







目录
1、概述
前馈神经网络(feedforward neural network),简称前馈网络,是人工神经网络的一种。在此种神经网络中,各神经元从输入层开始,接收前一级输入,并输入到下一级,直至输出层。整个网络中无反馈,可用一个有向无环图表示。前馈神经网络是最早被提出的人工神经网络,也是最简单的人工神经网络类型。按照前馈神经网络的层数不同,可以将其划分为单层前馈神经网络和多层前馈神经网络。常见的前馈神经网络有感知机(Perceptrons)、BP(Back Propagation)网络、RBF(Radial Basis Function)网络等。
2、数据集准备
|
owNumber
|
行号
|
|
CustomerID
|
用户编号
|
|
Surname
|
用户姓名
|
|
CreditScore
|
信用分数
|
|
Geography
|
用户所在国家
/
地区
|
|
Gender
|
用户性别
|
|
Age
|
年龄
|
|
Tenure
|
当了本银行多少年用户
|
|
Balance
|
存贷款情况
|
|
NumOfProducts
|
使用产品数量
|
|
HasCrCard
|
是否有本行信用卡
|
|
IsActiveMember
|
是否活跃用户
|
|
EstimatedSalary
|
估计收入
|
|
Exited
|
是否已流失,这将作为我
们的标签数据
|
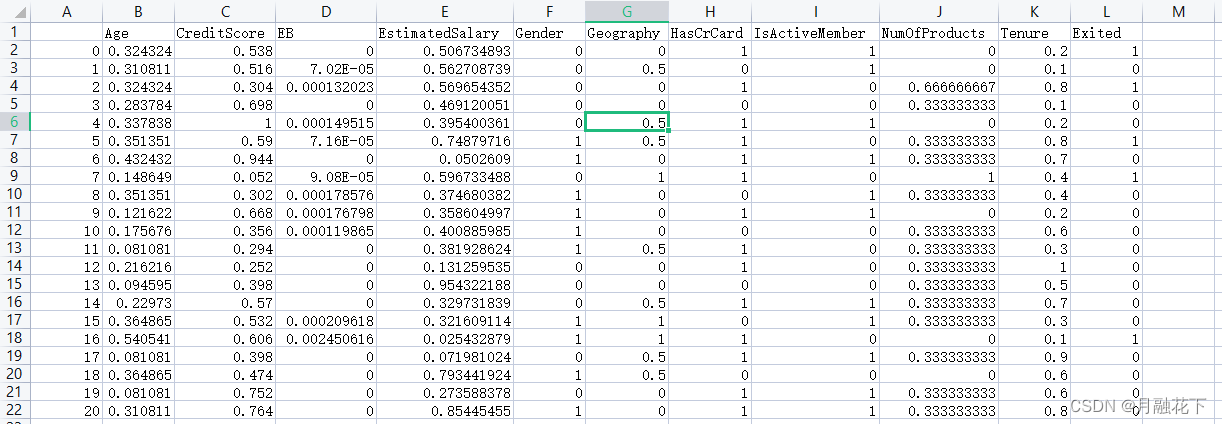
训练集:select-data.csv
测试集:scalar-test.csv
3、实验部分
3.1 模块加载
import numpy as np
import tensorflow.compat.v1 as tf
import matplotlib.pyplot as plt
import pandas as pd
from matplotlib.font_manager import FontProperties
import os
from sklearn.preprocessing import OneHotEncoder3.2 数据读取
curentPath = os.getcwd()
print(curentPath)
df = pd.read_csv("../data/loss_of_silver_customers/select-data.csv");
df_test = pd.read_csv("../data/loss_of_silver_customers/scalar-test.csv");
![]()
3.3 构建向量
train = []
target = []
for i in range(0,len(df["EstimatedSalary"])):
mid = []
mid.append(df["Geography"][i])
mid.append(df["Gender"][i])
mid.append(df["EB"][i])
mid.append(df["Age"][i])
mid.append(df["EstimatedSalary"][i])
mid.append(df["NumOfProducts"][i])
mid.append(df["CreditScore"][i])
mid.append(df["Tenure"][i])
mid.append(df["HasCrCard"][i])
mid.append(df["IsActiveMember"][i])
target.append(df["Exited"][i]);
train.append(mid);
train = np.array(train);
target = np.array(target);训练集数据:
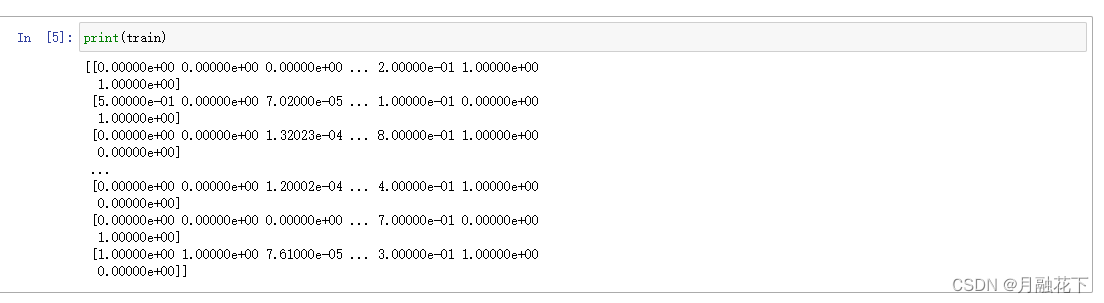
标签数据:

3.4 数据编码
#随机打乱训练集与标签
np.random.shuffle(train)
print(train)
np.random.shuffle(target)
print(target)
target = target.reshape(-1,1)
test_target = test_target.reshape(-1,1)
print(target)
print(test_target)
#one-hot编码
enc = OneHotEncoder()
enc.fit(test_target)
test_target = enc.transform(test_target).toarray()
print(test_target)
enc.fit(target)
target = enc.transform(target).toarray()
print(target)3.5 网络结构设计
#定义输入占位符
tf.disable_eager_execution()
x=tf.placeholder(tf.float32,shape=(None,10))
#二分类问题[0,1]
y=tf.placeholder(tf.float32,shape=(None,2))
keep = tf.placeholder(tf.float32)使用到的函数:
tf.truncated_normal
truncated_normal(
shape,
mean=0.0,
stddev=1.0,
dtype=tf.float32,
seed=None,
name=None
)
功能说明:
产生截断正态分布随机数,取值范围为 [ mean - 2 * stddev, mean + 2 * stddev ]。
参数名 必选 类型 说明
shape 是 1 维整形张量或 array 输出张量的维度
mean 否 0 张量或数值 均值
stddev 否 0 维张量或数值 标准差
dtype 否 dtype 输出类型
seed 否 数值 随机种子,若 seed 赋值,每次产生相同随机数
name 否 string 运算名称
///
tf.zerostf.zeros(
shape,
dtype=tf.float32,
name=None
)
函数参数:shape:整数、整数元组或类型为int32的1维Tensor的列表.
dtype:结果Tensor中元素的类型.
name:操作的名称(可选).
函数返回值:tf.zeros函数返回将所有元素设置为零的张量
/
tf.nn.dropout(
x,
keep_prob,
noise_shape=None,
seed=None,
name=None
)
参数:x:一个浮点型Tensor.
keep_prob:一个标量Tensor,它与x具有相同类型.保留每个元素的概率.
noise_shape:类型为int32的1维Tensor,表示随机产生的保持/丢弃标志的形状.
seed:一个Python整数.用于创建随机种子.
name:此操作的名称(可选).返回:
该函数返回与x具有相同形状的Tensor.
可能引发的异常:
ValueError:如果keep_prob不在(0, 1]或如果x不是浮点型Tensor.
网络结构:
#定义网络结构
#layer1
var1 = tf.Variable(tf.truncated_normal([10,256],stddev=0.1))
bias1 = tf.Variable(tf.zeros(256));
hc1= tf.add(tf.matmul(x,var1),bias1)
h1=tf.sigmoid(hc1)
h1 = tf.nn.dropout(h1,keep_prob=keep)#layer2
var2 = tf.Variable(tf.truncated_normal([256,256],stddev=0.1))
bias2 = tf.Variable(tf.zeros(256));
hc2= tf.add(tf.matmul(h1,var2),bias2)
h2=tf.sigmoid(hc2)
h2 = tf.nn.dropout(h2,keep_prob=keep)tf.nn.softmax(
logits, # 输入:全连接层(往往是模型的最后一层)的值,一般代码中叫做logits
axis = None,
name = None
dim = None
)
函数的参数说明如下:logits:需要进行softmax操作的张量,可以任意维度。
axis:指定进行softmax操作的维度,默认为None,此时将进行最后一维的softmax操作。作用:softmax函数的作用就是归一化。
输入:全连接层(往往是模型的最后一层)的值,一般代码中叫做logits
输出:归一化的值,含义是属于该位置的概率,一般代码叫做probs,例如输出[0.4, 0.1, 0.2, 0.3],那么这个样本最可能属于第0个位置,也就是第0类。这是由于logits的维度大小就设定的任务的类别,所以第0个位置就代表第0类。softmax函数的输出不改变维度的大小。(该样本属于各个类的概率)
用途:如果做单分类的问题,那么输出的值就取top1(最大, argmax); 如果做多分类问题,那么输出的值就取topN。
#layer3
var3 = tf.Variable(tf.truncated_normal([256,2],stddev=0.1))
bias3 = tf.Variable(tf.zeros(2));
hc3 = tf.add(tf.matmul(h2,var3),bias3)
h3 = tf.nn.softmax(hc3)损失函数:
tf.nn.softmax_cross_entropy_with_logits_v2(_sentinel, labels, logits, dim, name)
计算 softmax(logits) 和 labels 之间的交叉熵
参数:_sentinel -->内部,一般不使用。
labels --> 真实数据的类别标签
logits -->神经网络最后一层的类别预测输出值
dim --> 类维度。默认为-1,这是最后一个维度。
一般用于交叉熵损失函数的设定:
cross_entropy_loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits = y, labels = y_))
///
tf.reduce_mean
tf.reduce_mean(
input_tensor,
axis=None,
keep_dims=False,
name=None,
reduction_indices=None)
释义:用于计算tensor(张量)沿着指定的数轴(即tensor的某一维度)上的平均值,用作降维或者计算tensor的平均值
参数:
input_tensor:输入的tensor
axis:指定的轴,axis=0沿列进行求均值,axis=1沿行进行求均值,若不指定,则计算所有元素的均值
keep_dims:是否将维度,默认为False,输出结果会降低维度;若设置为True,输出的结果保持输入tensor的形状
name:操作的名称
#定义损失
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=h3,labels=y))
tf.summary.scalar("loss",loss)正确率:
tf.argmax
tf.argmax(
input,
axis=None,
name=None,
dimension=None,
output_type=tf.int64
)
释义:主要功能是找出最大值并返回索引
参数:
input代表输入的数组
axis代表张量的最大维数0代表1维,1代表行二维为None(0)
name代表操作的名称,默认为None
dimension:按某维度查找。0代表列,1代表行默认为None(0)。
output_type,为输出的数据类型,可以指定
//
tf.cast(x, dtype, name=None)
释义:数据类型转换
x,输入张量
dtype,转换数据类型
name,名称
//
#定义正确率
ac = tf.cast(tf.equal(tf.argmax(h3,1),tf.argmax(y,1)),tf.float32)
acc = tf.reduce_mean(ac)
tf.summary.scalar("accuracy",acc)优化器:
#定义优化器
optimizer = tf.train.AdamOptimizer(1e-3).minimize(loss)merge_summary = tf.summary.merge_all()
isTrain = 13.6 网络训练
保存模型/加载模型
saver=tf.train.Saver(max_to_keep=1)
参数:
max_to_keep: 表明保存的最大checkpoint 文件数。当一个新文件创建的时候,旧文件就会被删掉。如果值为None或0,表示保存所有的checkpoint 文件。默认值为5(也就是说,保存最近的5个checkpoint 文件)。
keep_checkpoint_every_n_hour: 除了保存最近的max_to_keep checkpoint 文件,你还可能想每训练N小时保存一个checkpoint 文件。这将是非常有用的,如果你想分析一个模型在很长的一段训练时间内是怎么改变的。例如,设置 keep_checkpoint_every_n_hour=2 确保没训练2个小时保存一个checkpoint 文件。默认值10000小时无法看到特征。
————————————————————————————————————————————————————————————————
保存模型
saver.save(sess=sess,save_path=model_save_path,global_step=step)
参数:
sess=sess,会话名字
save_path=model_save_path,设定权重参数保存的路径和文件名
global_step=step,将训练的次数作为后缀加入到模型名字中
————————————————————————————————————————————————————————————————
实际上每调用一次保存操作会创建后3个数据文件并创建一个检查点(checkpoint)文件。
checkpoint
model.ckpt.data-00000-of-00001
model.cpkt.index
model.ckpt.meta
简单理解就是权重等参数被保存到 .ckpt.data 文件中,以字典的形式;
.ckpt-index,应该是内部需要的某种索引来正确映射前两个文件;
图和元数据被保存到 .ckpt.meta 文件中,可以使用tf.train.import_meta_graph 加载
————————————————————————————————————————————————————————————————
加载模型
saver.restore(sess=sess, save_path=model_save_path)
参数:
sess=sess,会话名字;
save_path=model_save_path,权重参数的保存的路径和文件名。
指定一个文件用来保存图
tf.summary.scalar("loss",loss)
merge_summary = tf.summary.merge_all()
writer = tf.summary.FileWriter(path, session.graph)
train_summary = sess.run(merge_summary,feed_dict={x:train,y:target,keep:1})
summary_writer.add_summary(train_summary,i)
print("正在训练")
saver = tf.train.Saver(max_to_keep=1)
font_size = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=15)
with tf.Session() as sess:
if isTrain:
init_top = tf.global_variables_initializer()
sess.run(init_top)
summary_writer = tf.summary.FileWriter("./logs/loss_of_silver_customers/",sess.graph)
nepoch = []
trainacc = []
testacc = []
loss1 = []
for i in range(0,10001):
sess.run(optimizer,feed_dict={x:train,y:target,keep:0.5})
train_summary = sess.run(merge_summary,feed_dict={x:train,y:target,keep:1})
summary_writer.add_summary(train_summary,i)
if i%50==0:
accu = sess.run(acc,feed_dict={x:train,y:target,keep:0.5})
accuT = sess.run(acc,feed_dict={x:test,y:test_target,keep:1})
losss = sess.run(loss,feed_dict={x:train,y:target,keep:1})
print("epoch:"+str(i)+"train_acc:"+str(accu)+"test_acc:"+str(accuT)+"loss:"+str(losss))
nepoch.append(i)
trainacc.append(accu)
testacc.append(accuT)
loss1.append(losss)
plt.title(u"BP神经网络训练性能曲线",fontproperties = font_size)
plt.xlabel(u"训练次数",fontproperties = font_size)
plt.ylabel(u"训练样本和校验样本的精准度",fontproperties = font_size)
plt.plot(nepoch,trainacc,nepoch,testacc)
plt.plot(nepoch,trainacc,nepoch,loss1)
plt.show()
notebook代码下载:
链接:https://pan.baidu.com/s/103pZje-H11nqjbQp8hcnFQ
提取码:1234















 1363
1363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









