







随机森林算法详细介绍
1. 理论背景
随机森林(Random Forest)是一种由Leo Breiman和Adele Cutler在2001年提出的集成学习方法。它结合了多个决策树的预测结果,以提高模型的准确性和鲁棒性。
2. 算法细节
随机森林的构建过程可以分为以下几个步骤:
-
Bootstrap采样:从原始数据集中随机选择样本,有放回地生成多个子样本集(即每个子样本集中可能包含重复的样本)。
-
决策树构建:对每个子样本集构建一个决策树。在构建每棵决策树时,对每个节点选择的特征是从所有特征中随机选取的子集。
-
集成预测:对分类任务,通过对所有决策树的投票结果进行多数投票来确定最终的分类结果。对回归任务,通过对所有决策树的预测结果取平均值来确定最终的回归结果。
3. 算法优点
-
减少过拟合:通过对多个决策树的结果进行平均或投票,减少了单棵决策树过拟合的风险。
-
高准确率:由于结合了多个模型的预测结果,通常比单独的决策树模型具有更高的预测准确性。
-
处理高维数据:能够处理含有大量特征的数据,并能有效地进行特征选择。
-
抗噪声能力强:由于集成了多个决策树的结果,对噪声数据具有较好的鲁棒性。
Python实现与可视化示例
下面是一个详细的Python示例,展示如何使用随机森林算法进行泰坦尼克号数据集的分类任务。泰坦尼克号数据集(Titanic Dataset)是机器学习领域中常用的经典数据集之一,广泛用于分类模型的训练和测试。这个数据集记录了泰坦尼克号1912年沉船事故中的乘客信息和他们的生还情况。通过分析这些数据,机器学习模型可以预测某个乘客是否在事故中幸存。泰坦尼克号数据集通常包括以下几个文件:train.csv:训练数据集,用于模型训练test.csv:测试数据集,用于模型测试;gender_submission.csv:提交格式示例,展示提交预测结果的格式。
数据集中包含多个特征,每个特征描述了乘客的不同方面:
-
PassengerId:乘客ID,唯一标识每个乘客。
-
Survived:生还情况(0 = 未生还,1 = 生还)。
-
Pclass:客舱等级(1 = 头等舱,2 = 二等舱,3 = 三等舱)。
-
Name:乘客姓名。
-
Sex:性别(male = 男性,female = 女性)。
-
Age:年龄。
-
SibSp:在船上的兄弟姐妹/配偶数量。
-
Parch:在船上的父母/子女数量。
-
Ticket:船票号码。
-
Fare:票价。
-
Cabin:客舱号。
-
Embarked:登船港口(C = Cherbourg, Q = Queenstown, S = Southampton)。
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import RandomForestClassifier # 导入随机森林分类器
from sklearn.model_selection import train_test_split # 导入数据集划分工具
from sklearn.metrics import classification_report, confusion_matrix, roc_curve, auc # 导入评估工具
from sklearn.preprocessing import LabelEncoder # 导入标签编码器
from sklearn.manifold import TSNE # 导入t-SNE降维工具
# 加载数据
train = pd.read_csv('Titanic_train.csv') # 读取训练数据集
test = pd.read_csv('Titanic_test.csv') # 读取测试数据集
# 数据预处理
def preprocess_data(df):
df['Age'].fillna(df['Age'].median(), inplace=True) # 填充缺失的年龄数据为中位数
df['Embarked'].fillna(df['Embarked'].mode()[0], inplace=True) # 填充缺失的登船港口为众数
df['Fare'].fillna(df['Fare'].median(), inplace=True) # 填充缺失的票价为中位数
df.drop(['Cabin', 'Ticket', 'Name'], axis=1, inplace=True) # 删除不必要的特征
df['Sex'] = LabelEncoder().fit_transform(df['Sex']) # 将性别转换为数值
df['Embarked'] = LabelEncoder().fit_transform(df['Embarked']) # 将登船港口转换为数值
return df
train = preprocess_data(train) # 预处理训练数据
test = preprocess_data(test) # 预处理测试数据
# 特征和标签
X = train.drop('Survived', axis=1) # 提取特征变量
y = train['Survived'] # 提取标签变量
# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 将数据集划分为训练集和测试集
# 随机森林模型
clf = RandomForestClassifier(n_estimators=100, random_state=42) # 初始化随机森林分类器
clf.fit(X_train, y_train) # 训练模型
# 预测
y_pred = clf.predict(X_test) # 对测试集进行预测
# 结果评估
print("Classification Report:")
print(classification_report(y_test, y_pred)) # 打印分类报告
# 混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred) # 计算混淆矩阵
print("Confusion Matrix:")
print(conf_matrix) # 打印混淆矩阵
# 特征重要性
importances = clf.feature_importances_ # 获取特征重要性
indices = np.argsort(importances)[::-1] # 按重要性排序
feature_names = X.columns # 获取特征名称
# 可视化特征重要性
plt.figure(figsize=(10, 6))
plt.title("Feature Importances")
plt.bar(range(X.shape[1]), importances[indices], align="center")
plt.xticks(range(X.shape[1]), [feature_names[i] for i in indices], rotation=45)
plt.xlabel("Feature")
plt.ylabel("Importance")
plt.show() # 显示特征重要性图
# ROC曲线
y_score = clf.predict_proba(X_test)[:, 1] # 获取预测概率
fpr, tpr, _ = roc_curve(y_test, y_score) # 计算ROC曲线
roc_auc = auc(fpr, tpr) # 计算AUC
plt.figure(figsize=(10, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show() # 显示ROC曲线
# t-SNE图
tsne = TSNE(n_components=2, random_state=42) # 初始化t-SNE
X_tsne = tsne.fit_transform(X_test) # 对测试集特征进行降维
plt.figure(figsize=(10, 6))
scatter = plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y_test, cmap='viridis') # 绘制t-SNE图
plt.legend(*scatter.legend_elements(), title="Classes")
plt.title("t-SNE visualization")
plt.xlabel("t-SNE component 1")
plt.ylabel("t-SNE component 2")
plt.show() # 显示t-SNE图
# 输出:
"""
Classification Report:
precision recall f1-score support
0 0.81 0.90 0.85 157
1 0.83 0.70 0.76 111
accuracy 0.82 268
macro avg 0.82 0.80 0.81 268
weighted avg 0.82 0.82 0.81 268
Confusion Matrix:
[[141 16]
[ 33 78]]
"""
输出结果分类报告中的各项指标包括精确率(precision)、召回率(recall)、F1分数(f1-score)和支持(support)。这些指标可以帮助我们全面评估模型的性能。
Classification Report:
precision recall f1-score support
0 0.81 0.90 0.85 157
1 0.83 0.70 0.76 111
accuracy 0.82 268
macro avg 0.82 0.80 0.81 268
weighted avg 0.82 0.82 0.81 268
各项指标解释
-
精确率(Precision):
-
定义:精确率是正确预测的正样本数占所有预测为正的样本数的比例。
-
计算公式:Precision=TPTP+FPPrecision=TP+FPTP
-
解释:模型在预测某一类(例如幸存者)时,预测正确的比例。对于0类(未幸存者),精确率是0.81;对于1类(幸存者),精确率是0.83。
-
-
召回率(Recall):
-
定义:召回率是正确预测的正样本数占所有实际为正的样本数的比例。
-
计算公式:Recall=TPTP+FNRecall=TP+FNTP
-
解释:模型在预测某一类时,能够正确识别的比例。对于0类,召回率是0.90;对于1类,召回率是0.70。
-
-
F1分数(F1-Score):
-
定义:F1分数是精确率和召回率的调和平均数。
-
计算公式:F1-Score=2×Precision×RecallPrecision+RecallF1-Score=2×Precision+RecallPrecision×Recall
-
解释:F1分数综合考虑了精确率和召回率,提供了一个平衡的性能评估。对于0类,F1分数是0.85;对于1类,F1分数是0.76。
-
-
支持(Support):
-
定义:支持是每个类别中的实际样本数。
-
解释:支持表示的是数据集中每个类别的样本数。0类有157个样本,1类有111个样本。
-
整体性能指标
-
准确率(Accuracy):
-
定义:准确率是正确预测的样本数占总样本数的比例。
-
计算公式:Accuracy=TP+TNTP+TN+FP+FNAccuracy=TP+TN+FP+FNTP+TN
-
解释:在所有样本中,模型正确预测的比例。这里准确率是0.82(即82%的样本被正确分类)。
-
-
宏平均(Macro Avg):
-
定义:宏平均是对各类别的指标进行简单平均,不考虑类别的样本数。
-
解释:提供了各类别性能指标的整体平均值。这里宏平均的精确率是0.82,召回率是0.80,F1分数是0.81。
-
-
加权平均(Weighted Avg):
-
定义:加权平均是对各类别的指标按其样本数进行加权平均。
-
解释:考虑类别样本数后的性能指标平均值。这里加权平均的精确率是0.82,召回率是0.82,F1分数是0.81。
-
混淆矩阵解释
Confusion Matrix:
[[141 16]
[ 33 78]]
混淆矩阵显示了实际标签与预测标签的对比。
-
第一行表示实际为0类(未幸存者)的样本:
-
141:实际为0类且预测为0类(真正例,True Negative, TN)。
-
16:实际为0类但预测为1类(假阳性,False Positive, FP)。
-
-
第二行表示实际为1类(幸存者)的样本:
-
33:实际为1类但预测为0类(假阴性,False Negative, FN)。
-
78:实际为1类且预测为1类(真阳性,True Positive, TP)。
-
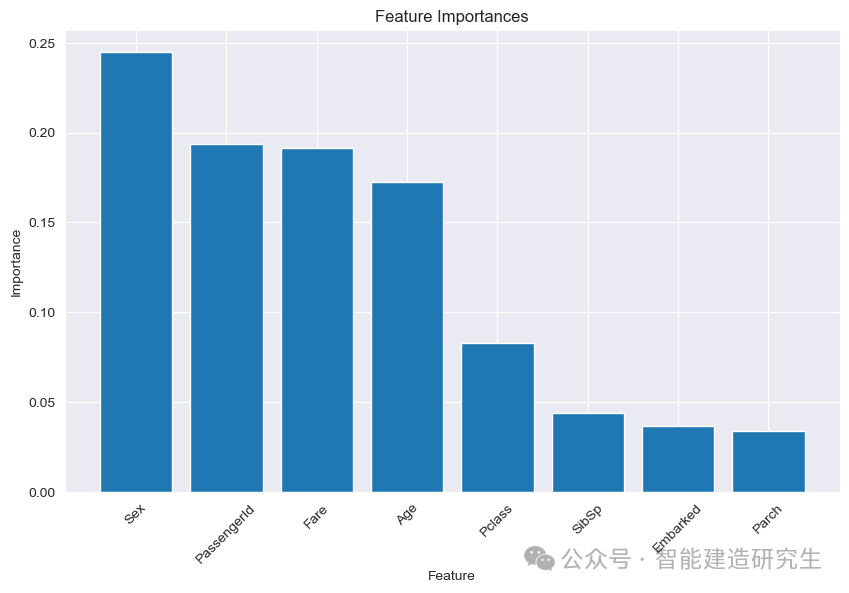
特征重要性解释
-
解释:特征重要性图显示了每个特征在模型中的重要性。通过这个图,我们可以看到哪些特征对模型的预测影响最大。对于泰坦尼克号数据集,性别(Sex)、乘客ID(PassengerId)、票价(Fare)和年龄(Age)可能是最重要的特征,因为这些因素在实际的生存情况中也是重要的。
-
重要性:这种可视化帮助我们理解模型的决策过程,并提供关于数据特征的重要性的信息。
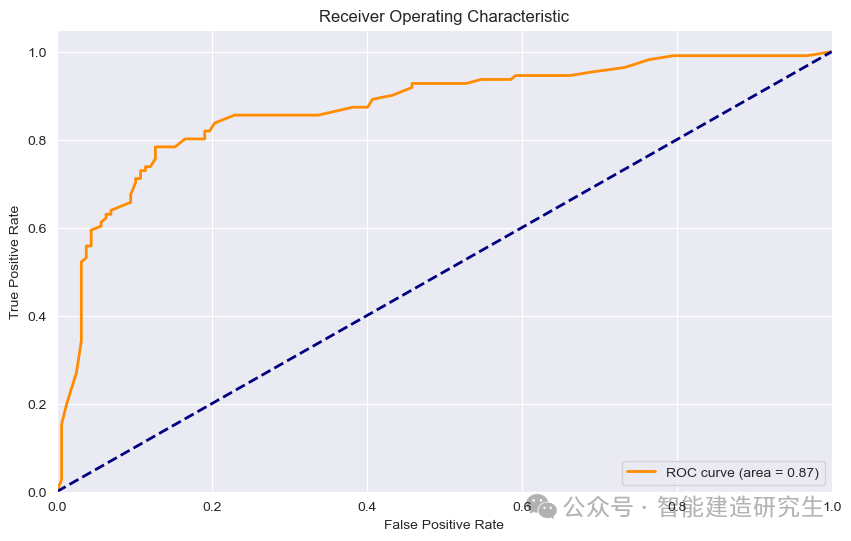
ROC曲线解释
-
解释:ROC(Receiver Operating Characteristic)曲线是评估分类模型性能的常用工具,特别是在不平衡数据集上。它展示了模型在不同阈值下的真阳性率(True Positive Rate, TPR)和假阳性率(False Positive Rate, FPR)之间的关系。曲线下的面积(AUC, Area Under Curve)用于量化模型的总体性能。
-
重要性:ROC曲线提供了一个整体的模型性能评估,特别是在不平衡数据集上,它可以展示模型在不同阈值下的表现。
-
模型性能良好:
-
该模型的AUC值为0.87,接近1,说明模型在区分泰坦尼克号数据集中幸存者和未幸存者时表现较好。
-
TPR较高,意味着模型能够正确识别大部分幸存者(正样本)。
-
t-SNE图解释
-
解释:t-SNE图是一种降维可视化方法,将高维数据投影到2维平面上。通过颜色表示不同类别的数据点(幸存者和未幸存者)。在泰坦尼克号数据集中,这可以帮助我们观察数据在低维空间中的分布情况,查看数据是否存在明显的聚类现象。
-
重要性:这种可视化有助于直观理解数据的内在结构和模型的分类效果,特别是观察不同类别之间的分离情况。
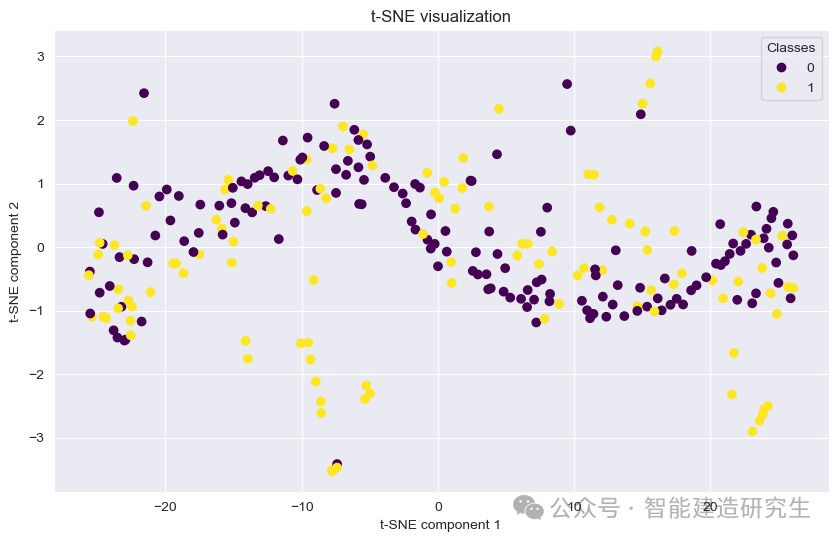
t-SNE将高维数据降维到2维空间,降维后的两个维度不是原始数据中的特定维度,而是t-SNE算法通过保持高维数据的邻近关系优化得到的两个新维度。图中黄色和紫色的点分别代表两个类别,即幸存者(1)和未幸存者(0)。
从整体上看,幸存者(黄色点)在t-SNE图中分布较为分散,而未幸存者(紫色点)则在一些特定区域集中。这可能与泰坦尼克号数据集中某些关键特征(如性别、舱位等级、年龄等)有关,这些特征对生存概率有显著影响。
以上内容总结自网络,如有帮助欢迎转发,我们下次再见!















 332
332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









