







目录
引言
趋势一:从专用到通用-预训练大模型和智能代理
(1)预训练语言模型
(2)视觉和多模态预训练
(3)预训练模型的应用
(4)AI Agent
趋势二:从能力对齐到价值对齐-可信与对齐
(1)可信:小模型时代的价值对齐
(2)大模型时代的价值对齐
趋势三:从设计目标到学习目标-预训练+强化学习
(1)预训练获得基础能力,强化学习进行价值对齐
(2)预训练模仿人类,强化学习超越人类
展望
(1)“真”多模态:从微调回归预训练
(2)系统一 vs. 系统二
(3)基于交互的理解和学习
(4)超级智能 vs 超级对齐
引言
1956年的达特茅斯会议将“人工智能”定义为“使机器能够模拟人类进行感知、认知、决策、执行的一系列人工程序或系统”。这一定义催生了模仿人类智能的两种思路-逻辑演绎和归纳总结,它们分别启发了人工智能发展的两个重要阶段:(1)1960至1990年,以逻辑为基础、侧重知识表达与推理的知识工程方法;(2)1990年之后,以概率为基础、强调模型构建、学习和计算的机器学习方法。
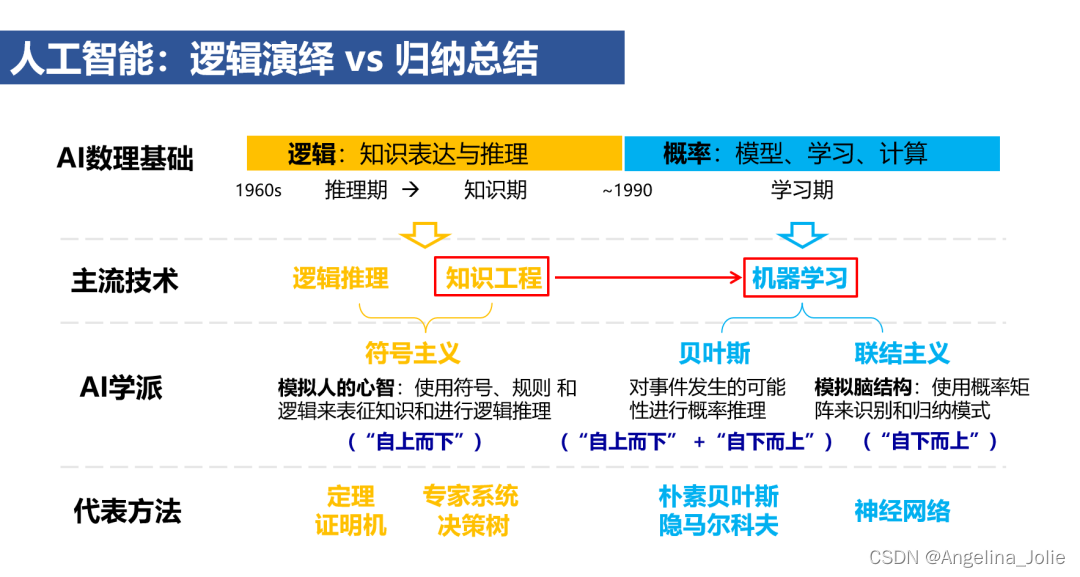
经过30多年的发展,机器学习方法大致经历了三个阶段:1990-2010年依赖手工设计特征的传统机器学习、2010-2020年从低层到高层进行监督表示学习的(传统)深度学习,以及2020年以后基于大规模无标注数据进行自监督学习的预训练大模型。围绕以预训练大模型为中心的第三代机器学习,下面探讨人工智能发展的三个趋势和对未来的四点展望。

趋势一:从专用到通用-预训练大模型和智能代理
以中英翻译任务为例,知识工程方法需要语言学家来编写规则库,传统机器学习和深度学习基于语料学习概率模型或进行模型微调。这些方法都为特定的机器翻译任务而设计。然而,今天的同一个大语言模型不仅可以翻译几十种语言,还能处理问答、摘要、写作等不同的自然语言理解和生成任务。结合我自己的研究经历,芮勇老师在2017年提出了隐喻图像理解的认知挑战(将”大象”与“共和党”建立联系,从而理解图像对美国政治的讨论)。我们在2019年通过多个专用小模型流水线式(本义概念检测-本义引申义概念映射-隐喻描述生成)的方式尝试进行了解决。而到了2023年,只需要一句简短的提示词,GPT-4V就能非常准确地理解图像背后的政治隐喻含义。
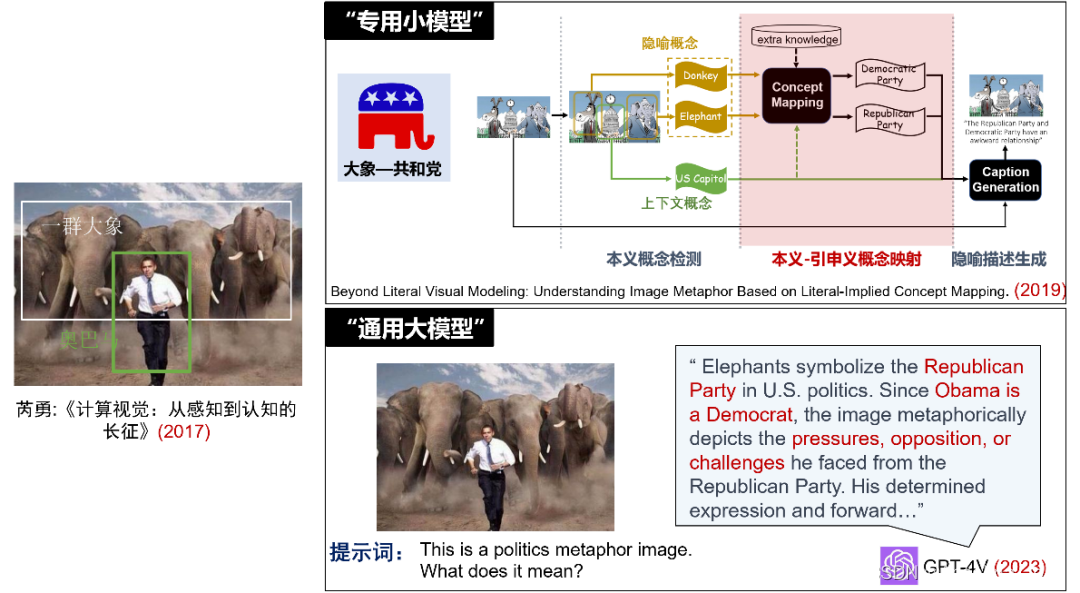
小模型的“专用” vs 大模型的“通用”
预训练大模型采用的大规模预训练技术与早期深度学习中的逐层预训练技术,虽然都基于无标注数据来学习特征表示,但在训练方法、预训练任务、模型架构、功能实现、起源以及资源需求等方面存在很大差异。从起源来看,逐层预训练技术最初应用于计算机视觉领域,旨在学习图像的视觉特征表示。而大规模预训练技术的起点是自然语言处理领域的语言模型NNLM和Word2Vec。
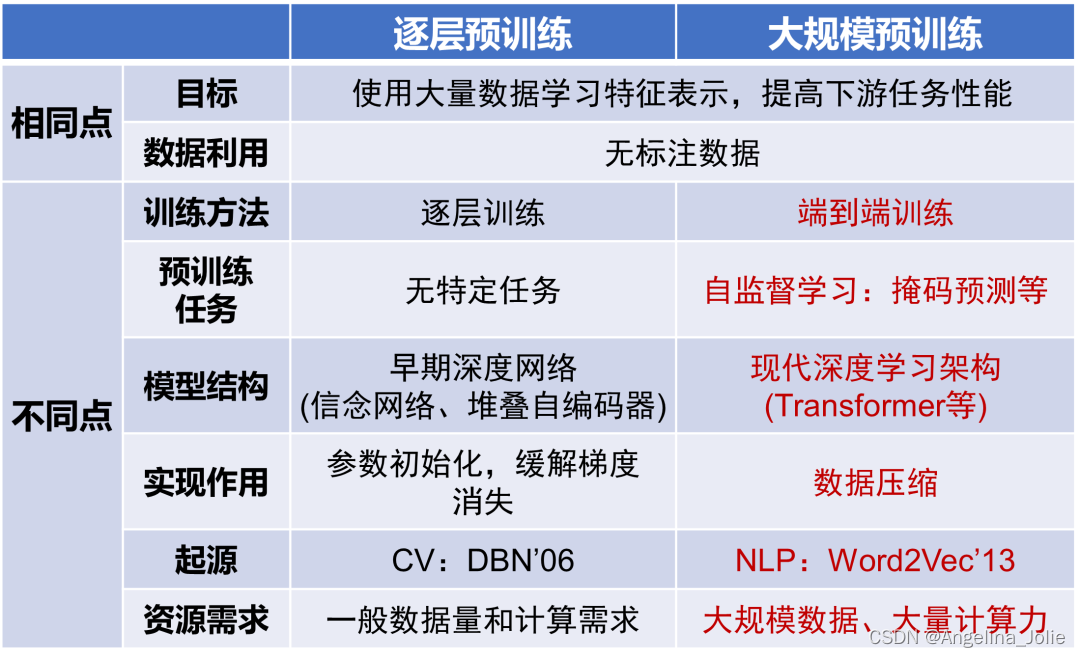
逐层预训练 vs. 大规模预训练
-
(1)预训练语言模型
语言模型的核心是计算一段文本序列出现的概率,大致经历了统计语言模型、神经语言模型和预训练语言模型几个发展阶段。与基于静态词向量的神经语言模型(如Word2Vec)不同,自ELMo模型起,预训练语言模型开始学习能够感知上下文的动态词表示,从而可以更准确地预测文本序列的概率。在序列处理单元的发展上,从RNN到LSTM,再到Self-Attention,逐步解决了长序列预测和并行计算的问题。因此,预训练语言模型得以在大规模无标注的样本上进行高效学习。根据算力、数据量、模型规模之间关系的scaling law,目前预训练语言模型的性能提升还没有触及天花板。
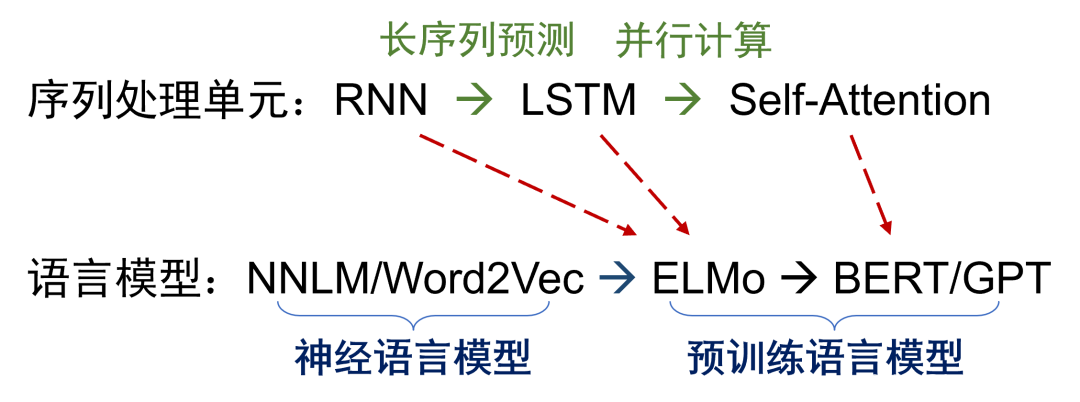
序列处理单元和语言模型的发展
-
(2)视觉和多模态预训练
预训练语言模型的成功给计算机视觉领域带来了两个启示:一是利用无标注样本进行自监督学习,二是学习能够适应多种任务的通用表示。从iGPT、Vision Transformer、BEiT、MAE到Swin Transformer,自注意力机制的计算资源消耗、局部结构信息保持等问题被逐步解决,推动了视觉预训练模型的发展。
多模态预训练模拟了人类理解物理世界的多模态过程。将大语言模型比作机器的大脑,多模态则为其提供了感知物理世界的眼睛和耳朵,可以极大扩展机器的感知和理解范围。多模态预训练的核心问题是如何有效实现不同模态之间的对齐。根据模态对齐策略的不同,多模态预训练大致经历了多模态联合预训练模型和多模态大语言模型两个阶段。早期模型并行处理不同模态的数据进行预训练,主要技术包括单模态局部特征提取、模态对齐增强、跨模态对比学习等。其中CLIP通过在4亿图文对上进行对比学习,成功打通了语言和视觉模态。自2023年起,LLaVa、Mini-GPT、GPT-4V等在大语言模型的基础上,通过微调来融合其他模态数据,从而继承了语言模型中丰富的世界知识和优秀的交互能力。谷歌的Gemini模型则重新采用了联合预训练的多模态架构。最近,随着LVM、VideoPoet和Sora等新模型的出现,多模态预训练呈现出如下趋势:(1)重视语言模型在多模态理解和生成的作用;(2)通常包含多模态编码、跨模态对齐和多模态解码三个关键模块;(3)跨模态对齐趋向于采用Transformer架构、模型采用自回归(VideoPoet)或扩散(Sora)方法。
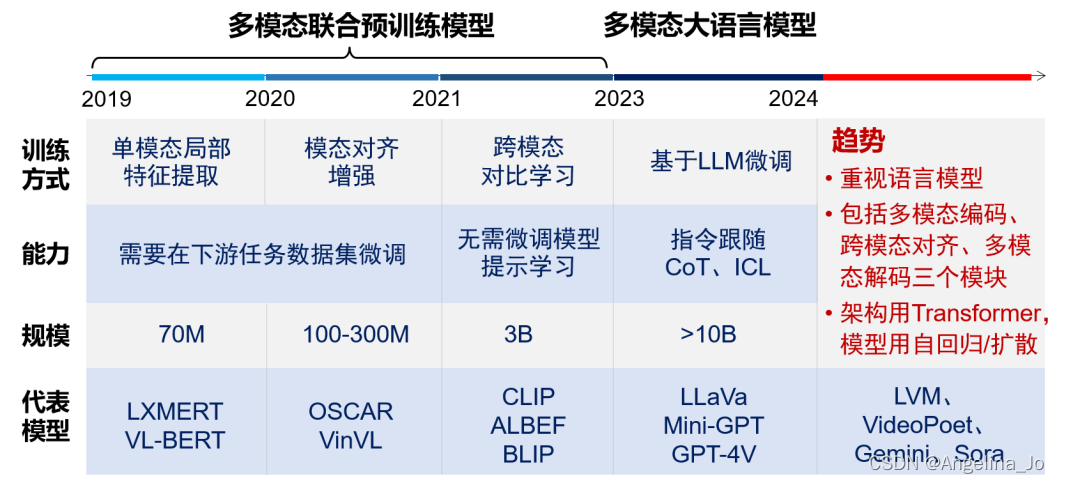
多模态预训练模型架构的演变
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1598
1598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









