







 本文详细回顾了RAG技术在AIGC中的应用,探讨了其如何通过信息检索提升准确性与鲁棒性。文章分类了RAG基础、概述了增强方法和应用领域,同时指出了当前系统的局限及未来研究方向。
本文详细回顾了RAG技术在AIGC中的应用,探讨了其如何通过信息检索提升准确性与鲁棒性。文章分类了RAG基础、概述了增强方法和应用领域,同时指出了当前系统的局限及未来研究方向。
Retrieval-Augmented Generation for AI-Generated Content: A Survey 人工智能生成内容的检索增强生成综述
论文地址
github地址
最新RAG综述来了!北京大学发布AIGC的检索增强技术综述!


Abstract
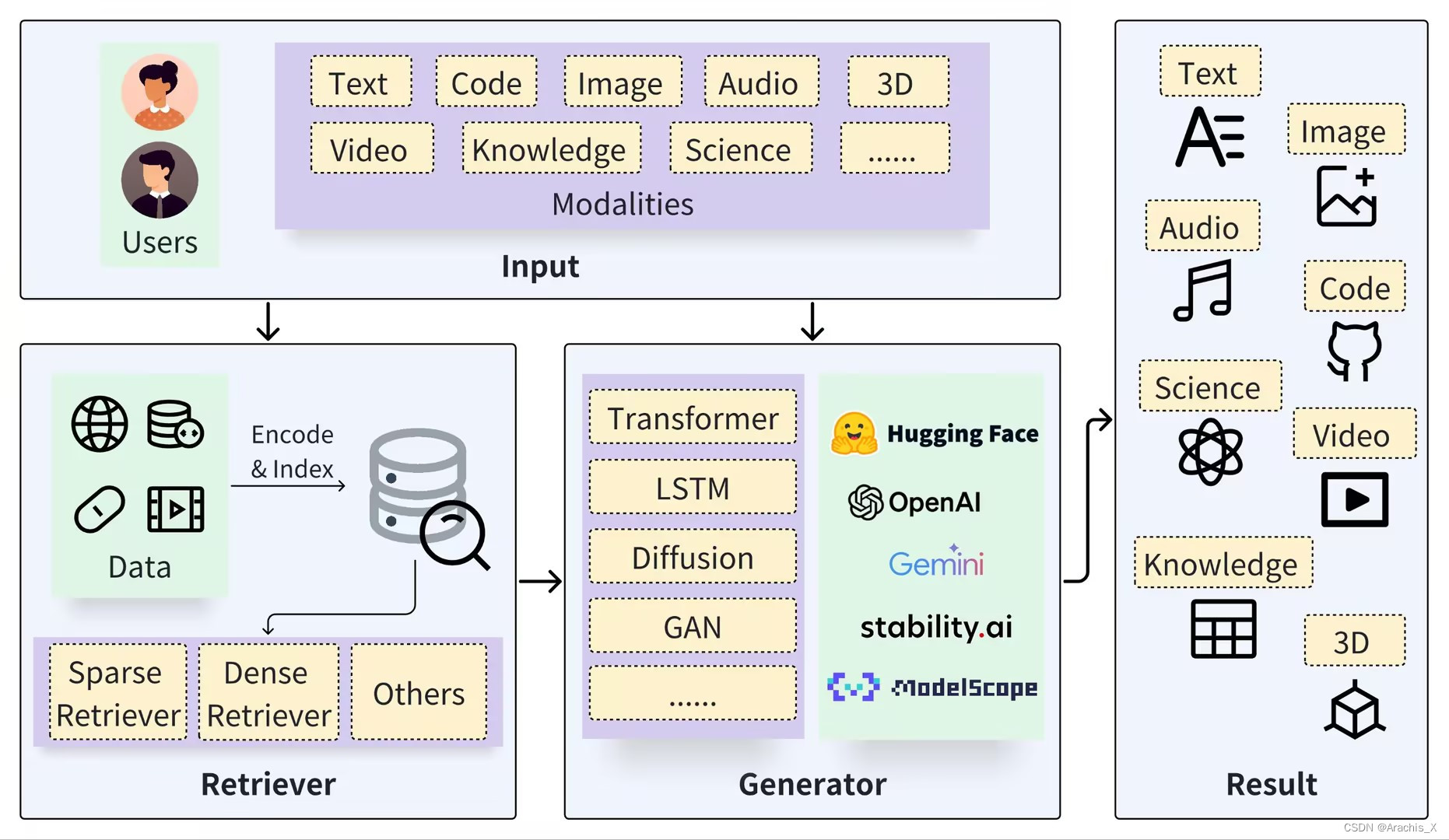
The development of Artificial Intelligence Generated Content (AIGC) has been facilitated by advancements in model algorithms, scalable foundation model architectures, and the availability of ample high-quality datasets. While AIGC has achieved remarkable performance, it still faces challenges, such as the difficulty of maintaining up-to-date and long-tail knowledge, the risk of data leakage, and the high costs associated with training and inference. Retrieval-Augmented Generation (RAG) has recently emerged as a paradigm to address such challenges. In particular, RAG introduces the information retrieval process, which enhances AIGC results by retrieving relevant objects from available data stores, leading to greater accuracy and robustness. In this paper, we comprehensively review existing efforts that integrate RAG technique into AIGC scenarios. We first classify RAG foundations according to how the retriever augments the generator. We distill the fundamental abstractions of the augmentation methodologies for various retrievers and generators. This unified perspective encompasses all RAG scenarios, illuminating advancements and pivotal technologies that help with potential future progress. We also summarize additional enhancements methods for RAG, facilitating effective engineering and implementation of RAG systems. Then from another view, we survey on practical applications of RAG across different modalities and tasks, offering valuable references for researchers and practitioners. Furthermore, we introduce the benchmarks for RAG, discuss the limitations of current RAG systems, and suggest potential directions for future research. Project: https://github.com/hymie122/RAG-Survey
人工智能生成内容(AIGC)的发展得益于模型算法的进步、可扩展的基础模型架构以及大量高质量数据集的可用性。
虽然 AIGC 已经取得了令人瞩目的成绩,但它仍然面临着各种挑战,例如难以维护最新的长尾知识、数据泄漏的风险以及与训练和推理相关的高昂成本。
检索增强生成(RAG)是最近出现的一种应对这些挑战的范例。特别是,RAG 引入了信息检索过程,通过从可用数据存储中检索相关对象来增强 AIGC 结果,从而提高准确性和鲁棒性。
在本文中,我们全面回顾了将 RAG 技术集成到 AIGC 场景中的现有工作。
- 我们首先根据检索器如何增强生成器对 RAG 基础进行分类。
- 我们为各种检索器和生成器提炼了增强方法的基本抽象。这种统一的视角涵盖了所有 RAG 场景,揭示了有助于未来潜在进展的先进技术和关键技术。
- 我们还总结了 RAG 的其他增强方法,以促进 RAG 系统的有效工程设计和实施。
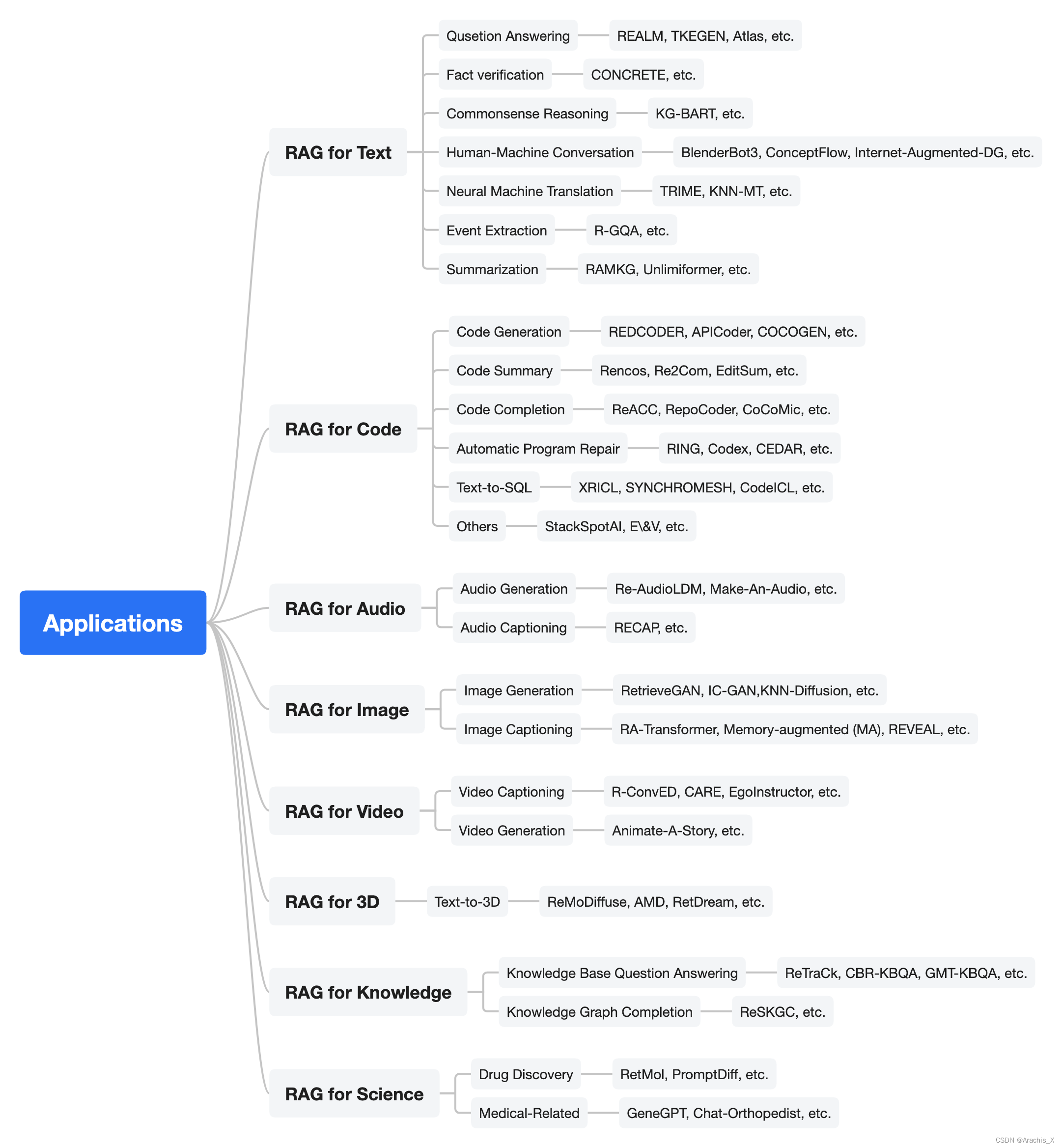
然后,我们从另一个角度考察了 RAG 在不同模式和任务中的实际应用,为研究人员和实践者提供了有价值的参考。
此外,我们还介绍了 RAG 的基准,讨论了当前 RAG 系统的局限性,并提出了未来研究的潜在方向。

















 2322
2322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









