








低光照场景在现实世界应用中很普遍(例如自动驾驶和夜间监控)。最近,在各种实际用例中的多目标跟踪受到了很多关注,但在暗场景中的多目标跟踪却鲜少被考虑。
在本文中,作者专注于暗场景中的多目标跟踪。为了解决数据集缺乏的问题,作者首先构建了一个低光照多目标跟踪(LMOT)数据集。LMOT提供了由作者的双摄像头系统捕获的、对齐良好的低光照视频对,以及所有视频的高质量多目标跟踪标注。然后,作者提出了一种低光照多目标跟踪方法,称为LTrack。
作者引入了自适应低通下采样模块,以增强图像中除传感器噪声之外的低频成分。退化抑制学习策略使模型能够在噪声干扰和图像质量退化下学习不变信息。这些组件提高了暗场景中多目标跟踪的鲁棒性。
作者对LMOT数据集和提出的LTrack进行了全面分析。实验结果证明了所提出方法的优越性及其在真实夜间低光照场景中的竞争力。
数据集和代码:https://github.com/ying-fu/LMOT。
1 Introduction
多目标跟踪(MOT)旨在定位并关联视频序列中的多个目标。它广泛应用于许多下游应用中,如视频识别[7, 32],自动驾驶和监控。近年来,各种实际应用场景中的多目标跟踪受到了广泛关注,极大地推动了MOT的发展。然而,这些工作主要针对高质量输入而定制,忽略了现实世界中普遍存在的低光照场景。
基于此,作者研究在暗场景下的多目标跟踪。
由于现有相机的物理限制,在低光照条件下获取高质量视频是困难的。在这种条件下捕获连续视频帧的一个固有的难点是避免运动模糊。当前相机技术通常需要短的曝光时间(通常只有几十毫秒),但在低光照场景中,传感器在有限的持续时间内难以捕捉到足够数量的光子。这种限制不可避免地导致图像质量下降,同时噪声水平升高。这对于低光照条件下的MOT提出了两个主要挑战。
第一个挑战是收集低光照多目标跟踪数据集。收集和标注低光照MOT数据集既困难又昂贵。MOT需要动态目标视频,但低光照场景中捕获的视频亮度极低,使得在视频中识别和标注目标变得困难。
第二个挑战围绕着低光照多目标跟踪。流行的“基于检测的跟踪”范式通常包括检测器、基于运动的关联模块和基于外观的关联模块。
这些模块通常需要高质量的输入图像。低光照图像的劣质导致检测器和基于外观的相关模块性能严重下降。一个简单的方法是级联低光照增强模块[2, 23, 24, 47],但这引入了额外的计算成本。
此外,优化视觉质量的图像可能对下游任务[6, 21, 27]不是最优的。
在本文中,作者构建了一个低光照多目标跟踪数据集(LMOT),专门用于解决暗场景下多目标跟踪的挑战。为此,作者开发了一个双摄像头系统,可以同时捕获光照良好和低光照的视频帧。视频对在空间和时间维度上高度对齐,提供两个主要优势。
首先,它使作者能够在光照良好的视频上进行标注,从而产生高质量的标注。其次,光照良好的视频可以在训练阶段提供额外的监督信息,并在暗场景中强烈提升性能。经过仔细标注,作者收集了32个视频序列(2.3 MOT17),超过35K帧(3.1 MOT17),以及超过815K边界框(2.8 MOT17)。
RAW数据是图像传感器的输出,是图像信号处理器(ISP)的输入数据。它保存了来自图像传感器的所有信息,这对于在暗场景中捕捉目标信息至关重要[6, 52, 67]。因此,作者为LMOT收集了RAW视频。
此外,作者提出了一种低光照多目标跟踪方法,称为LTrack。低光照视频的特点是传感器噪声大,图像质量差,这显著降低了浅层和深层特征表示,导致跟踪性能下降。
作者观察到低光照图像中的传感器噪声与对抗性攻击[35, 43]相似。为了解决这个问题,作者的主要思想是学习在噪声干扰质量下降下的不变语义信息。作者提出了自适应低通下采样模块(ALD)。
它使用空间低通卷积从图像中提取低频分量,排除噪声,并自适应地增强特征图。作者还提出了退化抑制学习策略(DSL),它利用配对的低光照视频帮助模型在特征域中抑制噪声干扰,并鼓励图像内容响应。
作者对LMOT数据集进行了全面分析,并在真实夜间场景中验证了LTrack的优越性。
总之,作者的主要贡献如下:
-
作者使用精心构建的双摄像头系统构建了第一个低光照多目标跟踪数据集。它提供了以RAW格式对齐的低光照视频,以及所有视频的高质量MOT标注。
-
作者提出了一种低光照多目标跟踪方法。它利用自适应低通下采样模块和退化抑制学习策略,从低光照视频中学习提取不变特征。
-
作者对数据集和提出的方法进行了全面分析。实验结果表明,所提出的方法在真实夜间场景中的优越性和竞争力。
2 Related Work
在本节中,作者首先回顾了低光照增强和低光照数据集的当前研究状况。然后,作者对在暗场景下的多目标跟踪研究进行了总结。
低光照增强。传统的低光照增强方法主要基于直方图均衡化和Retinex理论。近年来,深度学习已被用于许多低级任务,并在低光照增强[2, 4, 13, 15, 19, 24, 39, 53]上取得了优越的结果。
尽管这些方法能够恢复具有高视觉质量的图像,但它们通常需要繁重的计算,并且可能没有考虑下游任务,导致性能次优。相比之下,作者的方法专注于直接从低光照图像中学习多目标跟踪,从而绕过了低光照增强。
低光照数据集。长短曝光是一种广泛用于收集成对低光照图像的方法,但只能用于收集静态场景的低光照图像[4, 5, 49]。为了捕捉动态场景,一些研究设计了机电系统。
他们通过重复运动两次获得成对的低光照数据[13, 47]。然而,这些机电系统不能用于在野外收集动态目标视频。蒋等人[23]设计了一个双摄像头系统,可以同时捕捉到成对的充足光照和低光照视频,这使得捕捉动态场景和动态目标视频用于多目标跟踪成为可能。邹等人[57]设置了一个光学系统来收集成对的视频和事件流。
这些工作探索了构建低光照数据集的各种方式,并激发了暗场景中高级视觉任务的研究,例如用于目标检测的LOD[21],用于实例分割的LIS[6],以及用于人体姿态估计的ExPose[27]。这些数据集仅为图像任务提供成对的低光照数据,不能扩展用于暗场景中的多目标跟踪。
多目标跟踪数据集。MOT15[26]是第一个大规模的多目标跟踪基准。MOT17[34]是最广泛使用的MOT基准之一。MOT20[9]关注非常拥挤的场景。这三个数据集都是针对行人的。KITTI[18]和BDD100K[55]是针对自动驾驶场景的。DanceTrack[42]关注于舞蹈场景,特点是外观相似和动作多样。最近,SportsMOT[8]旨在追踪运动员,并鼓励算法促进外观和动作关联。这些数据集探索了在各种实际使用情况下的多目标跟踪,但它们都没有考虑暗场景中的多目标跟踪。
暗场景中的目标跟踪。为了在低光照场景中跟踪,一些方法探索使用多模态信息进行单目标跟踪,例如事件摄像头[58, 64]、深度[40, 54]和热成像[46, 59]设备。Park等人[36]提出使用短波红外(SWIR)图像进行多目标跟踪,因为其在低光照条件下的鲁棒性优势。
这些方法的共同缺点是它们需要额外的硬件设备,不能应用于最广泛使用的CMOS成像系统。
SORT[1]使用卡尔曼滤波运动模型,并采用IoU进行关联。ByteTrack[62]通过考虑低置信度边界框来提高跟踪性能。OS-SORT[3]通过恢复丢失的目标来增强SORT。
最近,Transformer已被用于MOT[16, 33, 41, 56, 63]。这些方法在许多实际场景中取得了高性能,但它们没有考虑处理低光照条件。作者关注低光照条件下的多目标跟踪。基于RAW视频,作者的方法具有很高的实用性,性能优秀,且不需要额外的硬件。
3 Low-light Multi-object Tracking Dataset
在本节中,作者首先介绍作者的双摄像头系统以及收集和标注作者的低光多目标跟踪(LMOT)数据集的细节。然后,作者分析了作者的LMOT数据集的统计特性。
Dataset Construction
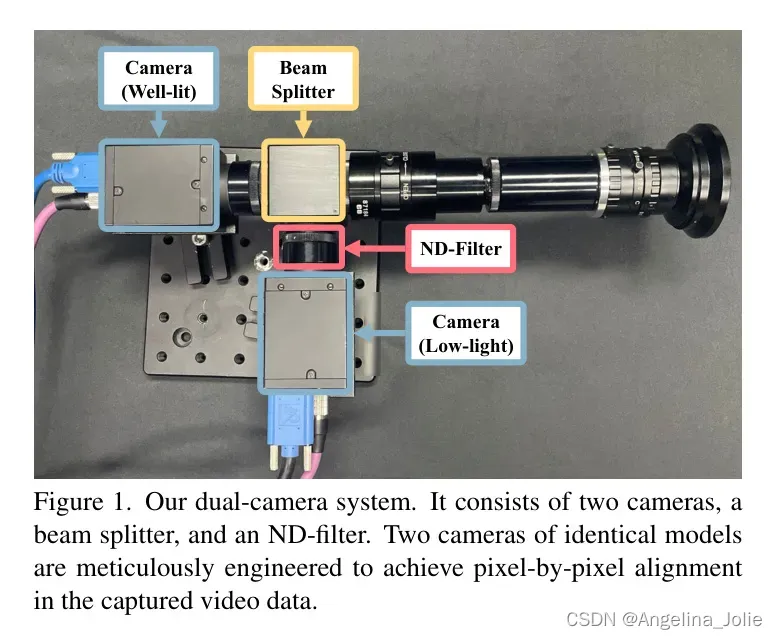
多目标跟踪需要动态场景和目标视频。为了收集多目标跟踪的低光照视频,作者构建了一个双摄像头系统[23],如图1所示。它可以同时捕获成对的低光照和光线充足的视频。其主要组件包括一个光束分光器、一个中性密度(ND)滤镜和两个_FLIR Grasshopper3 GS3-U3-23S6C_摄像头。光束分光器将入射光分为两条独立的路径。这种布置使得一个摄像头可以直接捕获光线充足的照片,而另一个摄像头在ND滤镜减弱光强的情况下记录低光照图像。为了确保视频帧的时间同步,作者使用硬件接口触发摄像头曝光事件。此外,为了避免帧丢失,作者的双摄像头系统使用两个独立的硬件接口进行数据传输,并配备了高速固态硬盘。由于精确校准,作者的双摄像头系统可以实时捕获动态场景和目标的高低光照视频对。关于作者的双摄像头系统的更多详细信息在_补充材料_中给出。
在图像由摄像头图像信号处理器(ISP)处理之前,作者将视频帧保存为RAW格式。在摄像头设置方面,作者将两个摄像头的曝光时间设置为,帧率固定为20。这个设置可以避免运动模糊。作者调整光线充足摄像头的增益水平以获得最佳图像质量。低光照摄像头的增益始终设置为最大值,以模拟实际场景中的低光照捕捉设置。作者还收集了一个真实的低光照MOT数据集(LMOT-real),以评估在真实黑暗场景中的性能。这些视频是使用具有相同摄像头设置的单一摄像头捕获的。
作者的LMOT数据集包含了各种城市户外场景,包括道路、立交桥、行人和交叉口。立交桥场景从上方拍摄目标,而所有其他场景都是从行人的视角捕获的。为了考虑摄像头运动的影响,作者在摄像头上引入了任意水平旋转和垂直随机移动。

作者标注了六种移动目标,包括汽车、人、自行车、摩托车、公交车和卡车。标注的标签包括边界框、标识和可见性状态。对于部分遮挡的目标,标注一个完整的框。对于完全遮挡的目标,标注一个估计的框。
每个目标在整个视频中都有一个唯一的ID。由于低光照和光线充足的视频良好对齐,作者可以标注光线充足的视频,同时为低光照视频获取标签。这大大降低了标注难度并提高了质量。
最后,作者仔细审查了所有的标注结果。
Dataset Statistic
LMOT是一个专注于暗场景中多目标跟踪的大规模数据集。
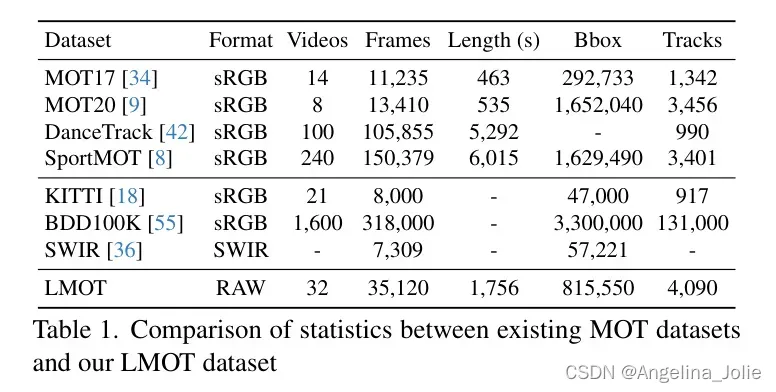
作者在表1中比较了LMOT与现有MOT数据集的统计信息。可以看出,LMOT大约是MOT17 [34]的三倍大。与DanceTrack [42]、SportsMOT [25]、KITTI [18]和BDD100K [55]等大规模数据集相比,LMOT的规模仍然相当可观。需要强调的是,这些数据集并非针对暗场景中的多目标跟踪,仅提供sRGB图像。与SWIR相比,作者的LMOT数据集帧数约为,边界框数量约为。LMOT的详细统计和数据划分在表2中展示。
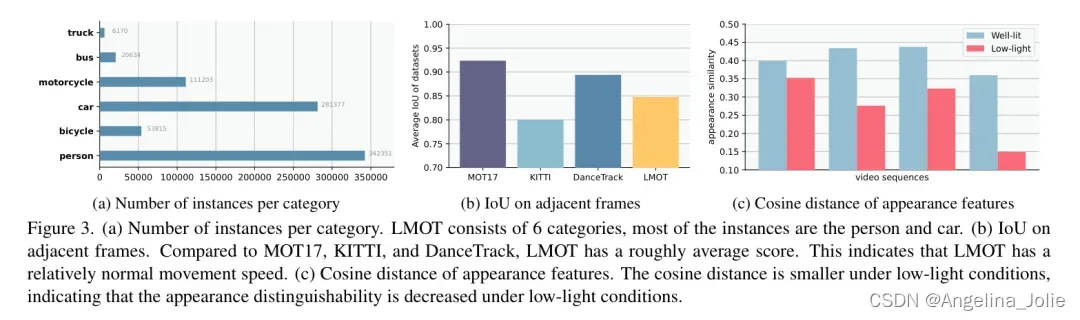
作者在图3 (a)中展示了每个类别的实例数量。大多数实例是人和汽车。如图3 (b)所示,LMOT在相邻帧上的平均IoU低于MOT17和DanceTrack,但高于KITTI。
这表明LMOT中的运动速度快,但仍在正常范围内。遵循[42],作者使用外观特征1的余弦距离来评估外观相似性。从图3 (c)可以看出,在低光照条件下,外观特征的余弦距离小于在良好照明条件下的余弦距离。换句话说,在低光照条件下,物体的外观会恶化,使它们更难以区分。
4 低光照多目标跟踪
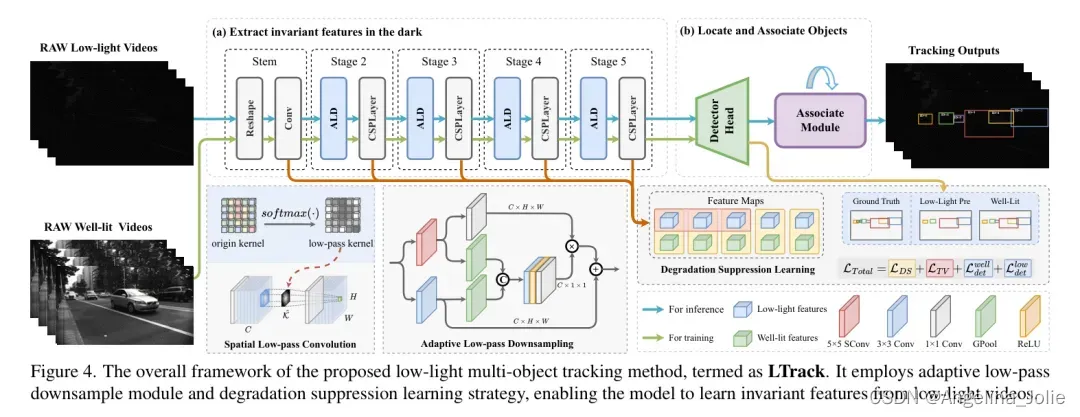
在本节中,作者提出了作者的低光照多目标跟踪方法(LTrack)。作者的主要思想是 _在噪声干扰质量下降的情况下学习不变的语义信息_。整体框架如图4所示。
Formulation and Motivation
在低光照场景中,相机在一次曝光中只能捕获到少量的光子。因此,潜在的传感器噪声被放大,导致图像质量显著下降[50]。作者观察到,在没有特殊设计的情况下,直接将低光照图像输入网络会导致特征图退化,显著降低模型的性能(详见第5.2节)。一个直接的解决方案是应用低光照增强技术,这些技术专注于学习从低光照图像到干净、明亮图像的映射函数。由于这是一个高度不适定的问题,学习这样的映射函数需要相当大的计算和存储开销。尽管基于深度神经网络的方法在低光照增强方面已经取得了优异的性能,但为视觉质量增强的图像对于下游任务可能并不是最优的。
在这项工作中,作者从低光照图像中执行多目标跟踪,绕开了低光照增强。利用RAW视频,网络相比于sRGB获取了更多的原始场景信息。
为了增强多目标跟踪模型的性能和鲁棒性,作者的主要思想是在噪声干扰质量退化下学习不变的语义信息。因此,作者提出了自适应低通下采样(ALD)模块,以增强图像的低频成分并滤除高频噪声。作者还提出了退化抑制学习策略(DSL),它利用配对的低光照视频帮助模型抑制图像噪声干扰,并在特征域中鼓励图像内容响应。
Adaptive Low-pass Downsampling
下采样操作在保留最重要信息的同时减小特征尺寸。低光图像中的噪声对特征图引入了高频干扰,这可能导致物体信息的保留出现误导。为了减弱高频噪声的影响并增强特征图的低频部分,作者引入了空间低通卷积(SConv)以从噪声特征图中提取低频特征。作者使用softmax函数将原始卷积核约束为低通形式,如下所示:
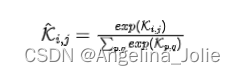

Degradation Suppression Learning
在低光照图像和充足光照图像对共享相同内容的情况下,模型应该对它们表现出相同的特征响应。然而,低光照图像导致浅层特征充满噪声,深层特征对物体的响应较低(如图5所示)。为了解决这个问题,作者的想法是在浅层特征中抑制图像噪声,并使用充足光照图像帮助模型从低光照图像中学习抗干扰的信息。退化抑制损失可以表示为


5 Experiments
Experiment Setup
数据集划分。在构建作者的数据集时,作者将视频随机划分为训练集、验证集和测试集,分别包含11、4和11个视频。
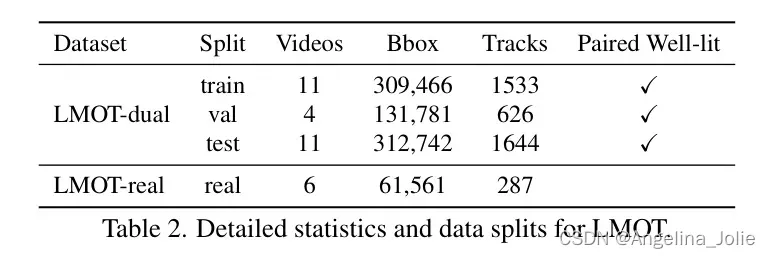
作者还提供了在真实夜间场景中捕获的LMOT-real数据集,包含6个视频。详细的数据集划分和统计信息如表2所示。
评估指标。遵循[8, 42],作者建议使用HOTA [31]作为主要评估指标,同时评估检测和关联的性能。作者还使用AssA和IDF1 [37]来评估关联性能,使用MOTA和Beta来评估检测性能。将所有类别的指标合并为一个分数有两种方法。一种是通过类别值平均指标,另一种是通过检测值平均。为了避免可能由样本较少的类别(如公交车和卡车)引起的结果偏差,作者通过检测值平均来合并分数。
实现细节。遵循ByteTrack [62]和OC-SORT [3],作者使用YOLOX [17]作为作者的检测器。跟踪器在COCO [28]数据集上进行预训练,然后在作者的LMOT数据集上训练24个周期。
作者应用了数据增强策略,包括随机翻转、缩放抖动重置大小和马赛克。
作者还使用基于物理的噪声模型[50]进行RAW图像增强。作者使用带有权重衰减和余弦学习率计划的SGD优化器,初始学习率为,逐渐降低到
。
作者对所有跟踪器应用线性插值作为后处理,最大间隔设置为20。
Analysis under low-light conditions
作者分析了低光照条件对使用LMOT验证集的多目标跟踪的影响。需要强调的是,在LMOT中,低光照和充足光照的视频对是完全对齐的。
对检测器的影响。作者首先分析光照条件对检测器的影响。
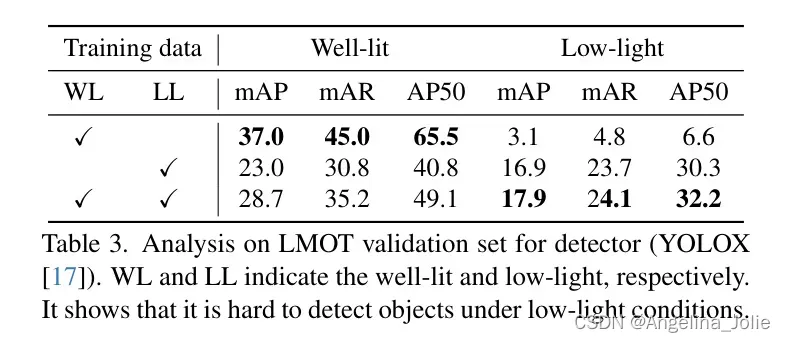
作者选择YOLOX作为检测器,因为它在MOT领域被广泛使用[3, 8, 62]。作者使用充足光照图像(WL)、低光照图像(LL)以及所有图像(AL)来训练检测器,然后在充足光照和低光照图像上进行测试。
结果展示在表3中。从表中可以看出,使用充足光照图像训练的模型在充足光照图像上取得了最好的结果,但在低光照图像上的性能显著下降。此外,作者在图5中可视化了这两种光照条件下特征图。
可以看出,由于传感器噪声,低光照图像的浅层特征和深层特征显著退化。作者还观察到,使用低光照图像可以在低光照条件下显著提高解码器的性能,而使用所有图像可以达到最佳性能。但这个结果仍远低于充足光照条件下的性能。
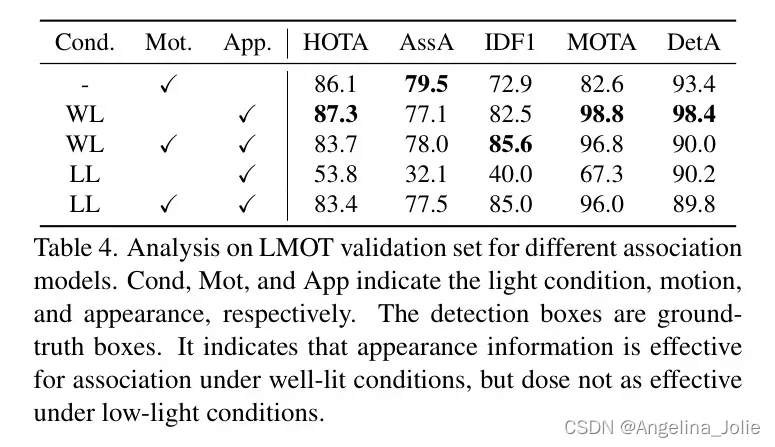
对关联模块的影响。作者分析了低光照条件对目标关联模块的影响。运动和外观对于目标关联至关重要。它们都依赖于检测框来定位物体。为了分离检测器的影响,作者使用真实框作为检测框。结果展示在表4中。可以看出,在充足光照条件下仅使用外观匹配可以达到最佳结果,而在低光照条件下仅使用外观匹配则导致性能非常差。这表明LMOT中的物体具有明显的视觉可区分性,但在低光照条件下这种可区分性显著降低。在图6中,作者可视化了LMOT数据集在充足光照和低光照条件下物体的外观特征。作者可以观察到,在充足光照条件下,LMOT在特征空间中非常容易区分。然而,在低光照条件下,LMOT的这种区分性显著下降。

Results on LMOT dataset
作者将提出的方法与潜在的低光照多目标跟踪方法进行了比较。首先,作者使用低光照视频、良好光照视频以及两者结合的视频,在没有对 Baseline 跟踪器进行任何修改的情况下,训练了三个 Baseline 模型。它们分别表示为Base-low、Base-well和Base-all。第二种方法是低光照增强后的跟踪。这些方法使用低光照增强方法作为预处理模块。增强后的视频和良好光照视频都被用于训练。
为了比较,作者选择了四种不同的低光照增强技术。LLFlow [48]和SDSD [47]是基于RGB图像的低光照增强方法,而DNF [24]和SMOID [23]是基于RAW的低光照增强方法。LLFlow和DNF以图像作为输入,SDSD和SMOID以视频作为输入。RAW目标检测方法也在良好光照和低光照视频上一起训练。其输出的边界框直接馈送到跟踪器。作者在两个最先进的跟踪器BytTrack [62]和OC-SORT [3]上测试了所有潜在的方法。作者还展示了mAP、AP50和AP75以突出检测器的性能。
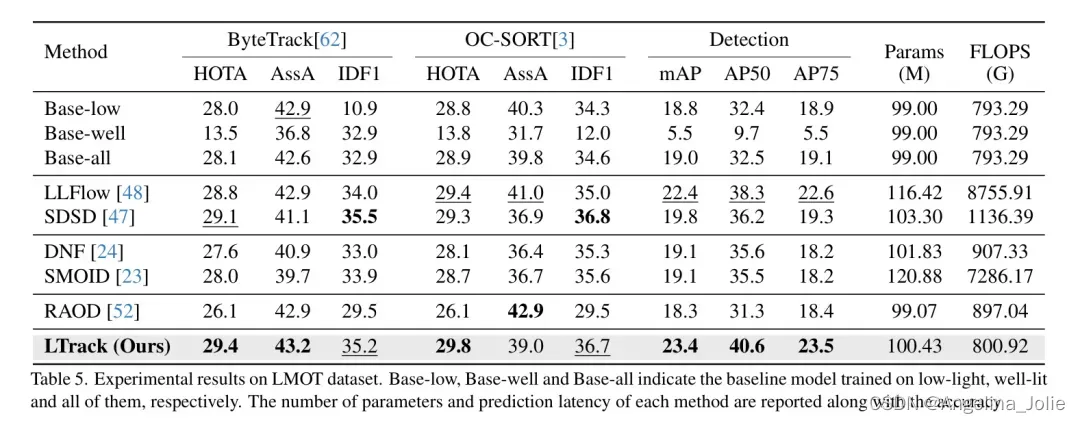
从表5中作者可以看出,提出的LTrack在HOTA上取得了最佳效果,并且在所有指标上都具有很高的竞争力。例如,与 Baseline 方法几乎相同的参数和计算量下,所提出的方法将HOTA提高了。这强烈证明了所提出方法的有效性。与低光照增强后的跟踪相比,这些方法具有大量的额外参数和计算量,但仍然比提出的方法表现得更差。例如,LLFlow提供了倍的FLOPS,但仍然比作者的LTrack表现差。
此外,作者观察到基于RAW的图像增强方法和基于RGB的图像增强方法在结果上没有显著差异。这与作者方法的观察不一致。
原因可能是低光照增强关注图像质量的恢复,可能会误导下游任务。至于RAOD [52],它的参数数量和计算负载与作者的方法几乎相同,但其性能远低于提出的LTrack。尽管通过预处理模块处理RAW输入来解决HDR场景,但在低光照条件下其表现并不好。
Results on Real World
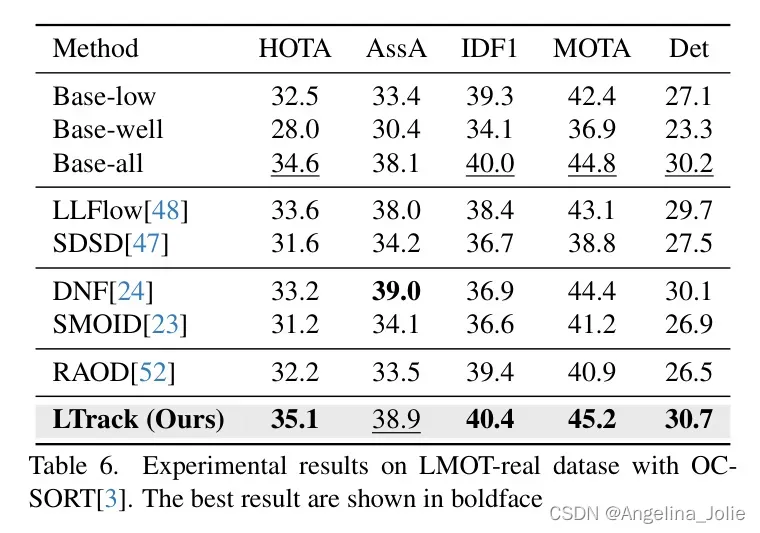
为了验证作者的方法在夜间真实世界低光照场景中的性能,作者使用OC-SORT[3]评估所有方法在LMOT-real数据集上的表现。如表6所示,所提出的LTrack比所有比较方法表现得更好。低光照增强后的跟踪方法和RAW检测方法遇到了泛化性问题,甚至不如Base-all。这强烈展示了作者LTrack在真实黑暗场景中的鲁棒性。### 探索与讨论
在本节中,作者对LMOT数据集和所提出的方法进行广泛的分析和讨论。
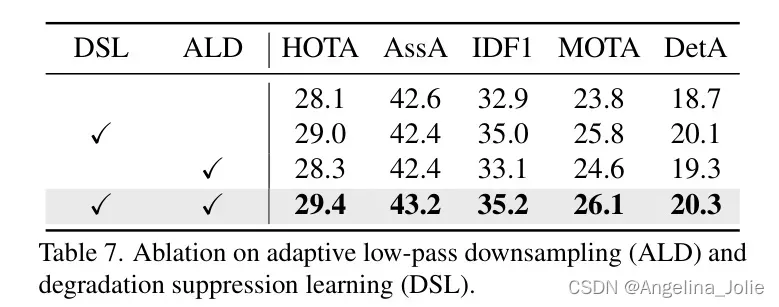
消融研究。 作者进行了消融实验以验证作者改进的有效性,结果如表7所示。可以看出,所有改进都有效地提高了性能。其中,降级抑制学习策略效果最显著,使HOTA提高了大约1个百分点。当同时采用所有策略时,取得了最佳结果。这证明了作者所有贡献的有效性。
RAW 与 sRGB。
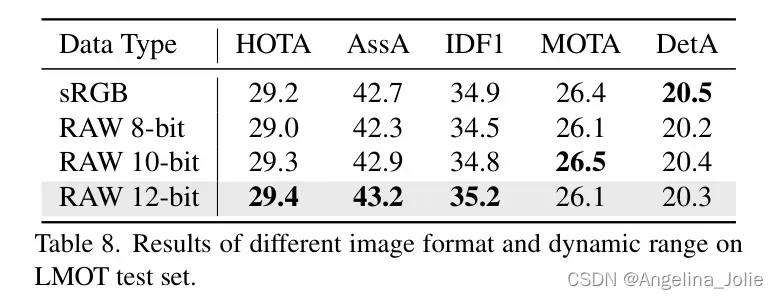
作者分析了输入数据格式的影响,结果如表8所示。12位RAW格式比sRGB格式取得了明显更好的结果。因为RAW格式保存了更多潜在的信息,有助于低光照场景下的多目标跟踪。作者还观察到,更高的位宽对性能有益,这在其他视觉任务[21, 52]中也已观察到。
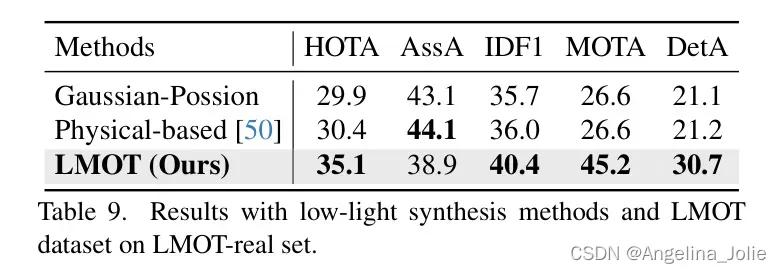
LMOT 与 合成数据。 作者将作者的LMOT数据集与合成的低光照数据进行比较,以进一步证明LMOT的价值。作者应用基于高斯-泊松和基于物理[50]的低光照数据合成方法,从良好光照视频中合成低光照视频。作者在这些数据上训练作者的LTrack,并在LMOT-real的真实低光照场景中评估它们的性能。如表9所示,在LMOT数据集上训练的跟踪器在真实夜间场景中具有更好的性能,这强烈证明了作者LMOT数据集的价值。
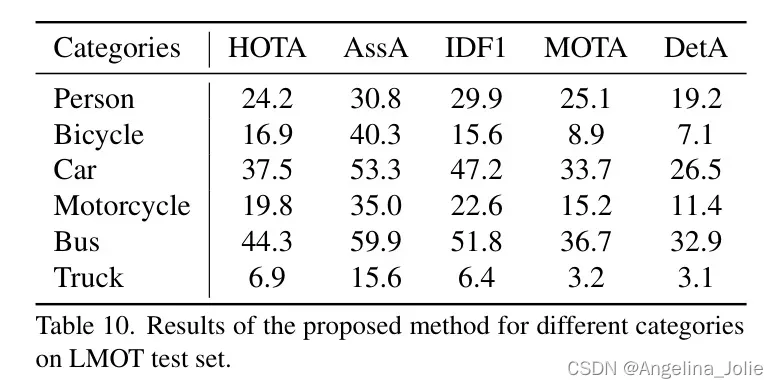
不同类别的分析。 作者还分析了不同类别的性能。从表10中可以看出,汽车和公交车取得了最佳性能,因为它们具有规则的形状和更大的面积。卡车的性能最差,因为它们的实例最少,使得模型难以学习准确的识别。人的得分相对平均。自行车和摩托车得分接近,因为它们具有相似的外观和运动模式。
6 Conclusion
在本工作中,作者研究了暗场景下的多目标跟踪。作者构建了一个新的低光多目标跟踪(LMOT)数据集,该数据集提供了良好对齐的低光视频对和高质量的多目标跟踪标注。作者观察到,低光图像受到传感器的噪声显著影响,这也会降低特征图的质量,显著恶化模型性能。为了在噪声干扰和质量退化下学习不变的语义结构,作者提出了自适应低通下采样模块和退化抑制学习。这些改进大大增强了作者方法在现实低光场景中的鲁棒性。
局限性。作者关注暗场景下的多目标跟踪。但作者没有考虑现实世界中的其他退化环境,比如雨天和雾天。在未来的工作中,作者将考虑探索更多现实世界场景中的多目标跟踪,推动MOT在现实应用中的发展。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









