








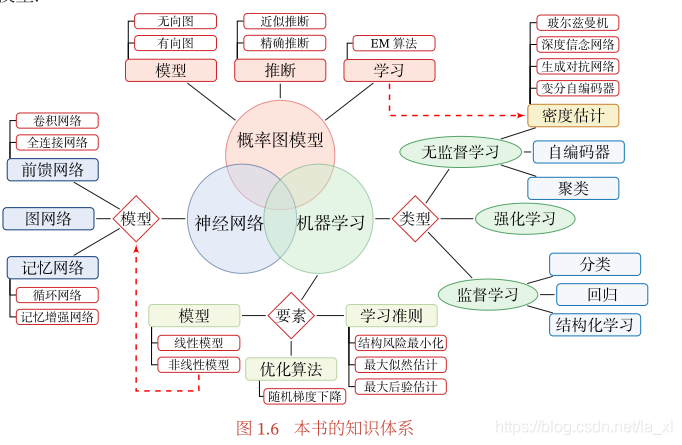
本书的知识体系
深度学习与神经网络概要
从根源上讲,深度学习是机器学习的一个分支,是指一类问题以及解决这类问题的方法。
深度学习采用的模型一般比较复杂,指样本的原始输入到输出目标之间的数据流经过多个线性或非线性的组件.因为每个组件都会对信息进行加工,并进而影响后续的组件,所以当我们最后得到输出结果时,我们并不清楚其中每个组件的贡献是多少.这个问题叫作贡献度分配问题。
在深度学习中,贡献度分配问题是一个很关键的问题,这关系到如何学习每个组件中的参数。
目前,一种可以比较好解决贡献度分配问题的模型是人工神经网络( Artifi-Neural Network , ANN ).简称神经网络。
神经网络和深度学习并不等价。深度学习可以采用神经网络模型,也可以采用其他模型(比如深度信念网络是一种概率图模型)。但是,由于神经网络模型可以比较容易地解决贡献度分配问题,因此神经网络模型成为深度学习中主要采用的模型。
人工智能
图灵测试: “一个人在不接触对方的情况下,通过一种特殊的方式和对方进行一系列的问答.如果在相当长时间内,他无法根据这些问题判断对方是人还是计算机,那么就可以认为这个计算
机是智能的”。
目前,人工智能的主要领域大体上可以分为以下几个方面:
- 感知:模拟人的感知能力,对外部刺激信息(视觉和语音等)进行感知和加工。主要研究领域包括语音信息处理和计算机视觉等.
- 学习:模拟人的学习能力,主要研究如何从样例或从与环境的交互中进行学习主要研究领域包括监督学习、无监督学习和强化学习等
- 认知:模拟人的认知能力,主要研究领域包括知识表示、自然语言理理解、推理、规划、决策等.
机器学习
机器学习( Machine Learning , ML )是指从有限的观测数据中学习(或“猜测”)出具有一般性的规律,并利用这些规律对未知数据进行预测的方法。
机器学习是人工智能的一个重要分支,并逐渐成为推动人工智能发展的关键因素。
机器学习模型步骤
- 数据预处理:对数据的原始形式进行初步的数据清理(比如去掉一些有缺失特征火冗余的样本)和加工(对数值特征进行缩放和归一化等),并构建成可用于训练机器学习模型的数据集.
- 特征提取:从数据的原始特征中提取一些对特定机器学习任务有用的高质量特征.比如在图像分类中提取边缘、尺度不变特征变换(Scale Invariant Feature Transform , SIFT )特征,在文本分类中去除停用词等.
- 特征转换:对特征进行进一步的加工,比如降维和升维。很多特征转换方法也 都是机器学习方法.降维包括特征抽取( Feature Extraction )和特征选择( Feature Selection )两种途径.常用的特征转换方法有主成分分析( Principal Components Analysis , PCA )、线性判别分析( Linear Discriminant Analysis , LDA )等.
- 预测:机器学习的核心部分,学习一个函数并进行预测。

开发一个机器学习系统的主要工作量都消耗在了预处理、特征提取以及特征转换上。
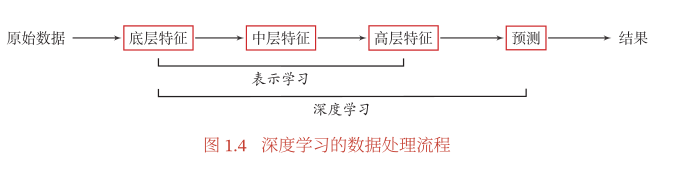
表示学习
为了提高机器学习系统的准确率,我们就需要将输入信息转换为有效的特征,或者更一般性地称为表示( Representation ).如果有一种算法可以自动地学习出有效的特征,并提高最终机器学习模型的性能,那么这种学习就可以叫作表示学习( Representation Learning ).
在表示学习中,有两个核心问题:一是“什么是一个好的表示”;二是“如何学习到好的表示”.
局部表示与分布式表示
- 一种表示颜色的方法是以不同名字来命名不同的颜色,这种表示方式叫作局部表示,也称为离散表示或符号表示;例如“中国红”。通常可以表示为
one-hot 向量的形式。 - 另一种表示颜色的方法是用 RGB 值来表示颜色,不同颜色对应到 R 、 G 、B
三维空间中一个点,这种表示方式叫作分布式表示.分布式表示通常可以表示为低维的稠密向量。
表示学习的关键是构建具有一定深度的多层次特征表示。
深度学习
目前,深度学习采用的模型主要是神经网络模型,其主要原因是神经网络模型可以使用误差反向传播算法,从而可以比较好地解决贡献度分配问题.只要是超过一层的神经网络都会存在贡献度分配问题,因此可以将超过一层的神经网络都看作深度学习模型。
常用的深度学习框架
比较有代表性的框架包括: Theano 、 Caffe 、 TensorFlow 、Pytorch 、飞桨( PaddlePaddle )、 Chainer 和 MXNet 等。
- Theano:由蒙特利尔大学的 Python 工具包,Theano 项目目前已停止维护.
- Caffe:由加州大学伯克利分校开发的针对卷积神经网络的计算框架,主要用于计算机视觉. Caffe 用 C++ 和 Python 实现,但可以通过配置文件来实现所要的网络结构,不需要编码.
- TensorFlow :由 Google 公司开发的深度学习框架, TensorFlow 的计算过程使用数据流图来表示.TensorFlow 的名字来源于其计算过程中的操作对象为多维数组,即张量(Tensor ).TensorFlow 1.0 版本采用静态计算图, 2.0 版本之后也支持动态计算图.
- PyTorch :由 Facebook 、 NVIDIA 、 Twitter 等公司开发维护的深度学习框架,其前身为 Lua 语言的 Torch . PyTorch 也是基于动态计算图的框架,在需要动态改变神经网络结构的任务中有着明显的优势.
- 飞桨( PaddlePaddle ):由百度开发
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 398
398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









