







 本文介绍了Apollo项目,旨在开发六种广泛使用的语言的医学LLM,以促进医疗AI在医疗资源匮乏地区的普及。Apollo-7B是目前最先进的多语言医疗模型,且小型模型可用于提升大模型的多语言医疗能力,所有资源将开源提供。
本文介绍了Apollo项目,旨在开发六种广泛使用的语言的医学LLM,以促进医疗AI在医疗资源匮乏地区的普及。Apollo-7B是目前最先进的多语言医疗模型,且小型模型可用于提升大模型的多语言医疗能力,所有资源将开源提供。
Apollo: Lightweight Multilingual Medical LLMs towards Democratizing Medical AI to 6B People 轻量级多语种医学 LLMs

Abstract
Despite the vast repository of global medical knowledge predominantly being in English, local languages are crucial for delivering tailored healthcare services, particularly in areas with limited medical resources. To extend the reach of medical AI advancements to a broader population, we aim to develop medical LLMs across the six most widely spoken languages, encompassing a global population of 6.1 billion. This effort culminates in the creation of the ApolloCorpora multilingual medical dataset and the XMedBench benchmark. In the multilingual medical benchmark, the released Apollo models, at various relatively-small sizes (i.e., 0.5B, 1.8B, 2B, 6B, and 7B), achieve the best performance among models of equivalent size. Especially, Apollo-7B is the state-of-the-art multilingual medical LLMs up to 70B. Additionally, these lite models could be used to improve the multi-lingual medical capabilities of larger models without fine-tuning in a proxy-tuning fashion. We will open-source training corpora, code, model weights and evaluation benchmark.
尽管庞大的全球医学知识库以英语为主,但当地语言对于提供量身定制的医疗保健服务至关重要,尤其是在医疗资源有限的地区。为了将医学人工智能的进步推广到更广泛的人群中,我们致力于开发六种语言的医学 LLM,涵盖全球61 亿人口。最终,我们创建了 ApolloCorpora 多语种医疗数据集和 XMedBench 基准。在多语言医疗基准测试中,已发布的 Apollo 模型在各种相对较小的规模(即 0.5B、1.8B、2B、6B 和 7B)下,在同等规模的模型中取得了最佳性能。特别是阿波罗-7B,它是最大可达 70B 的最先进的多语言医学 LLM。此外,这些精简模型还可用于提高大型模型的多语言医疗能力,而无需以代理调整的方式进行微调。我们将开源训练语料、代码、模型权重和评估基准。
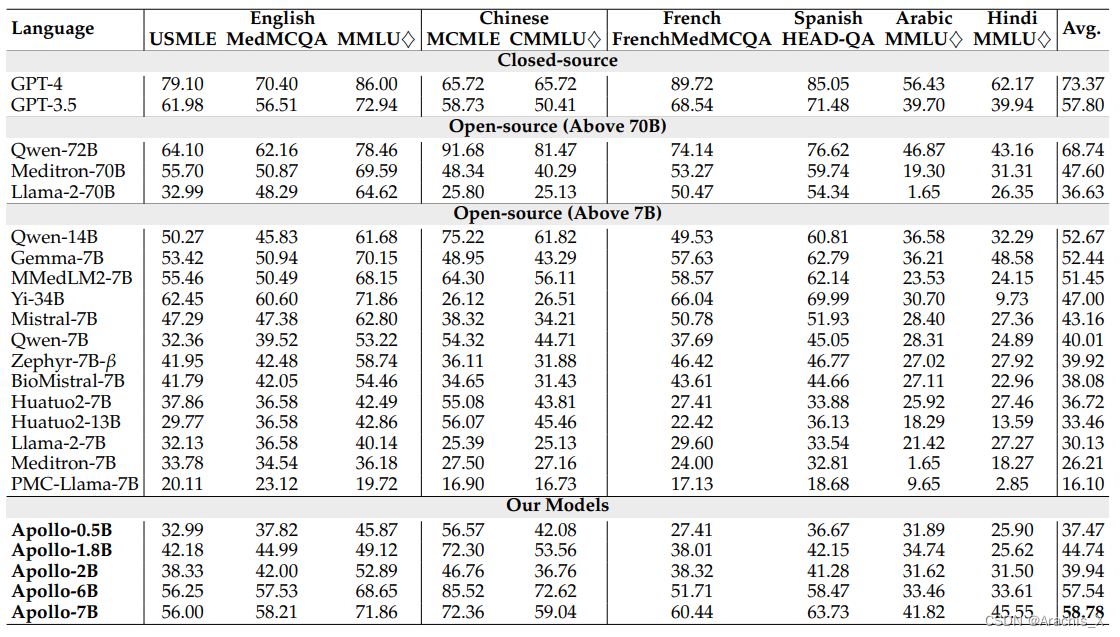
Results


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









