







 本文详细分析了HDFS基于Zookeeper(ZK)的高可用性(HA)切换原理,重点介绍了ZKFC(ZKFailoverController)的构成,包括HealthMonitor、ActiveStandbyElector和服务状态回调。ZKFC通过监控NameNode的健康状态,并在ZK中创建和删除临时znode,实现自动切换Active和Standby NameNode。
本文详细分析了HDFS基于Zookeeper(ZK)的高可用性(HA)切换原理,重点介绍了ZKFC(ZKFailoverController)的构成,包括HealthMonitor、ActiveStandbyElector和服务状态回调。ZKFC通过监控NameNode的健康状态,并在ZK中创建和删除临时znode,实现自动切换Active和Standby NameNode。
前言
Hadoop社区在HDFS-1623(High Availability Framework for HDFS NN)以及相关JIRA中对NameNode增加了高可用性的支持。但是它的实现需要依赖管理员手动切换NameNode,以此来触发NameNode的切换。这种操作方式有时会带来一些问题,比如说一个NameNode因为非主观原因导致异常,挂了,这个时候怎么办,这个时候我们可能更需要自动切换的一套机制来解决这个问题。毕竟集群管理员不会随时随地地监控着集群。基于这个应用场景,社区在HDFS-3042(Automatic failover support for NN HA)对现有HA的功能增加自动切换的支持。因为HDFS-3042是一个父JIRA,本文我们将主要关注其最后的核心子JIRA,HDFS-2185(HA: HDFS portion of ZK-based FailoverController),也就是基于ZK的自动切换原理实现,对应呈现的形式就是我们平常看到的ZKFC进程。
基于ZK的HA切换原理
在讲解ZKFC进程的组成部分之前,我们需要了解HDFS如何依赖ZK实现切换操作的。首先我们需要了解一下什么是ZK以及ZK有什么作用,然后我们才能理解HDFS为什么要利用ZK来实现自动切换的机制。
ZK全称是Zookeeper,ZK的一个很大的特点是它可以保持高度的一致性,而且它本身可以支持HA,在ZK集群最后,只要保证半数以上节点存活,ZK集群就还能对外提供服务。
那么HDFS的Active、Standby节点与ZK有什么关联呢?
当一个NameNode被成功切换为Active状态时,它会在ZK内部创建一个临时的znode,在znode中将会保留当前Active NameNode的一些信息,比如主机名等等。当Active NameNode出现失败或连接超时的情况下,监控程序会将ZK上对应的临时znode进行删除,znode的删除事件会主动触发到下一次的Active NamNode的选择。
因为ZK是具有高度一致性的,它能保证当前最多只能有一个节点能够成功创建znode,成为当前的Active Name。这也就是为什么社区会利用ZK来做HDFS HA的自动切换的原因。
HDFS HA自动切换机制的核心:ZKFC
正如本节小标图所显示的,HDFS HA自动切换机制的核心对象是ZKFC ,也就是我们平常在NameNode节点上会启动的ZKFC进程。
在ZKFC的进程内部,运行着3个对象服务:
- HealthMonitor:监控NameNode是否不可用或是进入了一个不健康的状态。
- ActiveStandbyElector:控制和监控ZK上的节点的状态。
- ZKFailoverController:协调HealMonitor和ActiveStandbyElector对象,处理它们发来的event变化事件,完成自动切换的过程。
以上3者的运行结果图如图1-1所示。
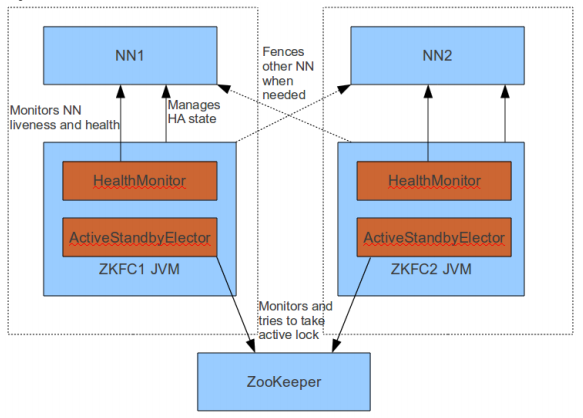
图 1-1 ZKFC组成以及运行图
接下来我们来简单介绍这3个对象服务。
HealthMonitor
首先是HealthMonitor监控服务,通过它的名称我们就能够看出它是一个监控服务。在此对象内部,定义了5种服务状态,如下代码所示:
public enum State {
// 1.The health monitor is still starting up.
INITIALIZING,
// 2.The service is not responding to health check RPCs.
SERVICE_NOT_RESPONDING,
// 3.The service is connected and healthy.
SERVICE_HEALTHY,
// 4.The service is running but unhealthy.
SERVICE_UNHEALTHY,
// 5.The health monitor itself failed unrecoverably and can
// no longer provide accurate information.
HEALTH_MONITOR_FAILED;
}翻译过来就是下面5种状
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2627
2627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









