







回归的简单解释:假设现在有一些数据点,我们用一条直线对这些点进行拟合(该线称为最佳拟合直),这个拟合过程就称作回归。利用Logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。
Sigmoid函数和Logistic回归
我们想要的函数是可以接受所有的输入然后预测出类别。Sigmoid函数是一个阶跃函数,且跳跃点不是像海维赛德阶跃函数(Heaviside step function)那样瞬间跳跃,在数学上更好处理。
Sigmoid函数定义:
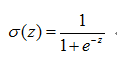
为了实现Logistic回归分类器,我们可以在每个特征上都乘以一个回归系数,然后把所有的结果值相加,将这个结果带入Sigmoid函数中,进而得到一个范围在0~1之间的数值。由于Sigmoid的值域为[0,1],所以带入Sigmoid函数后的结果也是[0,1]。大于0.5的结果将被分为1类,小于0.5的将被分为0类。所以这也是一种概率估计。
确定分类器的函数形式之后,解决这个问题就变成了求最佳回归系数问题。
梯度上升法和确定最佳回归系数
如上文所述,Sigmoid函数的输入为每个特征乘以一个回归系数,用公式表示为:
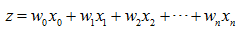
向量表示为:
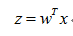
其中z为Sigmoid函数输入值,x为分类器的输入数据,w是我们要找的最佳参数。
梯度上升法的思想是:要找到某个函数的最大值,最好的方法是验证该函数的梯度方向探寻。
函数f(x,y)的梯度如下表示:
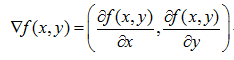
由该式子可以看到,梯度算子总是指向函数值增长最快的方向。所确定的是移动方向,而没有确定每次的移动距离。所以梯度上升的完整迭代公式为:
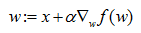
值得一提的是我们经常可以看到梯度下降,该方法与梯度上升法相反,是用来求函数最小值的。对应的公式是将上式中的加号变为减号。
下面给出梯度上升法的伪代码:
每个回归系数初始化为1
重复R次:
计算整个数据集的梯度
使用alpha × gradient更新回归系数的向量
返回回归系数
python代码为:
def sigmoid(input_x):#定义sigmoid函数
return 1.0/(1 + exp(-input_x))
def grad_ascent(data_mat_in, class_labels):
data_matrix = mat(data_mat_in)
label_mat = mat(class_labels).transpose()
m,n = shape(data_matrix)
alpha = 0.001
max_cycles = 500
weights = ones((n,1))
for k in range(max_cycles):
h = sigmoid(data_matrix * weights)
error = (label_mat - h)
weights = weights + alpha * data_matrix.transpose() * error
return weights实际代码中梯度上升的关键几步代码分别是:
error = (label_mat - h)
weights = weights + alpha * data_matrix.transpose() * error为什么这样计算就确定了梯度,也就是上升的方向呢?
这里涉及一个简单的数学推导。
在线性回归模型中,依据最小二乘法cost function是最小化观察值和估计值的差平方和。如下:
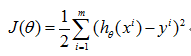
选择这个方法的原因在此不做详细推导,简单来说就是假设线性模型中的误差错误因素等满足高斯分布,而对高斯分布做最大似然估计后即可推出这个公式。
但是对于logistic回归来说我们不能再继续应用这个cost function,因为此时我们会发现这不是一个凸函数,存在很多局部极值点,无法梯度迭代得到最终的参数。
那么就需要确定新的cost function,推导过程如下:
我们将h作为y=1的概率,(1-h)作为y=0的概率,那么联合概率密度函数就可以表示为:
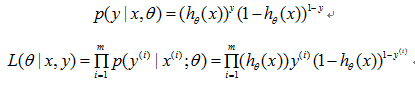
这其中y = 0或1。
再取对数:
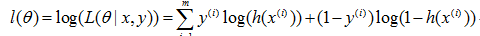
这样就得到了cost function
然后我们需要做的就是使用梯度上升法找到这个函数的最大值,也就是沿着梯度的方向查找。根据上式进行简单推导就能得到梯度上升的公式:
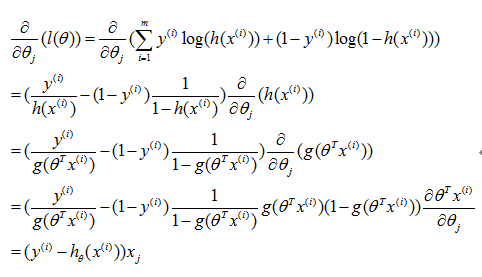
这样我们就得到了最终的迭代方式:
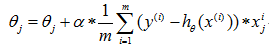
也就是代码中的方式。
随机梯度上升及其优化
梯度上升算法在每次更新回归系数时都需要更新整个数据集,在处理大数据时及训练集和每个样本的特征个数都非常大的时候,计算复杂度过高。改进方法是一次仅用一个样本点来更新回归系数,称为随机梯度上升方法。
随机梯度上升算法的伪代码为:
所有回归系数初始化为1
对训练集中的每个样本
计算该样本的梯度
使用alpha × gradient更新回归系数的向量
返回回归系数
python实现为:
def stoc_grad_ascent(data_matrix, class_labels):
m,n = shape(data_matrix)
alpha = 0.01
weights = ones(n)
for i in range(m):
h = sigmoid(sum(data_matrix[i] * weights))
error = class_labels[i] - h
weights += alpha * error * data_matrix[i]
return weights单纯运行两种程序会发现针对给定的数据集,随机梯度上升法的准确率较梯度上升法低了一些,这是因为后者是在整个数据集上迭代了500次(在程序中可以看到)得到的结果。我们通过优化,让随机梯度上升算法在整个数据集上运行200次,得到的结果就会优化很多。
代码:
def stoc_grad_ascent1(data_matrix, class_labels, num_iter=500):
m,n = shape(data_matrix)
weights = ones(n)
for j in range(num_iter):
data_index = range(m)
for i in range(m):
alpha = 4 / (1.0 + j + i) + 0.01#随着迭代减小alpha,减小alpha的影响,有常数保证永不为0,保证新数据仍然具有影响
rand_index = int(random.uniform(0,len(data_index)))#随机选取样本点更新数据,避免周期性波动
h = sigmoid(sum(data_matrix[rand_index] * weights))
error = class_labels[rand_index] - h
weights += alpha * error * data_matrix[rand_index]
del(data_index[rand_index])
return weights分类器
通过上述方法求得回归系数后就可以非常简单的实现分类器了。
代码如下:
def classify_vector(in_x,weights):
prob = sigmoid(sun(in_x * weights)
if prob > 0.5:
return 1.0
else:
return 0.0














 501
501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









