






01、Token Sequence Compression for Efficient Multimodal Computing
大型多模态模型(LMMs)的指数级增长推动了跨模态推理的发展,但带来了巨大的计算成本。本文聚焦于视觉语言模型,指出当前视觉编码器的冗余和低效,并试图构建一种自适应的多模态数据压缩方法。本文通过基准测试和定性分析,对多种视觉令牌选择和合并方法进行了研究,特别指出简单的聚类级令牌聚合在视觉令牌选择和合并方面优于以往的最先进工作,包括在视觉编码器级别进行合并和基于注意力的方法。本文强调了当前视觉编码器的冗余性,并揭示了通过跨模态注意力可视化发现的关于视觉令牌选择原则的几个令人困惑的趋势。这项工作是首次尝试更有效地编码和处理高维数据,为更可扩展和可持续的多模态系统铺平了道路。
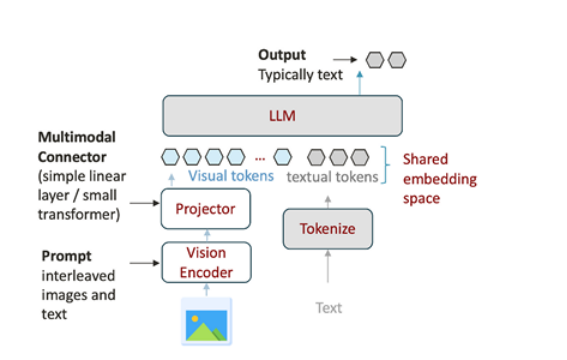
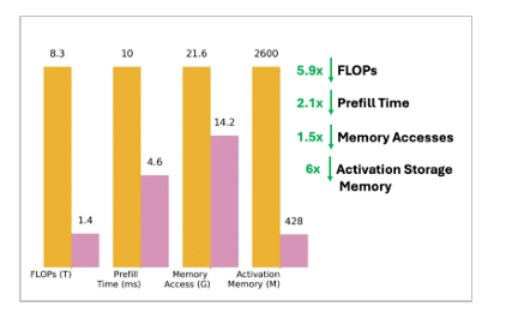

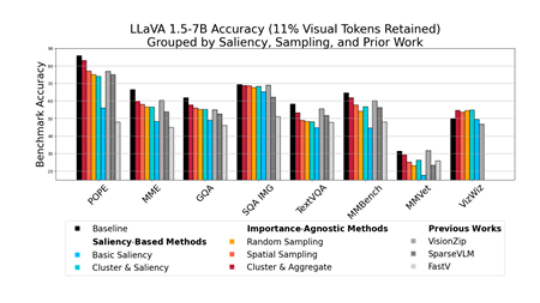

02、Backslash: Rate Constrained Optimized Training of Large Language Models
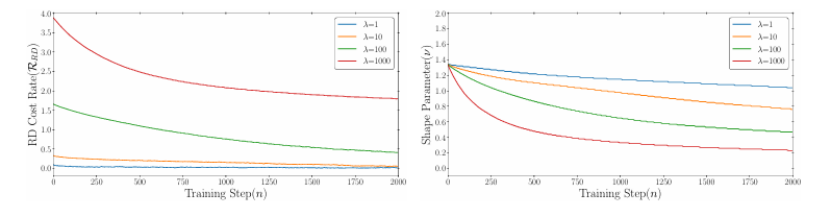
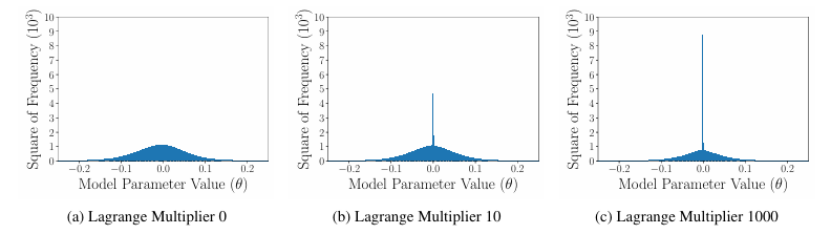
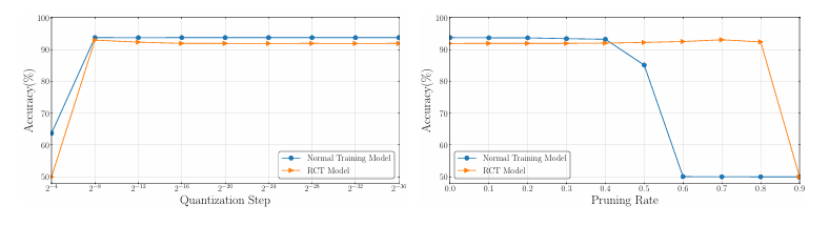
大型语言模型(LLMs)的快速发展推动了对训练完成后参数压缩的广泛研究,然而在训练阶段的压缩仍然鲜有探索。本文介绍了一种基于速率失真优化(RDO)的训练时压缩方法,称为Backslash。Backslash能够在模型准确性和复杂性之间实现灵活的权衡,在保留性能的同时显著减少参数冗余。在多种架构和任务中的实验表明,Backslash可以在不损失准确性的前提下将内存使用量减少60% - 90%,并且与训练后的压缩相比具有显著的压缩增益。此外,Backslash具有高度的通用性:它可以通过使用较小的拉格朗日乘数来增强泛化能力,提高模型对剪枝的鲁棒性(即使在80%的剪枝率下也能保持准确性),并且能够简化网络以加速边缘设备上的推理。
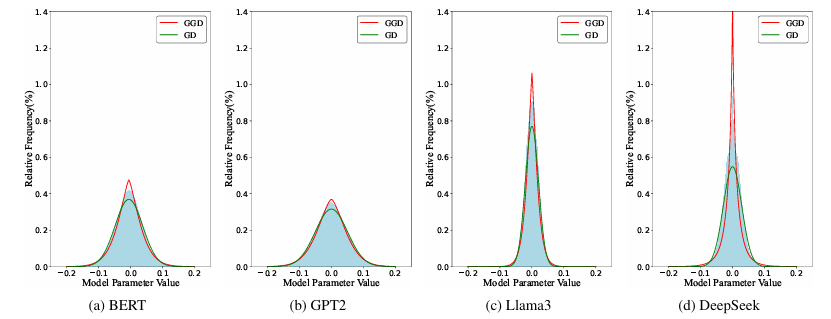

03、We’ll Fix it in Post: Improving Text-to-Video Generation with Neuro-Symbolic Feedback
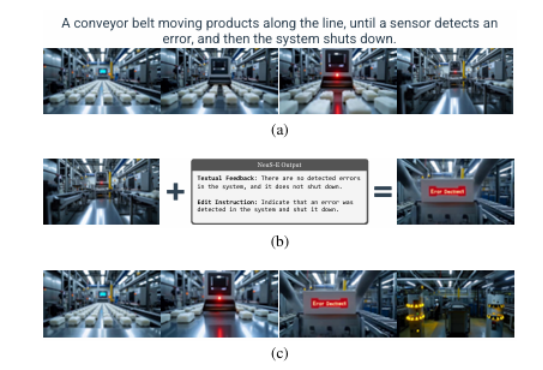
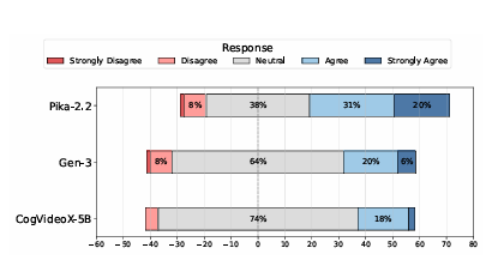
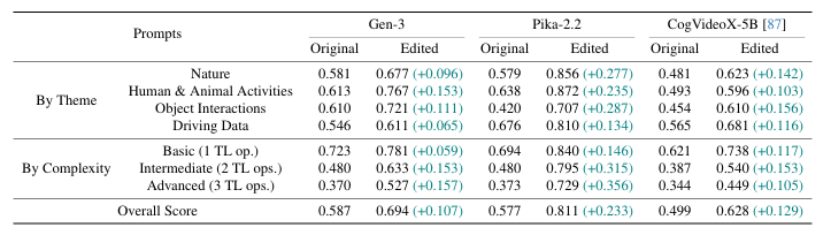
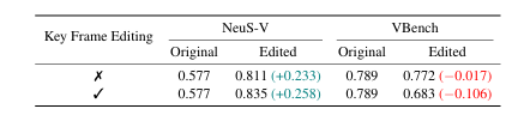
当前的文本到视频(T2V)生成模型因其能够从文本提示生成连贯视频而日益流行。然而,这些模型在处理较长、更复杂的提示时,常常难以生成在语义和时间上一致的视频,尤其是涉及多个对象或顺序事件时。此外,训练或微调这些模型的高昂计算成本使得直接改进变得不切实际。为了克服这些限制,本文提出了一种名为NeuS-E的新型零训练视频精修流程,利用神经符号反馈自动增强视频生成,实现与提示的更好对齐。该方法首先通过分析正式的视频表示来推导神经符号反馈,并识别语义不一致的事件、对象及其对应的帧。然后,该反馈指导对原始视频进行针对性编辑。在开源和专有T2V模型上的广泛实证评估表明,NeuS-E通过几乎40%的提升,在多样化提示中显著增强了时间和逻辑对齐。


04、(Im)possibility of Automated Hallucination Detection in Large Language Models
本文是否可能实现大型语言模型(LLMs)产生的幻觉的自动化检测进行了理论分析。受经典Gold-Angluin语言识别框架的启发,本文研究了一种算法是否能够在训练时仅使用来自一个未知目标语言K的样本(K是从可数语言集合L中选择的),并且可以访问LLM的情况下,可靠地判断LLM的输出是否正确或构成幻觉。首先,本文建立了幻觉检测与经典语言识别任务之间的等价关系。研究结果表明,任何成功的幻觉检测方法都可以转化为语言识别方法,反之亦然。鉴于语言识别已知的固有难度,这一结果表明,如果仅使用目标语言的正确示例(正样本)对检测器进行训练,那么对于大多数语言集合来说,自动化幻觉检测在本质上是不可能的。其次,本文展示了使用专家标记的反馈(即训练检测器时同时使用正样本和负样本)会显著改变这一结论。在这种丰富的训练条件下,自动化幻觉检测对于所有可数语言集合都是可能的。这些结果突出了专家标记示例在幻觉检测器训练过程中的关键作用,从而为基于反馈的方法(如人类反馈的强化学习)提供了理论支持,进一步解释了为什么这些方法在提高现实世界LLM部署的可靠性和安全性方面不可或缺。

05、Collaborative Multi-Agent Reinforcement Learning for Automated Feature Transformation with Graph-Driven Path Optimization
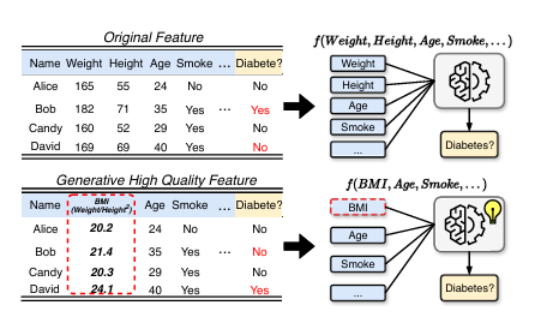
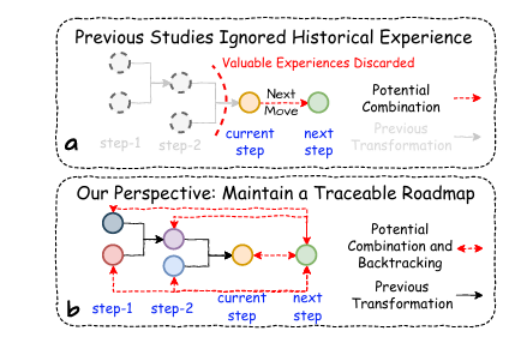
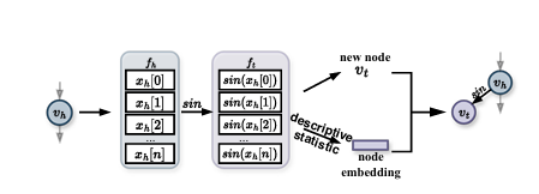
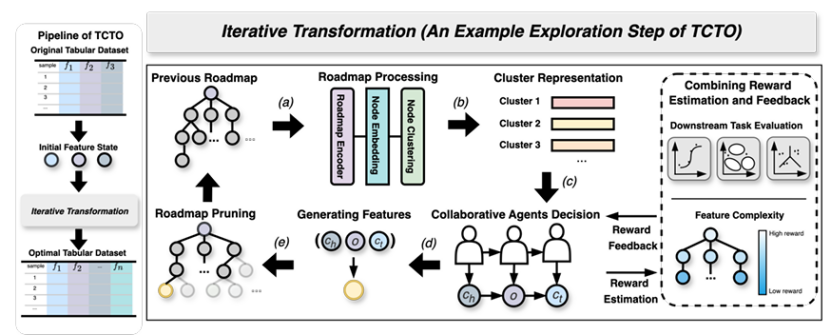
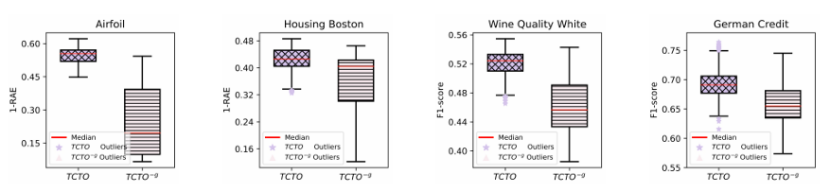
特征转换方法旨在找到一个最优的特征-特征交叉过程,以生成高价值特征并提升下游机器学习任务的性能。现有的框架虽然旨在减少人工成本,但常常将特征转换视为孤立的操作,忽略了转换步骤之间的动态依赖性。为了解决这些局限性,本文提出了TCTO,这是一个基于协作多智能体强化学习的自动化特征工程框架,通过图驱动的路径优化实现特征转换。该框架的核心创新在于一个动态演化的交互图,该图将特征建模为节点,将转换建模为边。通过图剪枝和回溯,它动态地消除低影响的边,减少冗余操作,并增强探索的稳定性。此外,该图还提供了完整的可追溯性,使TCTO能够从历史转换中重用高效用子图。为了证明本文方法的有效性和适应性,作者进行了广泛的实验和案例研究,结果表明该方法在多个数据集上均表现出优越的性能。
06、FRAG: Frame Selection Augmented Generation for Long Video and Long Document Understanding
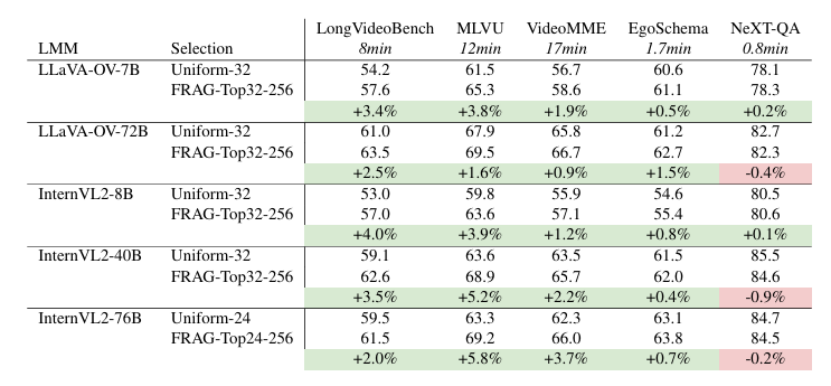
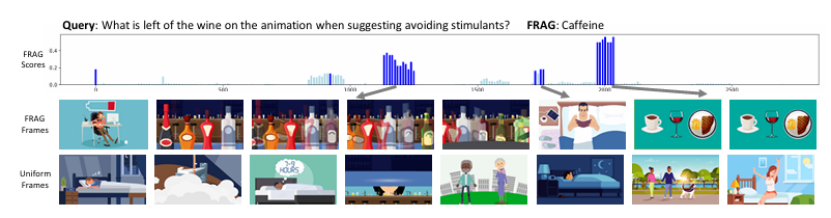
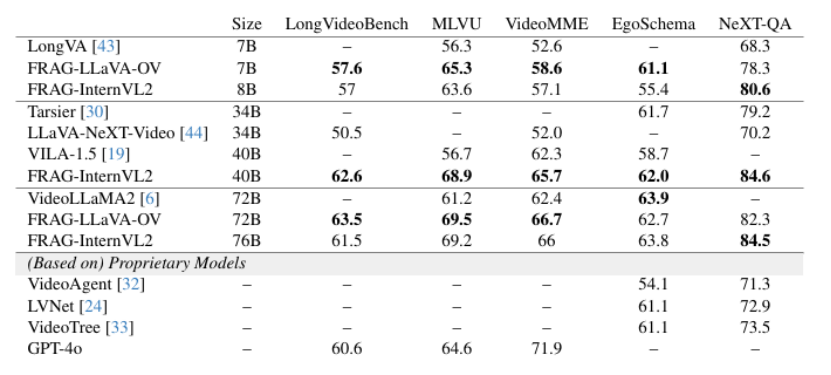
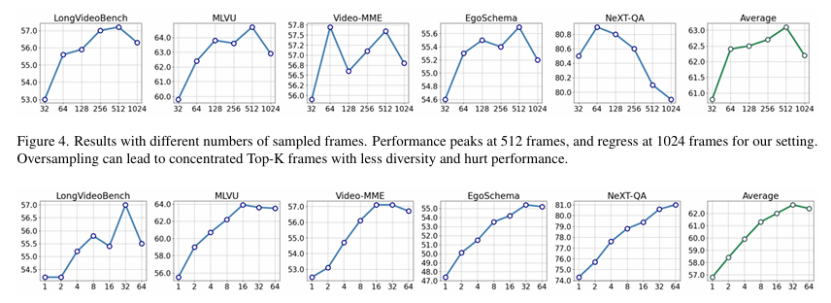
大型多模态模型(LMMs)在多模态理解方面取得了令人印象深刻的进展,例如在图像和视频的字幕生成和视觉问答任务中。近期的研究进一步将这些模型扩展到长输入数据,如多页文档和长视频。然而,由于训练和推理过程中的计算成本,这些长上下文 LMMs 的模型大小和性能仍然受到限制。在本研究中,作者探索了一个正交方向,即在没有长上下文 LMMs 的情况下处理长输入。作者提出了帧选择增强生成(FRAG),该模型首先选择与输入相关的帧,然后仅基于这些选定的帧生成最终输出。选择过程的核心是对每个帧独立打分,这不需要长上下文处理。得分最高的帧通过简单的 Top-K 选择被选中。研究表明,这种简单而有效的框架可以应用于现有的 LMMs,无需微调,即可在长视频和多页文档理解任务中实现性能提升,并达到最先进的水平。对于视频,FRAG 在 MLVU 和 Video-MME 数据集上分别将 InternVL2-76B 的性能提升了 5.8% 和 3.7%。对于文档,FRAG 在 MP-DocVQA 数据集上相比专门用于长文档理解的近期 LMMs 实现了超过 20% 的改进。


07、Assessing the Capability of Large Language Models for Domain-Specific Ontology Generation
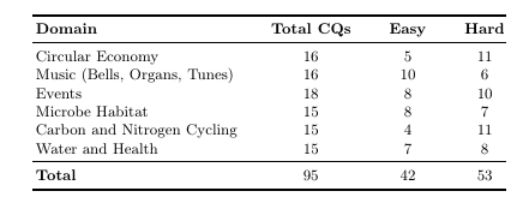
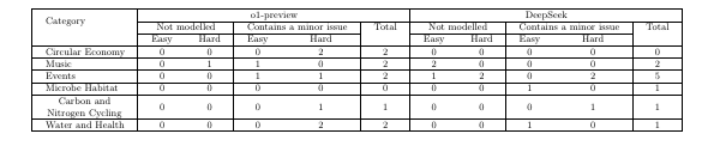
大型语言模型(LLMs)在本体工程领域展现出了显著的潜力。然而,目前尚不清楚它们在特定领域本体生成任务中的适用程度。在本研究中,作者探索了LLMs在自动化本体生成中的应用,并在不同领域对其性能进行了评估。具体而言,研究者们调查了两种最先进的LLMs——DeepSeek和o1-preview(均具备推理能力)的泛化能力,通过从一组能力问题(CQs)和相关用户故事中生成本体。实验设置涵盖了六个不同的领域,这些领域均来自现有的本体工程实践项目,并包含总共95个精心策划的CQs,旨在测试模型在本体工程中的推理能力。研究发现,使用这两种LLMs进行的实验在所有领域的表现都非常一致,表明这些方法能够在不同领域泛化本体生成任务。这些结果突出了基于LLM的方法在实现可扩展且领域无关的本体构建方面的潜力,并为增强自动化推理和知识表示技术的进一步研究奠定了基础。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









