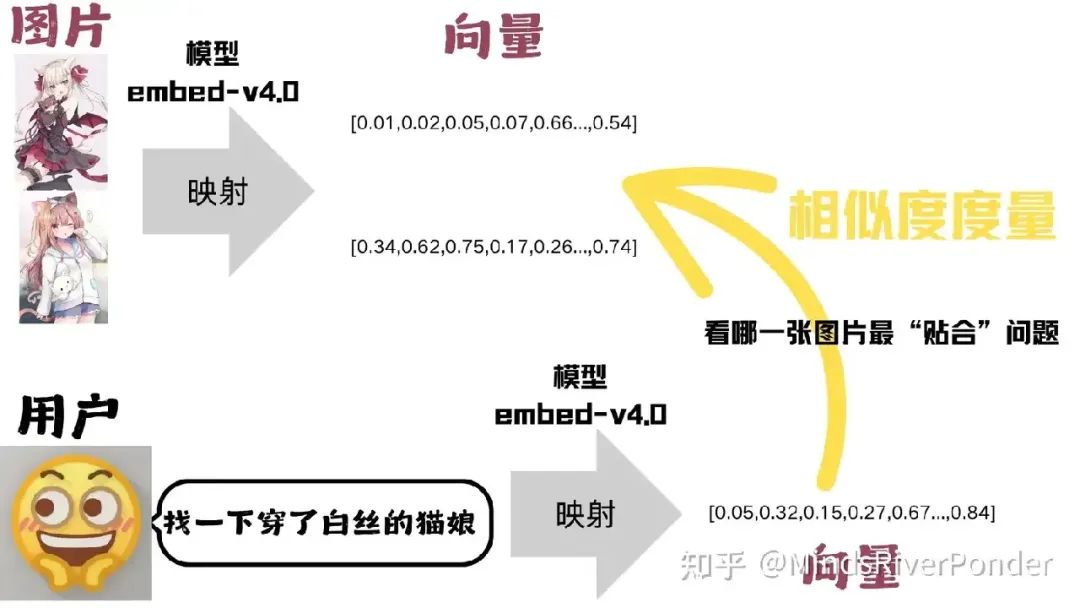
能够同时处理文字和图片,我们得找一个多模态的向量嵌入模型,我们选择 cohere 的 embed-v4.0 模型。
Cohere 的 embed-v4.0 是一款面向企业级检索和智能代理的多模态嵌入模型,能够直接对文本、图片以及混合的文档(如 PDF 页面)生成高质量向量表示,适合构建大规模、低延迟的语义检索和 RAG 系统。
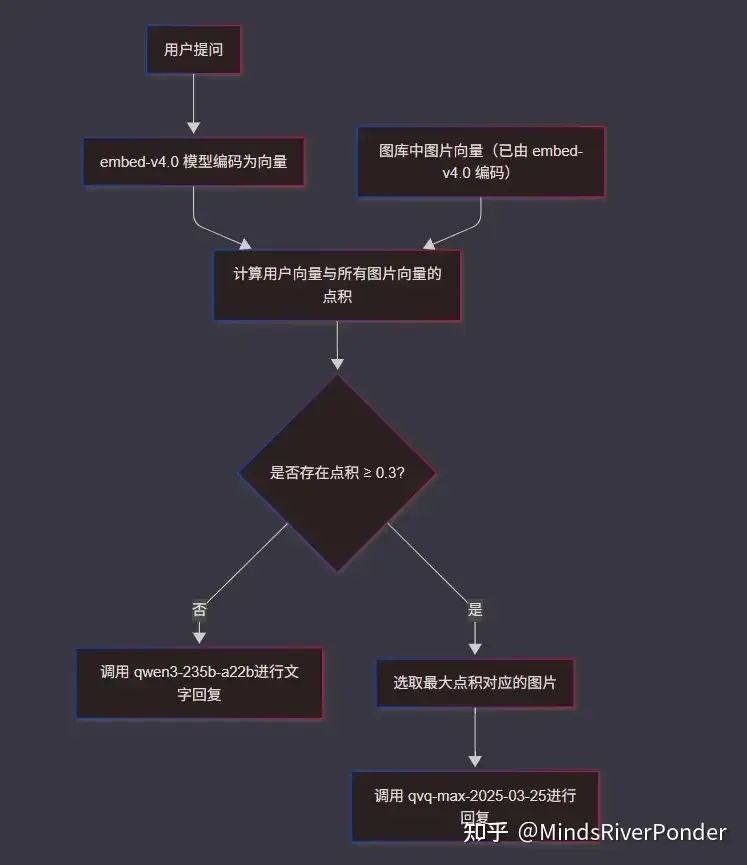
(2)本项目执行流程图
一开始,用户提问,用户的提问会被 embed-v4.0 模型编码为向量表示,(图库中的图片均已经被 embed-v4.0 编码为向量表示),将用户的提问与图库中的所有图片(的向量)作点积。
如果所有点积小于相似度阈值(0.3),则直接调用 qwen3-235b-a22b 进行文字回复,如果有点积大于相似度阈值(0.3),则选取点积最大所对应的图片,将图片传入 qvq-max-2025-03-25 进行回复。
qwen3-235b-a22b 能吃文字,如果这个模型是多模态的该多好。
qvq-max-2025-03-25 能吃图片:
02、代码讲解
https://github.com/mindsRiverPonder/LLM-practice/tree/main/image-RAG%20for%20catgirl
(1)下载并引入必要的库
其中 streamlit 是用来构建可视化页面的:
!pip install -q cohere streamlit
引入必要的库:
import osimport ioimport timeimport zipfile #解压缩用的import base64import requestsimport numpy as npimport PIL.Imageimport streamlit as stfrom openai import OpenAIimport cohere
(2)配置可视化页面的 css 样式(可跳过)
css 样式你可以选择自己设计(强烈推荐),让画面变得更好看。我就不摆出我的 css 样式设计了,毕竟是依托勾式。
st.markdown( """ <style> 自己设计哈</style> """ , unsafe_allow_html=True)
(3)配置对于的 API-key,初始化客户端
为了使用图像嵌入模型 embed-v4.0,你需要先去 cohere 官网申请一个免费的 API-KEY(那肯定是有速率限制的)。
https://dashboard.cohere.com/api-keys
为了使用 qwen3-235b-a22b 和 qvq-max-2025-03-25,你需要先去阿里云百炼官网申请一个 API-KEY。
https://bailian.console.aliyun.com/?tab=model#/model-market
COHERE_API_KEY = os.getenv("COHERE_API_KEY", "你的API-KEY")DASHSCOPE_API_KEY = os.getenv("DASHSCOPE_API_KEY", "你的API-KEY")EMBED_MODEL = "embed-v4.0"QUERY_MODEL = "qwen3-235b-a22b"VISION_MODEL = "qvq-max-2025-03-25"def init_clients(): co = cohere.ClientV2(api_key=COHERE_API_KEY) qwen_client = OpenAI( api_key=DASHSCOPE_API_KEY, base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) return co, qwen_clientco, qwen_client = init_clients()
(4)定义一些必要的工具函数
这个相似度阈值,你们可以根据需要进行调整,调高一些就代表检索图片更严格。
MAX_PIXELS = 1568 * 1568 #图片最大像素SIM_THRESHOLD = 0.3 # 相似度阈值,可根据需要调整
1.调整图像尺寸,当超过最大像素时自动缩小。
def resize_image(pil_image: PIL.Image.Image): w, h = pil_image.size if w * h > MAX_PIXELS: scale = (MAX_PIXELS / (w * h)) ** 0.5 pil_image.thumbnail((int(w * scale), int(h * scale)))
2.将图像转化为 Base64 编码,很多 API 都要求图像以 Base64 编码的字符串形式传输。
def base64_from_pil(pil_image: PIL.Image.Image) -> str: fmt = pil_image.format or "PNG" resize_image(pil_image) with io.BytesIO() as buf: pil_image.save(buf, format=fmt) data = base64.b64encode(buf.getvalue()).decode() return f"data:image/{fmt.lower()};base64,{data}"
3.通过 embed-v4.0 生成图像的嵌入向量,并且归一化向量,便于计算余弦相似度。
def embed_document(img: PIL.Image.Image): b64 = base64_from_pil(img) doc_in = {"content": [{"type": "image", "image": b64}]} resp = co.embed(model=EMBED_MODEL, input_type="search_document", embedding_types=["float"], inputs=[doc_in]) vec = np.array(resp.embeddings.float[0]) return vec / np.linalg.norm(vec) #归一化
4.将用户的输入也映射为向量,便于检索相关图片
def embed_query(text: str): resp = co.embed(model=EMBED_MODEL, input_type="search_query", embedding_types=["float"], texts=[text]) vec = np.array(resp.embeddings.float[0]) return vec / np.linalg.norm(vec)
(5)模型生成回复
因为我这里用的是 qwen3-235b-a22b 和 qvq-max-2025-03-25,他们支持流式输出,我在页面上也流式展示回复的内容。
def generate_answer(question: str, img: PIL.Image.Image = None): """流式输出""" if img is not None: b64_image = base64_from_pil(img) messages = [ {"role": "system", "content": "根据下面的图片回答问题。"}, { "role": "user", "content": [ {"type": "text", "text": question}, {"type": "image_url", "image_url": {"url": b64_image}} ] }] response = qwen_client.chat.completions.create( model=VISION_MODEL, messages=messages, stream=True, # 启用流式输出 ) else: # 处理纯文本输入 messages = [ {"role": "system", "content": "请仅根据文字问题回答"}, {"role": "user", "content": question} ] response = qwen_client.chat.completions.create( model=QUERY_MODEL, messages=messages, stream=True, # 启用流式输出 ) def stream_response(): try: for chunk in response: if chunk.choices[0].delta.content: yield chunk.choices[0].delta.content except Exception as e: st.error(f"流式输出错误: {str(e)}") yield "抱歉,流式输出过程中发生错误。" return stream_response()
(6)定义存储上传图片路径和对应的嵌入向量的地方
if 'img_paths' not in st.session_state: st.session_state.img_paths = []if 'doc_embeddings' not in st.session_state: st.session_state.doc_embeddings = []
(7)页面搭建
st.sidebar.title("导航栏")
page = st.sidebar.radio("功能", ["查询", "上传", "图库"], index=0)
if page == "上传":
st.header("上传图片资源")
uploaded = st.file_uploader("上传单张图片", type=['png','jpg','jpeg'])
url = st.text_input("或输入图片 URL")
zipf = st.file_uploader("上传 ZIP 压缩包 (仅图片)", type=['zip'])
if uploaded:
img = PIL.Image.open(uploaded)
path = f"uploaded_{int(time.time())}.png"
img.save(path)
st.session_state.img_paths.append(path)
st.session_state.doc_embeddings.append(embed_document(img))
st.success(f"已添加: {path}")
if url:
try:
r = requests.get(url)
r.raise_for_status() img = PIL.Image.open(io.BytesIO(r.content)) path = f"url_{int(time.time())}.png" img.save(path) st.session_state.img_paths.append(path) st.session_state.doc_embeddings.append(embed_document(img)) st.success(f"已下载并添加成功: {path}") except Exception as e: st.error(f"URL 下载失败 : {e}") if zipf: with zipfile.ZipFile(zipf) as z: for fname in z.namelist(): if fname.lower().endswith(('.png','.jpg','.jpeg')): data = z.read(fname) img = PIL.Image.open(io.BytesIO(data)) path = f"zip_{int(time.time())}_{os.path.basename(fname)}" img.save(path) st.session_state.img_paths.append(path) st.session_state.doc_embeddings.append(embed_document(img)) st.success("ZIP 中的所有图片已添加")elif page == "查询": st.header(" 图像RAG-文字检索图片") question = st.text_input("请输入您的问题✍️:") if st.button("检索并回答"): if not question: st.warning("请输入问题后再检索 ") else: q_emb = embed_query(question) if st.session_state.doc_embeddings: docs = np.vstack(st.session_state.doc_embeddings) sims = docs.dot(q_emb) max_sim = float(np.max(sims)) idx = int(np.argmax(sims)) else: max_sim = 0 answer_container = st.empty() full_answer = "" # 判断是否命中 if max_sim < SIM_THRESHOLD: # 文字回答流式渲染 ans_generator = generate_answer(question) for token in ans_generator: full_answer += token answer_container.markdown(f"**模型文字回答(无相关图片):** {full_answer}") else: # 显示图片 best = st.session_state.img_paths[idx] img = PIL.Image.open(best) st.image(img, caption=f"最相关图片(相关度:{max_sim:.2f})", use_column_width=True) # 图文回答流式渲染 ans_generator = generate_answer(question, img) for token in ans_generator: full_answer += token answer_container.markdown(f"**模型回答:** {full_answer}")elif page == "图库": st.header(" 已录入图片图库") paths = st.session_state.img_paths if not paths: st.info("""啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊!宝宝肚肚打雷啦 。""") st.info("""一张图片都没有**❗️请先在“上传”页面添加图片❗️**""") st.info("""啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊!""") else: for i in range(0, len(paths), 3): cols = st.columns(3) for j, path in enumerate(paths[i:i+3]): with cols[j]: img = PIL.Image.open(path) st.image(img, width=150, caption=os.path.basename(path))
03
注意事项
(1)使用前-上传图片
想要检索图片,你先得上传图片,我这里支持 3 种上传方式:
- 上传单张图片
- 输入图片的 url 进行自动下载
- 把一大堆图片放进 zip 压缩包里,上传后台自动处理

(2)各种库的版本
要是出现问题,大概率是库版本对不上。我曾经在一个项目里把 numpy 升级到了 2.0+ 版本,整个项目瘫痪,赶紧换回以前的版本(悲)。
Python 版本: 3.11.12requests 版本: 2.32.3numpy 版本: 2.0.2PIL/Pillow 版本: 11.2.1streamlit 版本: 1.45.0openai 版本: 1.76.0cohere 版本: 5.15.0
(3)非本地运行方法(colab)
如果你想在 colab 上直接运行,可以参考我以前的文章:
https://zhuanlan.zhihu.com/p/30771092833
(4)正确使用
这是一个图像检索 RAG,不是猫娘 RAG,不要局限于猫娘啦。
(5)模型选用
如果你不想用文中的模型,都可以换,注意把 base_url 和 api key 给换了,此外,还要查看对应的 API 调用示例。
04、可优化的点
1.我想到一个功能,让用户输入一个关键词,后台自动去下载对应的图片,bing-image-downloader 这个库估计挺合适。简单来说,爬虫。
2.如果本项目不用于猫娘检索,可以用 gemini 代替 Qwen3-235b-a22b 和 qvq-max-2025-03-25,因为 gemini 很容易把动漫角色给 block 掉。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









