







 本文详细解析了AlphaGo的设计思路,包括深Q学习的问题与MCTS(蒙特卡洛树搜索)的应用。MCTS通过模拟搜索来寻找最优决策,而AlphaGo通过四个网络(Rollout Policy、SL policy network、RL policy network和Value network)加速搜索。此外,还探讨了如何通过简化MCTS降低计算量,以及AlphaGo在围棋中的应用和启发,如将MCTS引入训练过程和结合先验知识寻找最优策略。
本文详细解析了AlphaGo的设计思路,包括深Q学习的问题与MCTS(蒙特卡洛树搜索)的应用。MCTS通过模拟搜索来寻找最优决策,而AlphaGo通过四个网络(Rollout Policy、SL policy network、RL policy network和Value network)加速搜索。此外,还探讨了如何通过简化MCTS降低计算量,以及AlphaGo在围棋中的应用和启发,如将MCTS引入训练过程和结合先验知识寻找最优策略。
本文基于Google在Nature上关于AlphaGo的文章解读以及Git上对于AlphaGo的复现项目学习综合而来,主要探寻AlphaGo的学习技巧以及探寻其在机器人应用方面的思路和启事。
1.设计思路
deep Q-learing的问题

直接来看这个算法流程。算法的中心思想是想通过随机的动作探索出最佳的策略。但是这个随机探索的过程存在如下问题:
1.在状态空间比较大的时候,随机探索策略可能需要巨量的时间才能够探索到一个比较好的策略
2.随机策略选取的几率只和迭代次数有关而和整体策略的评价无关,即有可能在探索初期就得到一个比较好的策略,但是机构并不会以这个策略作为蓝本进行更进一步的探索,而是继续进行随机探索,使得探索效率变得很低
但是这种随机探索策略也有其好处:
1.没有人为策略的干扰,一旦其出现智能行为,就可以认为是人工智能算法的学习成果,而并非是人为设计的规则所引导出来的东西。
2.能够找到最接近全局最优的策略(基于当前假设和考虑基准)
我们希望能够在保留原有优点的情况下增加训练速度,这也是MCTS引入的一个理由。
1.1.MCTS
蒙特卡洛树搜索(MCTS),是一种基于模拟搜索的人工智能最优决策方法。
基本的 MCTS 算法非常简单:根据模拟的输出结果,按照节点构造搜索树。其过程可以分为下面的若干步:
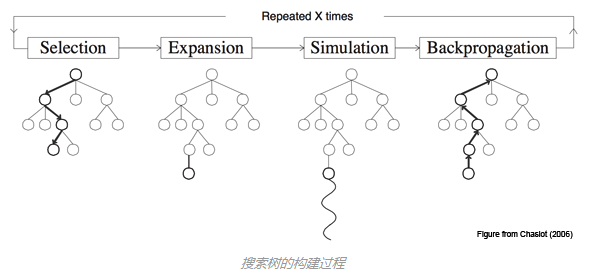
搜索树的构建过程
选择 Selection:从根节点 R 开始,递归选择最优的子节点(后面会解释)直到达到叶子节点 L。
扩展 Expansion:如果 L 不是一个终止节点(也就是,不会导致博弈游戏终止)那么就创建一个或者更多的字子节点,选择其中一个 C。
模拟 Simulation:从 C 开始运行一个模拟的输出,直到博弈游戏结束。
反向传播 Backpropagation:用模拟的结果输出更新当前行动序列。
【http://www.jianshu.com/p/d011baff6b64】
1.2.MCTS搜索简化
但是在较大的搜索空间中,即使是MCTS也需要承担巨大的计算量才能保证估计的准确性。例如在围棋游戏中,平均需要走150步才能决出胜负,每一步可以考虑的走法有大约250种。这样拓展开的树将有及其庞大数量的结点,给搜索造成了极大的困难。AlphaGo通过对MCTS进行简化,缩减了搜索树的宽度和深度,从而得到最优策略。
2.AlphaGo的树结构
AlphaGo通过四个网络来进行搜索的加速
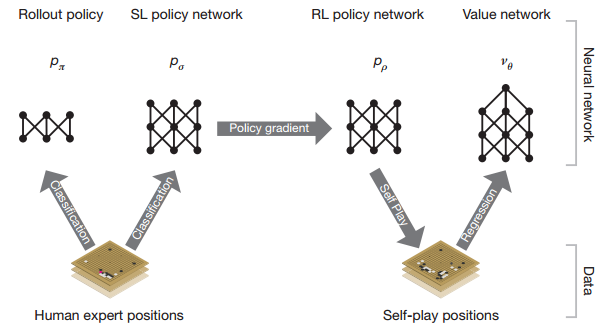
其中,RolloutPolicy和SL policy network都是针对于专家知识(棋谱)进行拟合的网络。
RL policy network用于策略网络的强化学习,而Value network用于估计各个状态的状态收益
2.1.Rollout Policy
RolloutPolicy使用的是简单的棋盘特征进行拟合训练,其特征设定如下:
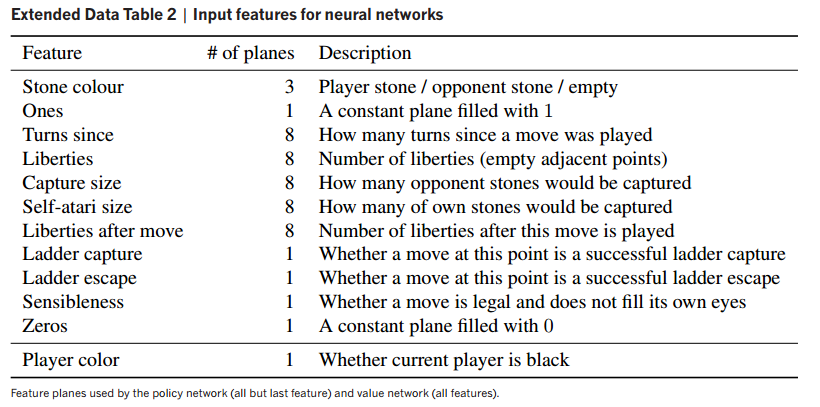
【Silver D, Huang A, Maddison C J, et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016, 529(7587): 484-489.】
这个网络在论文中只对专家系统的走法完成了22%左右的成功预测,但是计算速度非常快,可以用于估计快速估计当前状态的专家建议。但是AlphaGo在实际使用的时候,并不使用这个网络作为自己的预测网络,而是使用另一个更加复杂的卷积网络进行训练作为自己的策略网络。
2.2.SL policy network
该网络将围棋棋盘的落子情况视作一个19X19的图像输入,通过CNN网络结合专家知识进行训练,得到在各种情况的时候应该选择的落子方案。论文指出这个网络对于不同情况的预测和专家知识有大约50%的正确率。
看上去这个正确率并不算高,但是,这只是一个预训练系统,并不需要将这个模型调整到过高的正确率。
在强化学习的框架中,这其实可以理解为先验方案。相当于是将随机探索的动作分布从均匀分布转到了强先验条件的建议分布。但是之前我们也提到过了,我们并不希望这个建议分布过于强势,从而导致我们最终的策略严格遵从这个分布而无法进化学习。所以保持这个建议分布具有较低的正确率也是预防过拟合的一种方式。
2.3.RL policy nectwork
通过专家知识的预训练之后,AlphaGo进入自我博弈阶段。其会通过最新的网络和以前版本网络的自我博弈来自我进化。每次自我博弈的网络会从旧版本的网络中随机挑选,并且在每次新版本网络更新之后,其参数也会加入旧版本网络库中。
该网络的结构和SL policy network一致,其初始化参数即为SL policy network的训练结果。该网络以随机场景为episode的起点,以一局结束(赢或者输)为episode终点,128个episode为一个minbatch进行训练,对于策略 p 的优化公式为:
其中 log pp(at|st) 为在当前条件下选择各动作的概率, zt 为最终收益(赢为正1,输为负1,游戏未结束为0)。
在文章method部分指出
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1990
1990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









