







前言
众所周知,HDFS的扩展性问题一直是一个被谈论已久的问题。HDFS NN内部的全局单一锁的设计在数以亿计规模的block内存对象的情况下,存在着不小的性能瓶颈问题。当NN在处理A用户的写请求操作时,意味着其它用户的写请求将会被block住。当然这个时候,我们可能会采用一些横向扩展方案,诸如HDFS Federation或者Router Based Federation这类的方案来解决这里的扩展性问题。不过今天笔者要谈论的是社区最近提出的一种新的方案(HDFS-14703: NameNode Fine-Grained Locking via Metadata Partitioning):基于NN Namespace的内部partition来将全局锁进行细粒度化地拆分,从而解决NN的扩展性问题。
HDFS NN的现有请求处理模式
我们先来回顾回顾HDFS NN的现有请求处理模式。简单地理解,一个整体大的命名空间数据(元数据),一个全局锁,然后对于客户端写请求,可以支持读操作共享,但是写操作则是互斥的。
简单的过程图如下所示:
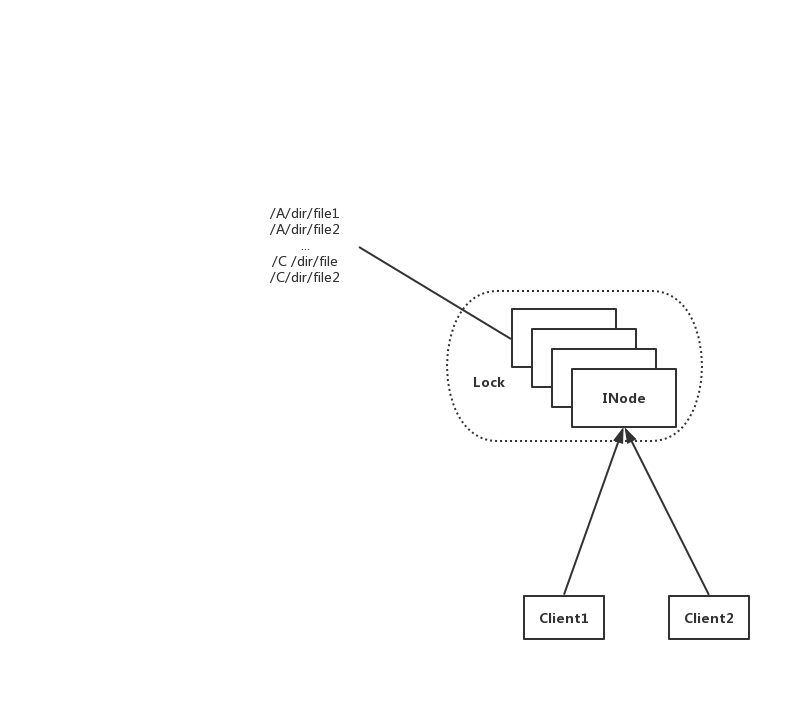
在上图中,为了保证元数据更新的原子性,NN并没有做到完全并行地处理来自Client1和Client2所发来的写请求。但是仔细细看这个过程,有些情况其实我们并不需要对这个过程进行全局加锁的操作。比如当C
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1604
1604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









