







 本文记录了一次在基于DPDK17.11的项目中,由于多线程导致的野指针问题及定位解决过程。通过分析coredump堆栈、验证线程数量与异常的关系、检查代码和研究DPDK内存池,最终发现并解决了由于线程抢占KNI发包接口导致的重复free问题。
本文记录了一次在基于DPDK17.11的项目中,由于多线程导致的野指针问题及定位解决过程。通过分析coredump堆栈、验证线程数量与异常的关系、检查代码和研究DPDK内存池,最终发现并解决了由于线程抢占KNI发包接口导致的重复free问题。
前段时间,参与了我司基于dpdk的高速数据包转发模式项目,在开发的过程,我们遇到一个奇怪的coredump事件,考虑到其定位过程比较特殊,又是关于的dpdk定位过程,故记录在此。
背景:
我司的产品是个典型的数据转发为导向的项目,业务逻辑在流量高并发情况下,可能连5%都占不到。所以我们在dpdk的开发套件上,完成一些特性,支持了我们的业务。其系统配置如下:
version: dpdk17.11
system: ubuntu14.04 server
线程:dpdk接管8个超线程
现象:
数据面在做稳定性测试时,使用tc模拟数据报文高并发冲击测试,大约半个小时左右会出现一次coredump,且每次出现的core文件的记录基本都是挂在在rte_pktmbuf_read。如果流量不大的话,则未出现异常现象。如下,是一次coredump的堆栈信息。
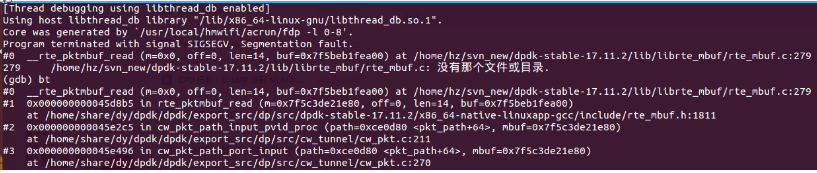
分析:
查看mbuf的指针在rte_pktmbuf_read时还是有地址的, 在调用内置的封装函数__rte_pktmbuf_read时, 该mbuf的指针地址突然变成了0, 显然程序在访问这个mbuf时产生了异常,造成coredump。
上一步函数入参还是正常,下一步入参直接地址变成了0,为什么会出现这种情况?如果是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









