







 本文详细调查了大型语言模型的数据集,从预训练语料、指令微调到评估和传统NLP,揭示了其在模型发展中的关键作用。通过444个数据集的统计,展现了当前挑战和未来研究方向,为研究者提供了全面参考。
本文详细调查了大型语言模型的数据集,从预训练语料、指令微调到评估和传统NLP,揭示了其在模型发展中的关键作用。通过444个数据集的统计,展现了当前挑战和未来研究方向,为研究者提供了全面参考。
Datasets for Large Language Models: A Comprehensive Survey 大型语言模型的数据集: 全面调查
论文地址+部分数据集地址
github地址
数据集为王:大语言模型数据集综述(一)
Abstract
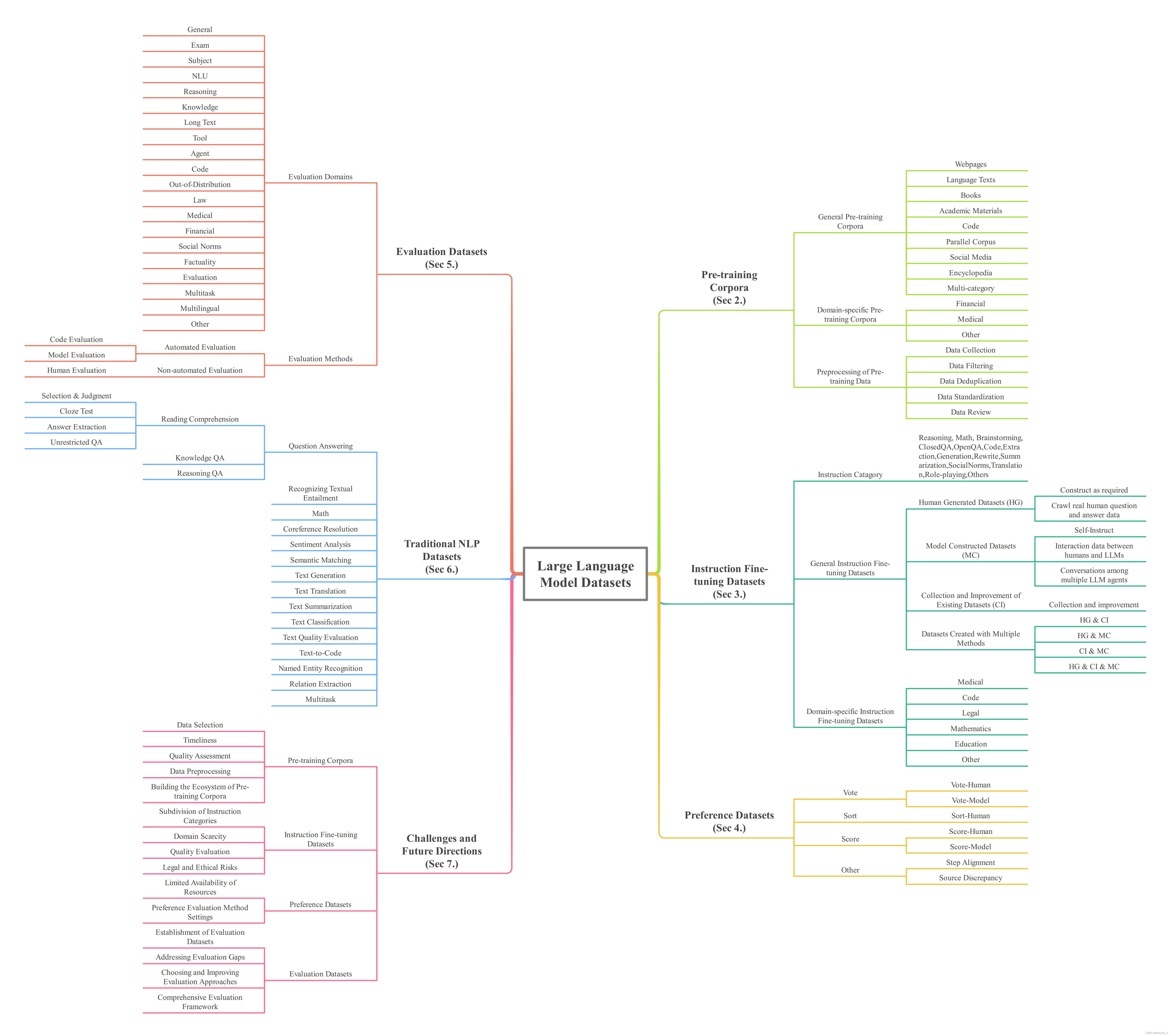
This paper embarks on an exploration into the Large Language Model (LLM) datasets, which play a crucial role in the remarkable advancements of LLMs. The datasets serve as the foundational infrastructure analogous to a root system that sustains and nurtures the development of LLMs. Consequently, examination of these datasets emerges as a critical topic in research. In order to address the current lack of a comprehensive overview and thorough analysis of LLM datasets, and to gain insights into their current status and future trends, this survey consolidates and categorizes the fundamental aspects of LLM datasets from five perspectives: (1) Pre-training Corpora; (2) Instruction Fine-tuning Datasets; (3) Preference Datasets; (4) Evaluation Datasets; (5) Traditional Natural Language Processing (NLP) Datasets. The survey sheds light on the prevailing challenges and points out potential avenues for future investigation. Additionally, a comprehensive review of the existing available dataset resources is also provided, including statistics from 444 datasets, covering 8 language categories and spanning 32 domains. Information from 20 dimensions is incorporated into the dataset statistics. The total data size surveyed surpasses 774.5 TB for pre-training corpora and 700M instances for other datasets. We aim to present the entire landscape of LLM text datasets, serving as a comprehensive reference for researchers in this field and contributing to future studies. Related resources are available at: https://github.com/lmmlzn/Awesome-LLMs-Datasets.
本文开始探索大型语言模型(LLM)数据集,这些数据集在 LLM 的显著进步中发挥着至关重要的作用。这些数据集是基础架构,类似于支撑和培育 LLM 发展的根系统。因此,对这些数据集的研究成为研究中的一个重要课题。
为了解决目前缺乏对 LLM 数据集的全面概述和透彻分析的问题,并深入了解这些数据集的现状和未来趋势,本调查从五个方面对 LLM 数据集的基本方面进行了整合和分类:
- 预训练语料库;
- 指令微调数据集;
- 偏好数据集;
- 评估数据集;
- 传统自然语言处理 (NLP) 数据集。
调查揭示了当前面临的挑战,并指出了未来研究的潜在途径。此外,还对现有的数据集资源进行了全面回顾,包括来自444 个数据集的统计数据,涵盖8 个语言类别和 32 个领域。数据集统计包含20 个维度的信息。调查的总数据量超过了 774.5 TB(预培训语料库)和 7 亿个实例(其他数据集)。
我们的目标是展示 LLM 文本数据集的全貌,为该领域的研究人员提供全面的参考,并为未来的研究做出贡献。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









