






Universality theorem holds even if we restrict our networks to have just a single layer intermediate between the input and the output neurons.
第四章是对神经网络universality的讨论和证明,内容略读即可,故不整理笔记。
Chapter 5 Why are deep neuron network hard to train?
Just as in the case of circuits, there are theoretical results suggesting that deep networks are intrinsically more powerful than shallow networks.
The vanishing gradient problem
The pattern: early layers learn slower than later layers.
Observation: In at least some deep neural networks, the gradient tends to get smaller as we move backward through the hidden layers. Sometimes the gradient gets much larger in earlier layers.(exploding gradient problem)
The first layer throws away most information about the input image. Even if later layers have been extensively trained, they will still find it extremely difficult to identify the input image, simply because they don't have enough information.
1、Causes
![]()

The derivative reaches a maximum at σ′(0)=1/4. If we use our standard approach to initializing the weights in the network, choosing the weights using a Gaussian with mean 0 and standard deviation 1. So the weights will usually satisfy |wj|<1.
The unstable gradient problem: The gradient in early layers is the product of terms from all the later layers. When there are many layers, that's an intrinsically unstable situation. The only way all layers can learn at close to the same speed is if all those products of terms come close to balancing out.In short, the real problem here is that neural networks suffer from an unstable gradient problem. As a result, if we use standard gradient-based learning techniques, different layers in the network will tend to learn at wildly different speeds.
2、Prevalence
When using sigmoid neurons, the gradient will usually vanish. It's a fundamental consequence of the approach we're taking to learning.
Other obstacles to deep learning
Some earlier papers:
1、The use of sigmoid activation functions can cause problems training deep networks. In particular, they found evidence that the use of sigmoids will cause the activations in the final hidden layer to saturate near 0 early in training, substantially slowing down learning. They suggested some alternative activation functions.
2、The impact on deep learning of both the random weight initialization and the momentum schedule in momentum-based stochastic gradient descent:In both cases, making good choices made a substantial difference in the ability to train deep networks.
Chapter 6 Deep Learning
Techniques which can be used to train deep networks, and apply them in practice.
Convolutional networks
A special architecture which is particularly well-adapted to classify images.
1、Local receptive fileds: ( stride length = 1)

2、Shared weights and biases
shared weights, shared biases: We're going to use the same weights and bias for each of the hidden neurons. That means all the neurons in the first hidden layer detect exactly the same feature. To put it in slightly more abstract terms, convolutional networks are well adapted to the translation invariance of images.
The shared weights and bias are often said to define a kernel or filter.
eg, for the j,kth neuron:
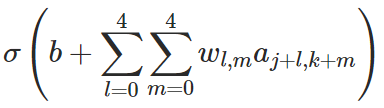
feature map: the map from the input layer to the hidden layer.
To do image recognition we'll need more than one feature map. And so a complete convolutional layer consists of several different feature maps.
eg, 3 feature maps:

The result is that the network can detect 3 different kinds of features, with each feature being detectable across the entire image.
3、Pooling layers
Simplify the information in the output from the convolutional layer and prepares a condensed feature map.
One common precedure: max-pooling

We can think of max-pooling as a way for the network to ask whether a given feature is found anywhere in a region of the image. It then throws away the exact positional information. The intuition is that once a feature has been found, its exact location isn't as important as its rough location relative to other features.
Other techniques: L2-pooling, take the square root of the sum of the squares of the activations.
4、

Backpropagation needs to be modified.
The convolutional layers have considerable inbuilt resistance to overfitting. The reason is that the shared weights mean that convolutional filters are forced to learn from across the entire image. This makes them less likely to pick up on local idiosyncracies in the training data. And so there is less need to apply other regularizers, such as dropout.
Exercise
1、Our argument for that initialization was specific to the sigmoid function. Consider a network made entirely of rectified linear units (including outputs). Show that rescaling all the weights in the network by a constant factor c>0 simply rescales the outputs by a factor c^{L−1}, where L is the number of layers. How does this change if the final layer is a softmax? What do you think of using the sigmoid initialization procedure for the rectified linear units? Can you think of a better initialization procedure?
2、Our analysis of the unstable gradient problem was for sigmoid neurons. How does the analysis change for networks made up of rectified linear units? Can you think of a good way of modifying such a network so it doesn't suffer from the unstable gradient problem?
Recent progress in images recognition
1、Some other approach:
Recurrent neural network (RNNs): with time-varying behaviour
It's particularly useful in analysing data or processes that change over time. Such data and processes arise naturally in problems such as speech or natural language, for example.
Long short-term memory units(LSTMs):
One challenge affecting RNNs is that early models turned out to be very difficult to train, harder even than deep feedforward networks. The reason is the unstable gradient problem. The problem actually gets worse in RNNs, since gradients aren't just propagated backward through layers, they're propagated backward through time. If the network runs for a long time that can make the gradient extremely unstable and hard to learn from.
Deep belief nets, generative models, and Boltzmann machines:
One reason DBNs are interesting is that they're an example of what's called a generative model. A generative model like a DBN can be used in a similar way, but it's also possible to specify the values of some of the feature neurons and then "run the network backward", generating values for the input activations. A generative model is much like the human brain: not only can it read digits, it can also write them. A second reason DBNs are interesting is that they can do unsupervised and semi-supervised learning.















 836
836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









