





摘要
提出了两种方法来优化量化训练:1. 引入离散化阈值的训练尺度因子,对每个滤波器进行分离。2. 后续的的dws卷积和卷积层的互相重标度。根据以上技术,本文用10%ImageNet2012的训练数据对移动网络进行了训练量化。这样减少了训练数据集大小和训练参数量,使得在保持量化模型高精度(少于0.5%的精度下降)的同时仅用几个小时就微调了网络。可用的模型和代码:https://github.com/agoncharenko1992/FAT-fastadjustable-threshold。
1 介绍
无干货
2 相关工作
将fp32值映射到n位有符号定点数的公式为:

![]() :四舍五入到最近的整数
:四舍五入到最近的整数
W:weights
T:量化阈值
max:计算tensor所有维下的最大值
输入值可以被量化到有符号或者无符号整数,这取决于上一层的激活函数。

有必要提出,计算的结果一定比计算子的位容量高。比如[12]中权值和激活值被量化为8比特,然而累加器是32比特。
潜在的量化阈值可以随时计算,但是会降低在低资源设备上运行的速度。这是为什么量化阈值通常提前在校准过程中计算的原因之一。一系列数据被输入到网络中,来找到每层需要的阈值(在上面的例子中是最大值)。校准数据集包含对于特定网络来说最有特点的数据。这些数据不需要标签。
2.1 知识蒸馏量化
知识蒸馏由G.Hinton提出。主要想法是在预训练模型的帮助下训练网络。[16][17]中,这个方法被如下使用:一个全精度模型被用作老师模型,量化的网络被当作学生模型。这种学习方式不仅带来了量化网络推理的高质量,而且可以在保持精度的前提下减小量化数据的位容量。
2.2 无微调量化
一些框架可以在不微调的情况下进行量化。最出名的是TensorRT,Tensorflow和Nervana Systems的Distiller框架。然而,后两个模型中,计算量化因数是随时进行的,这可能减缓移动设备上的网络运行速度。另外,TensorRT框架不支持例如MobileNet结构的网络。
2.3 训练/微调量化
[7][10][18][23]中,作者使用STE来训练网络权重到2或者3位整数。然而,这些网络准确率较低。
[15][24]训练的网络几乎和原始网络质量相同。此外,[24]的作者还强调了量化网络联合的重要,这种网络可能可以被用在二值量化网络上。[12]中给出了调整网络结构的全部框架,使得学习道德量化模型可以在移动设备上使用。
[5]使用了和本文相似的阈值训练法。然而,他们提出的方法有缺点,不能在移动设备上快速转换预训练模型。首先,它需要在全ImageNet数据集上训练阈值。此外,它没有给出用作移动平台标准的准确率。
本文中,作者提出了用在小未标注数据集上快速微调来设置量化阈值的方法。作者给出了方法在MobileNetV2和MNAS上的表现。
3 方法描述


在特定的情况下(图1、2),模型可能在量化过程中降级。图1中权重分布异常值的存在迫使网络选择一个高阈值,这导致了量化模型的准确率下降。
异常值的出现有以下几点原因,即校准数据集的特殊特征,比如类不均或者不具有代表性的输入数据;或者是网络的自然特性,比如在训练或者某些神经元对于最大值特征的反应中形成的权值异常。
综上所述,完全避免异常值是不可能的,因为它们和神经网络的基础特征紧密相关。然而,可以在阈值和畸变之间找一个权衡来得到更好的量化网络质量。
3.1 阈值微调量化
3.1.1 可导量化阈值
[10][23][6]中,STE可以用来定义不可导的函数的偏导。因此,这些函数的值变得可导,并且可以用梯度下降来训练。这种变量是量化阈值,并且它的训练可以直接带来量化网络的最优质量。这种方法可以通过下面的修正方法来进一步优化。
3.1.2 BN折叠
在量化网络权重前,作者建议用和[12]中类似的方法来对权重做BN折叠。最后得到计算后的新权重:
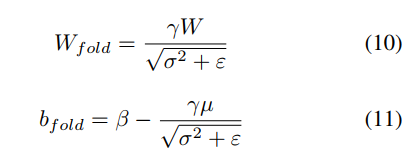
作者将和BN层融合的权重量化,因为这样可以简化离散并且加速推理。接下来的权重都指折叠后的权重。
3.1.3 阈值尺度
除了量化阈值外的所有网络参数都是固定的。激活阈值的初始值是在校准过程中计算的。对于权重来说,阈值是最大的绝对值。量化阈值T计算公式如下:
![]()
其中是可训练的参数,从
中加上饱和取得。这两个值根据经验取0.5和1.0。尺度参数的引入简化了网络训练,因为阈值的更新是在不同层用不同学习率完成的。例如VGG中间层的值可能比第一层的值大7倍。
因此量化过程可以被写为:

权重也是类似的过程。目前的量化过程由两个不可导的函数,round和clip。这两个函数的梯度可以被定义为:

偏差量化和[12]中相同
![]()
3.1.4 非对称阈值训练
[12]中实现了针对移动网络非对称阈值的量化。分别是非对称阈值的左、右边界。然而,量化过程使用其他两个值更方便一点:左边界和宽度,然后训练这些参数。如果左边界等于0,那么对它做尺度变换没有任何影响。这就是为什么要引入左边界的偏移量。这个偏移量如下计算
是经验值,在有符号的情况下取-0.2和0.4,无符号的情况下取0和0.4。范围宽度也用同样的方法选择。
选择0.5和1。
3.1.5 向量量化
有时由于权值分布太广,对于不同滤波器使用不同阈值是可能的。因此,向量量化使用一组因子而不是单个量化因子。这个过程不会使设备实现变复杂,然而却能提高准确率。可观的准确率提升在使用了可分离depthwise卷积的网络上特别明显。比如MobileNetV1和MobileNetV2。
3.2 在未标注数据上训练
本文建议去掉训练数据的标签,这样能加速从未量化到量化的转变。作者建议优化量化网络和原始网络softmax之前的输出的root-mean-square error(RMSE),同时保持原网络的参数不变。
上述方法可以被看作[16]中所有关于标签数据的成分都下线的蒸馏量化。
总的损失函数L为

其中是未量化网络的输出,
是量化网络的输出,N是batch size。
3.3 depthwise可分离卷积的量化
量化带depthwise可分离卷积的网络时,向量量化比标量量化准确率更高。
不同于标量量化,向量量化将权重的每个滤波器的分布考虑进来,每个滤波器都有它自己的量化阈值。如果将阈值重新标度来保证每个滤波器的量化阈值都是相通的,那么向量和标量量化就等效了。
对于一些模型这个方法可能无效,因为任何在重标度后的数据上进行的非线性操作以及将有不同标度因子的数据相加都是不允许的。对于特殊情况如DWS->RELU->Conv来说,标度数据可以如图3来做,这种情况下只有模型的权重改变。

3.3.1 MobileNetV2(ReLU6)权值标度
缩放DWS滤波器的权重时,也会缩放DWS层的输出。一种保持网络推理结果不变的方法是修改ReLU6函数,这样第k个通道的饱和阈值等于。然而,这对于标量量化是不适合的。
实际中,一个DWS层的某些通道的输出数据Xk可能小于6。重新缩放这些通道是可能的,但要有特定的限制。也就是得设置这些通道中每个通道的缩放系数,这样才能保证输出不大于6.0。

我们提出以下缩放DWS滤波器权重的方案:
1. 找到DWS层中每个filter的最大绝对值
2. 用一组校准数据来决定每个通道达到的最大值(DWS层,ReLU6之前)
3. 将输出值大于6的通道标记为‘locked’。DWS层的对应的滤波器保持不变。文章提议锁住输出数据近似6的通道,因为当用不同校准数据时,它可能达到这个值。文中使用5.9作为上限。
4. 计算每个锁住的滤波器的最大绝对值和这些最大值的均值
。均值成为一个控制值来缩放没锁住的滤波器的权重。这样做的主要目的是最小化DWS层不同filter的阈值间的差距。
5. 找到没锁的通道的合适的缩放系数
6. 将这些缩放系数限制住,这样DWS层没锁的通道的最大值不大于6.0。
4 实验和结果
4.1 实验描述
4.1.2 训练过程
量化后和原始网络间的RMSE用作损失函数。Adam优化器用来训练,剩下的优化参数(lr)用cosine退火。训练在ImageNet的10%数据上进行。测试在验证集上进行。训练集中的100张图片用来校准。训练需要6-8epoch。
4.2 结果
















 8165
8165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









