







Motivation:
以往大多数中文分词的方法都是基于系列标注任务,这需要建立复杂的特征表示才能从句子中抽取单词。为了避免建立复杂的特征表示,最近的研究都是集中于用神经网络自行学习分词信息。然而在使用一般的RNN进行中文分词时,之前学到的记忆可能会被冲淡,因此本文引入LSTM解决长时间依赖问题。
实现功能:
在用神经网络进行中文分词时,输入的是一个句子,输出是每个字符对应的标签{B,M,E,S}。B代表开始,M代表中间字符,E代表结束,S代表单个字符。例如:输入“要全面建成小康社会”,输出“SBEBEBMME”。
具体步骤:
假设窗口大小为5,对于边界字符用”start”或”end”填充,以“要全面建成小康社会”为例介绍模型主要构成。
- 字符嵌入层:设置一个嵌入矩阵(大小:d×c,d:嵌入维度,c:训练集中不同字符数,训练集中未出现过的字符映射到没使用过的特殊表示),查询“start | start | 要 | 全 | 面”这5个字符所对应的向量。然后拼接在一起,用x0表示,大小为5d。
- LSTM层:将x0输入到LSTM,输出网络的隐藏状态h0,大小为H(超参数)。
四种LSTM结构:

3. 标签推理层(线性层):LSTM层的输出H作为输出,通过线性变换输出“要”字对应的标签(大小为4)。

实验结果:
对比四种LSTM网络发现:在训练了60个epochs之后,LSTM-1能够达到最优的效果。为了达到最优的效果,用不同的Dropout rate和上下文窗口(Context Length)探究LSTM-1表现,结果发现Dropout rate=20%,上下文窗口(0,2)时效果最好。
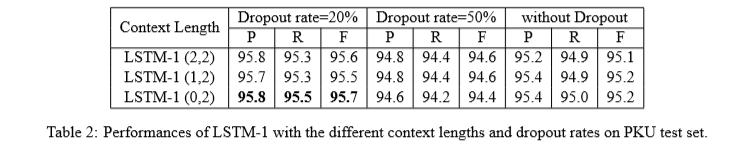
启发:
- LSTM利用上文信息,要利用双向信息使用BiLSTM;
- 和随机初始化字符向量相比,使用预训练的字符向量和二元字符合并成一个向量能够实现更好的效果;
- 本文滑动窗口是(0,2)时效果最好,可能因为LSTM默认考虑的上文,而(0,2)弥补了考虑下文信息。















 964
964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









