







 本文介绍了HDFS中Block的组织形式,重点解析BlockInfoContiguous类及其内部的triplets对象数组,展示了如何通过BlockInfoContiguous实现节点上Block的链表操作,包括添加、删除和移动Block,并提到了Block迭代器BlockIterator的使用。
本文介绍了HDFS中Block的组织形式,重点解析BlockInfoContiguous类及其内部的triplets对象数组,展示了如何通过BlockInfoContiguous实现节点上Block的链表操作,包括添加、删除和移动Block,并提到了Block迭代器BlockIterator的使用。
前言
在HDFS中,数据的存储是以Block块的形式进行组织的.而每个块的默认副本数是3个,所以一般每个在HDFS中会存在3个相同的block块分布在不同的DataNode节点之上.所以在每个DataNode上,会存储着大量的block,那么这些块是如何被组织,联系起来的的呢,HDFS在添加块,移除块时是如何操作这些block块以及对应的关联信息呢,链表?数组?HashMap?答案就在BlockInfoContiguous这个类中.
BlockInfoContiguous邻近信息块
这个类不是在所有的Hadoop版本中都有,在最新的hadoop-trunk代码中这个类已经不怎么使用了,所以这里我要说明一下我学习使用的版本是hadoop-2.7.1.在此版本中,BlockInfoContiguous就是用来联系寻找block块的直接信息类.在官方的源码中对BlockInfoContiguous的注释为:
/**
* BlockInfo class maintains for a given block
* the {@link INodeFile} it is part of and datanodes where the replicas of
* the block are stored.
* BlockInfo class maintains for a given block
* the {@link BlockCollection} it is part of and datanodes where the replicas of
* the block are stored.
*/
@InterfaceAudience.Private
public class BlockInfoContiguous extends Block
implements LightWeightGSet.LinkedElement {
在BlockInfoContiguous类中,有2个内部关键的对象信息BlockCollection和triplets.前者保存了类似副本数,副本位置等的一些信息,而triplets对象数组的设计则是本文的一个重点.所以下面要独立出篇幅来详细的分析triplets的设计结构和思想.
triplets对象数组
triplets对象起始初始化是若干长度的Object对象,但是在赋值的时候,会存储2类的对象.此对象的源码注释如下:
/**
* This array contains triplets of references. For each i-th storage, the
* block belongs to triplets[3*i] is the reference to the
* {@link DatanodeStorageInfo} and triplets[3*i+1] and triplets[3*i+2] are
* references to the previous and the next blocks, respectively, in the list
* of blocks belonging to this storage.
*
* Using previous and next in Object triplets is done instead of a
* {@link LinkedList} list to efficiently use memory. With LinkedList the cost
* per replica is 42 bytes (LinkedList#Entry object per replica) versus 16
* bytes using the triplets.
*/
private Object[] triplets;1.对于当前block块的信息,block存在于哪些data-storage中,假如存储于i个节点,则triplets对象数组大小就是3 * i个,一般存储的节点数视副本系数而定.
2.对triplets每3个为一单位的数组来说,triplets[3 * i]保存的是data-storage信息,triplets[3 * i + 1]保存的是此data-storage中previous前一个block对象的信息,triplets[3 * i + 2]保存的则是后一块的block的信息,而保存block信息对象的类同样是BlockInfoContiguous.
所以你可以稍稍的想象一下,这其实是一个"巨大的链表".但是他为了更高效的使用内存没有用jdk自带的LinkList这样的链表结构.介绍triplets的结构重新再来看看BlockInfoContiguous的结构组成,下面是一张结构图:
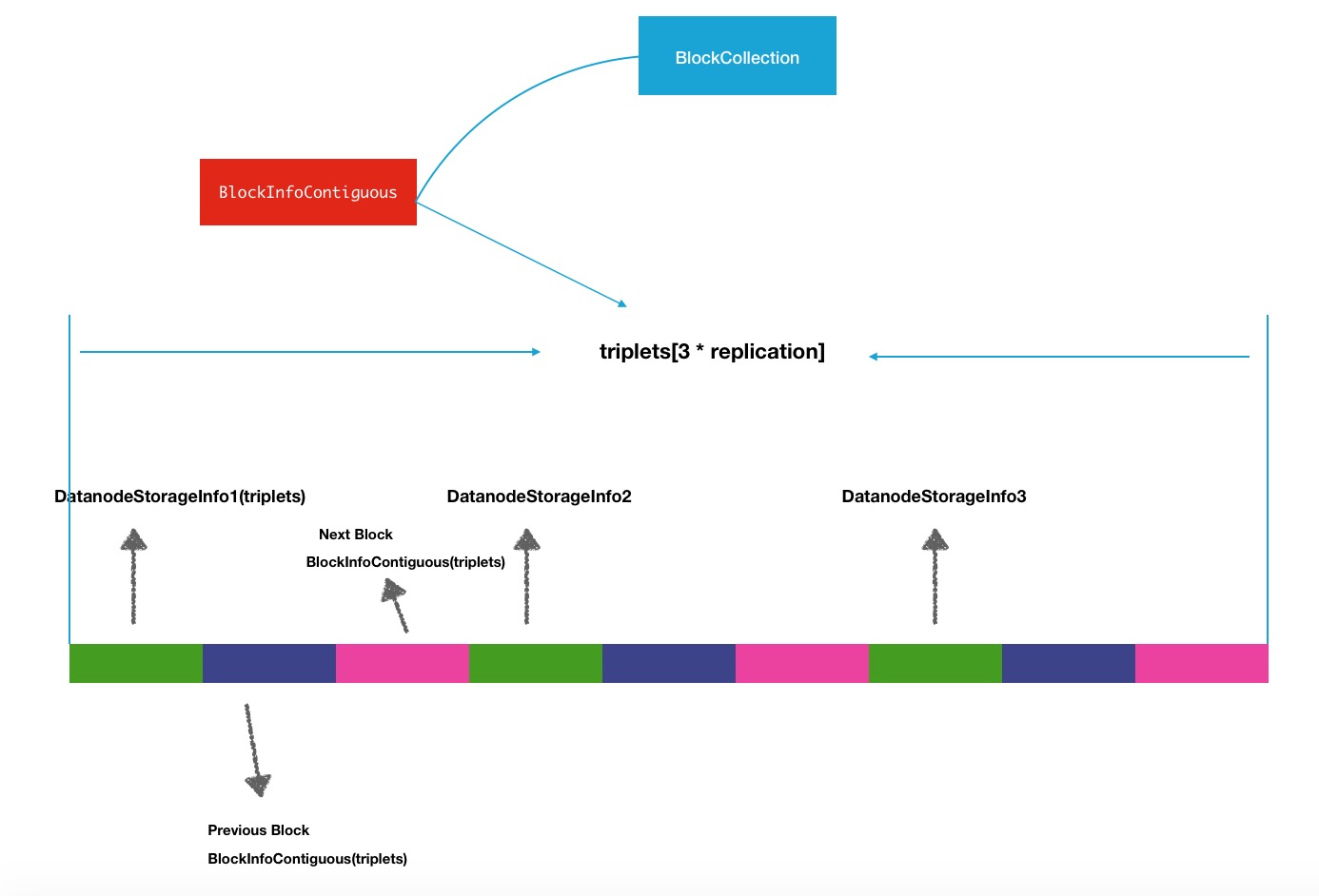
DatanodeStorageInfo1,2,3是当前block存储的节点,所以triplets的长度根据副本数进行初始化:
/**
* Construct an entry for blocksmap
* @param replication the block's replication factor
*/
public BlockInfoContiguous(short replication) {
this.triplets = new Object[3*replication];
this.bc = null;
}每个data-storage上会存储大量的block块,于是通过块的next块或previous块,可以遍历完整个节点上的所有块.所有在每个DataNodeStorageInfo中,所持有的block块的结构可以用下图进行展示:
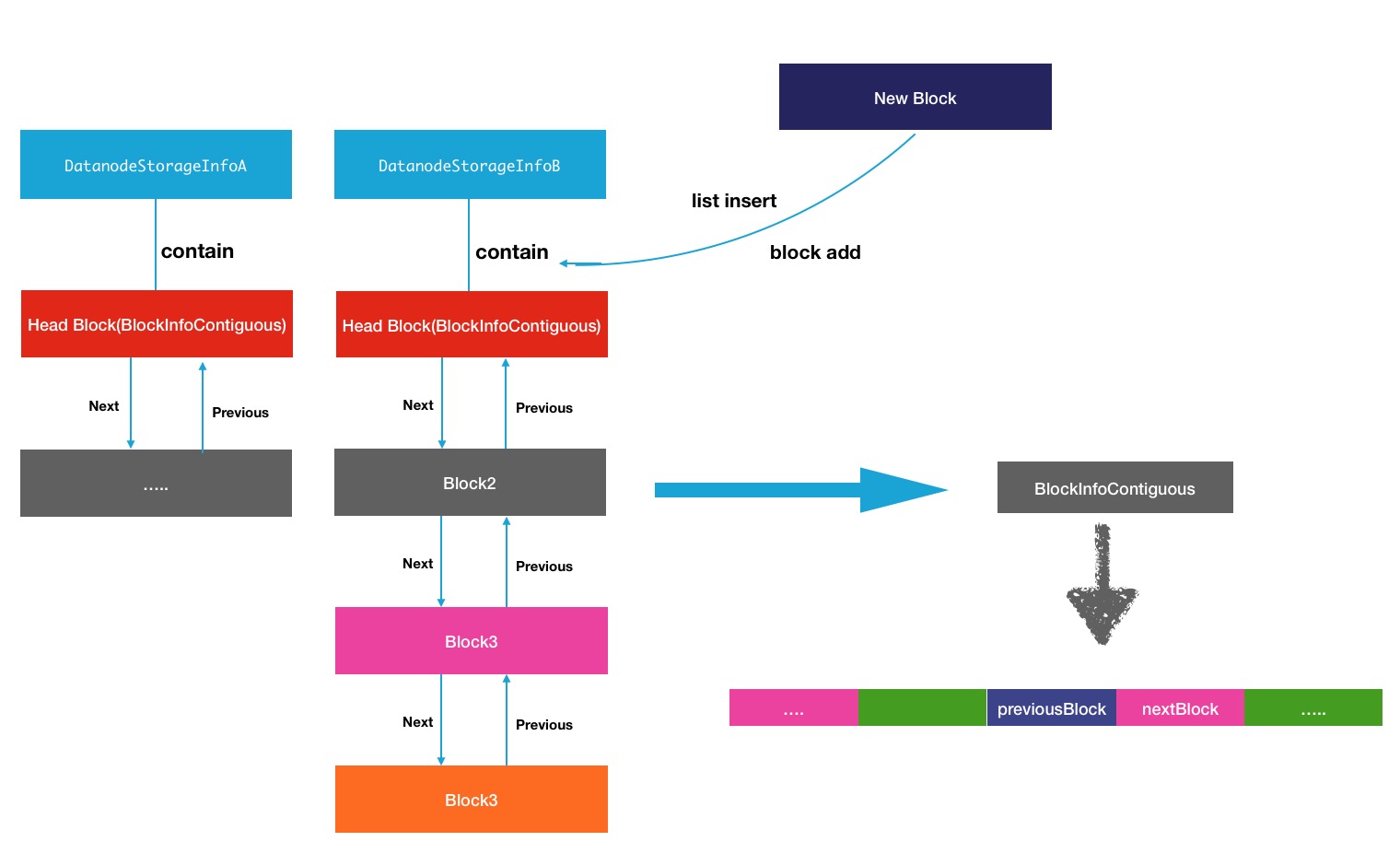
这里的head头block块,对应的是DataNodeStorage中的blacklist对象:
private volatile BlockInfoContiguous blockList = null;上面的同一个节点中的block块与block块之间的关系放大了的表示如下图所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1395
1395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









