







Sakuga-42M Dataset: Scaling Up Cartoon Research 扩大漫画研究规模
论文地址
代码地址(失效)
代码地址
Sakuga-42M结果数值对比
(paper with code)


Abstract
Hand-drawn cartoon animation employs sketches and flat-color segments to create the illusion of motion. While recent advancements like CLIP, SVD, and Sora show impressive results in understanding and generating natural video by scaling large models with extensive datasets, they are not as effective for cartoons. Through our empirical experiments, we argue that this ineffectiveness stems from a notable bias in hand-drawn cartoons that diverges from the distribution of natural videos. Can we harness the success of the scaling paradigm to benefit cartoon research? Unfortunately, until now, there has not been a sizable cartoon dataset available for exploration. In this research, we propose the Sakuga-42M Dataset, the first large-scale cartoon animation dataset. Sakuga-42M comprises 42 million keyframes covering various artistic styles, regions, and years, with comprehensive semantic annotations including video-text description pairs, anime tags, content taxonomies, etc. We pioneer the benefits of such a large-scale cartoon dataset on comprehension and generation tasks by finetuning contemporary foundation models like Video CLIP, Video Mamba, and SVD, achieving outstanding performance on cartoon-related tasks. Our motivation is to introduce large-scaling to cartoon research and foster generalization and robustness in future cartoon applications. Dataset, Code, and Pretrained Models will be publicly available.
手绘卡通动画采用草图和平面色彩片段来营造运动的错觉。虽然 CLIP、SVD 和 Sora 等最新技术通过扩展大型模型和广泛的数据集,在理解和生成自然视频方面取得了令人印象深刻的成果,但它们对动画片却不那么有效。
通过实证实验,我们认为这种无效性源于手绘卡通的明显偏差,这种偏差与自然视频的分布不同。
我们能否利用缩放范式的成功来促进卡通研究?遗憾的是,到目前为止,还没有一个相当规模的卡通数据集可供探索。
在这项研究中,我们提出了首个大规模卡通动画数据集–Sakuga-42M 数据集。Sakuga-42M 包含 4200 万个关键帧,涵盖各种艺术风格、地区和年份,并有全面的语义注释,包括视频-文本描述对、动漫标签、内容分类法等。我们通过对视频 CLIP、视频 Mamba 和 SVD 等当代基础模型进行微调,率先在理解和生成任务中利用了这种大规模的卡通数据集,在卡通相关任务中取得了出色的性能。
我们的动机是将大尺度引入卡通研究,并促进未来卡通应用的通用性和鲁棒性。数据集、代码和预训练模型将公开发布。
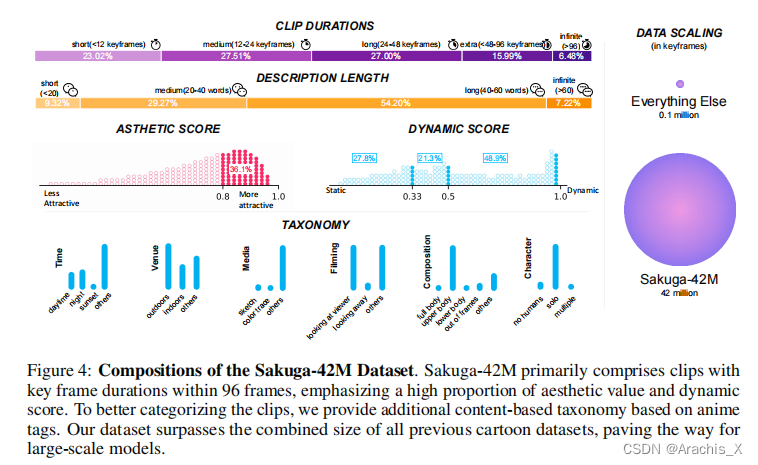
Dataset


Foundation Models
Video-Language Understanding
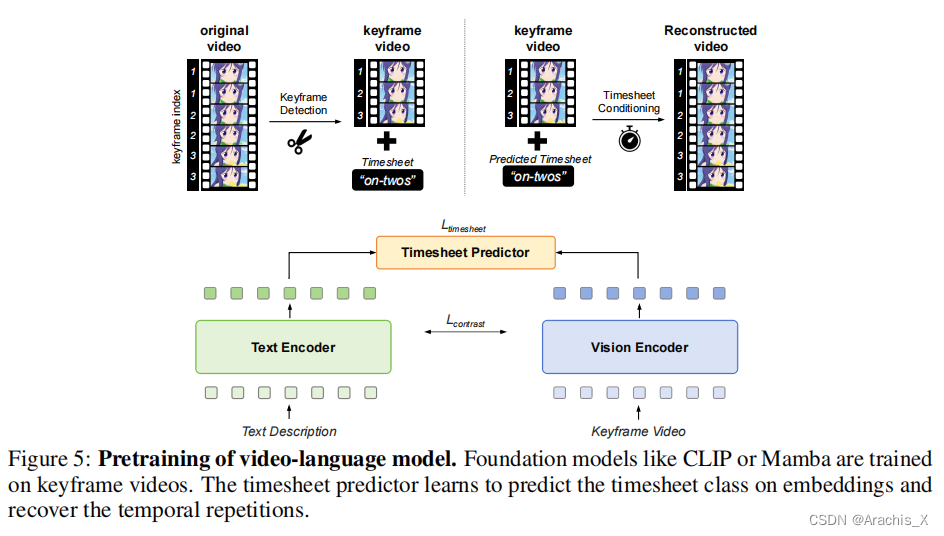
Implementation Details. ViCLIP and VideoMamba (2 NVIDIA A6000 (48G) GPUs with a batch size of 256.)
Video Generation
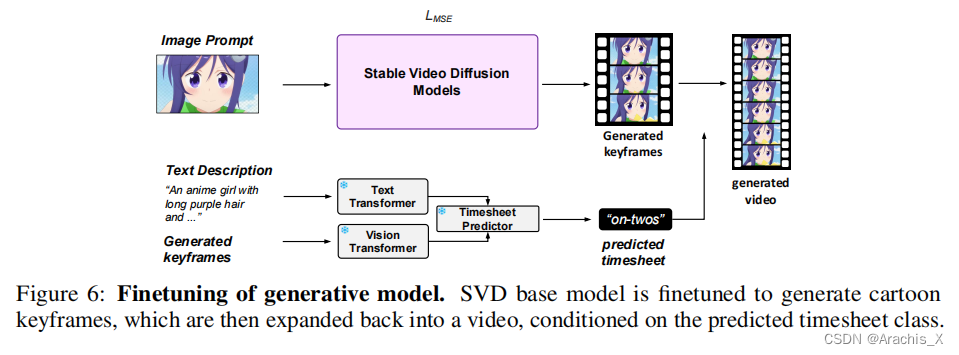
Implementation Details. finetuning process (2 NVIDIA A6000 (48G) GPUs)
Experiments
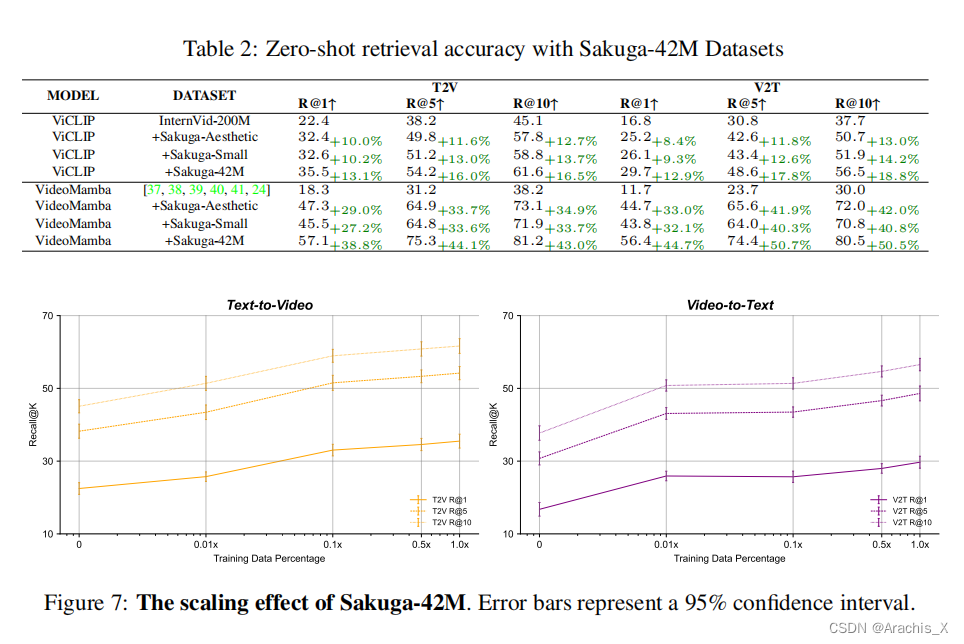
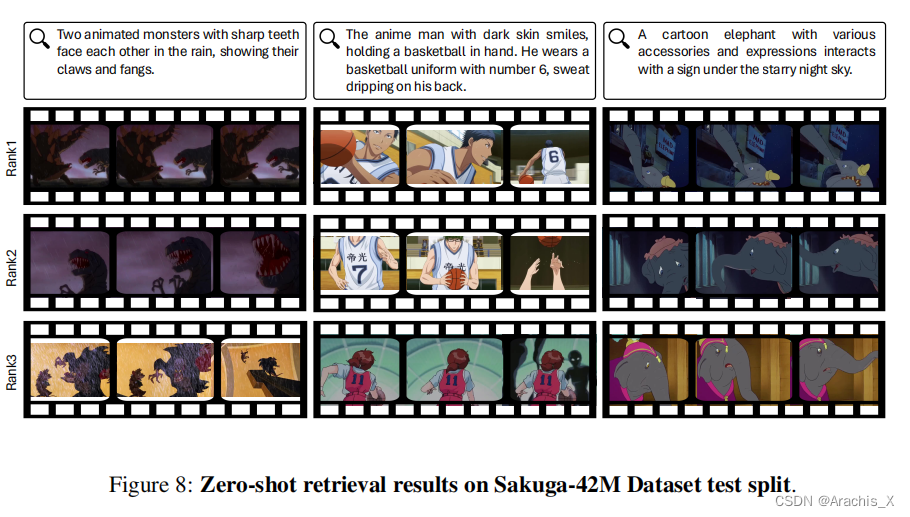

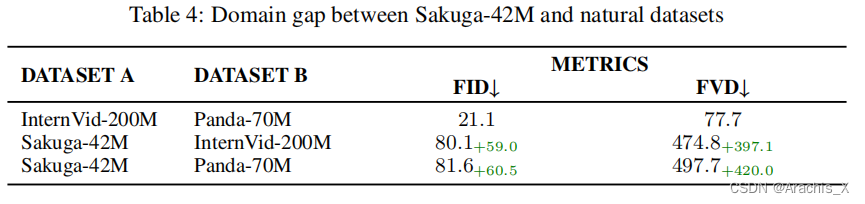
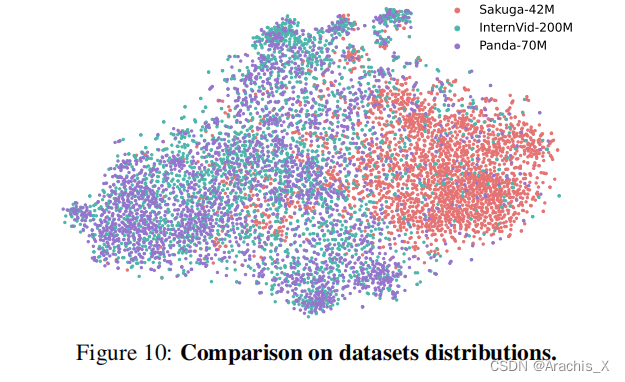
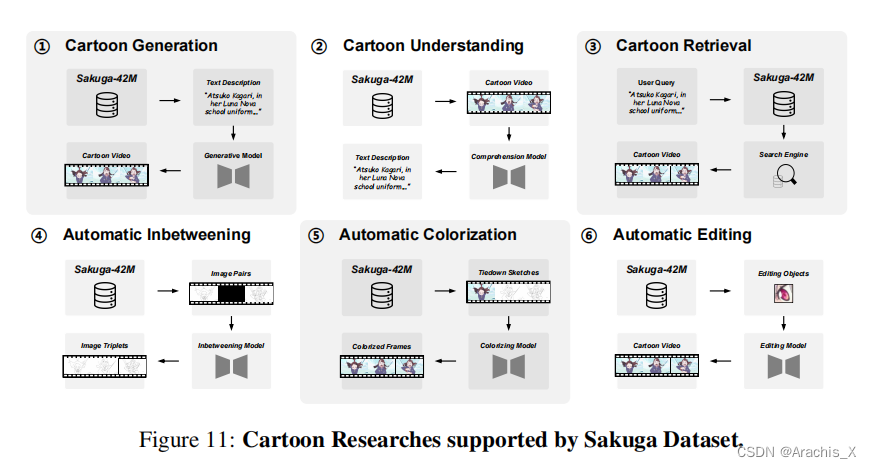

















 4508
4508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









