






大家好,我是 同学小张,+v: jasper_8017 一起交流,持续学习AI大模型应用实战案例,持续分享,欢迎大家点赞+关注,订阅我的大模型专栏,共同学习和进步。
欢迎订阅专栏,即将涨价!
在大模型(LLM)席卷全球的浪潮中,推理效率低下始终是工业落地的最大瓶颈。传统Chain-of-Thought(CoT)方法通过“思维链”提升准确率,但也付出了高延迟、高成本的代价:一次多步推理动辄消耗数百Token,答案生成需等待数秒。
Zoom团队最新提出的Chain of Draft(CoD)技术,通过“极简草稿推理”首次实现了效率与性能的平衡:在主流任务中,它用7.6%的Token量达到了与原版CoT相近的准确率,推理延迟直降76%!
一起来学习一下这项技术 - CoD。

1. 为什么需要抛弃冗长的“思维链”?
(1)成本黑洞
以GPT-4 Turbo为例,生成200个Token的CoT推理需要约0.02美元。假设某客服系统日均处理10万次查询,仅Token开销就高达2000美元/天。
(2)延迟困局
在多轮对话场景中,用户等待时间超过1.5秒会导致体验显著下降。然而,传统CoT在复杂数学题中平均耗时达4秒以上。
(3)人类智慧的启示
人类在解决数学题时,往往用符号速记代替完整句子(如“20=12-8”)。若将这一行为映射到LLM,可能开启效率革命。
2. CoD如何实现“少即是多”?
(1)极简核心法则
-
每步最多5词:强制模型提取关键信息,如数学推导仅保留公式。
-
少样本“模板教学”:通过3-5个手动示例,教会模型模仿速记风格。
示例:
- Q: 仓库现有货物150箱,运出后剩80箱,运出多少?
- A: 150−?=80 → ?=70 ####70
(2)系统级优化设计
-
动态松弛约束:允许少量超长步骤(如6-7词),避免语法断裂。
-
分层解码策略:对草稿和答案分段生成,优先输出关键数据。
(3)开箱即用
接入仅需添加一行提示词:
system_prompt = """生成极简推理草稿(每步≤5词),答案以####结尾。"""
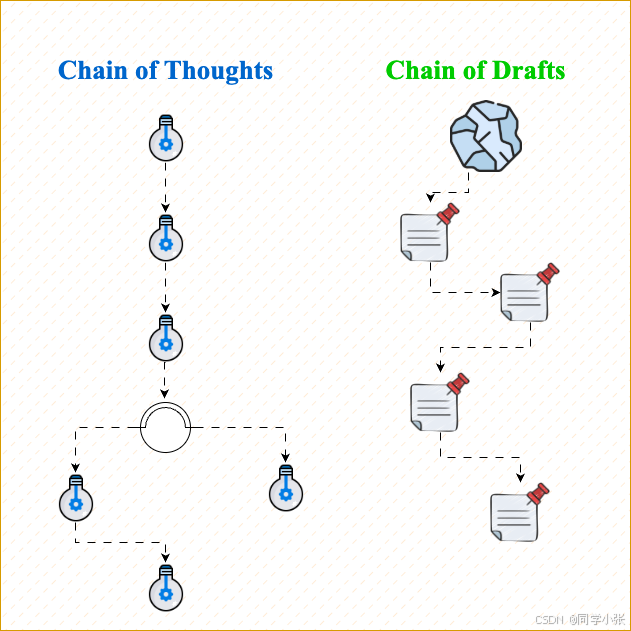
3. CoD与CoT区别
我们都知道,CoT的实现其实更多的是在提示词中加入一句:Think Step By Step. 例如下面这个Prompt:
Think step by step to answer the following question.
Return the answer at the end of the response after a
separator ####.
CoD其实也类似,只需要在提示词中加几句话:
Think step by step, but only keep a minimum draft for
each thinking step, with 5 words at most. Return the
answer at the end of the response after a separator
####.
输出区别示例:对于同一个提问,
Q: Jason had 20 lollipops. He gave Denny some lollipops. Now Jason has 12 lollipops. How many lollipops did Jason give to Denny?
CoT回复:
Q: Jason had 20 lollipops. He gave Denny some
lollipops. Now Jason has 12 lollipops. How many
lollipops did Jason give to Denny?
A: Let’s think through this step by step:
1. Initially, Jason had 20 lollipops.
2. After giving some to Denny, Jason now has 12
lollipops.
3. To find out how many lollipops Jason gave to
Denny, we need to calculate the difference between
the initial number of lollipops and the remaining
number.
4. We can set up a simple subtraction problem:
Initial number of lollipops - Remaining number of
lollipops = Lollipops given to Denny
5. Putting in the numbers: 20 - 12 = Lollipops given
to Denny
6. Solving the subtraction: 20 - 12 = 8
Therefore, Jason gave 8 lollipops to Denny.
####8 lollipops
CoD回复:
Q: Jason had 20 lollipops. He gave Denny some
lollipops. Now Jason has 12 lollipops. How many
lollipops did Jason give to Denny?
A: 20 - x = 12; x = 20 - 12 = 8. #### 8
3. 效果验证
(1)基准测试数据
| 任务类型 | 模型 | CoT准确率 | CoD准确率 | Token节省率 |
|---|---|---|---|---|
| 数学推理(GSM8K) | Claude 3.5 | 95.8% | 91.4% | 79% |
| 体育常识推理 | GPT-4o | 95.9% | 98.3% | 92.4% |
| 代码调试 | DeepSeek-R1 | 87% | 85% | 83% |
注:Code任务需放宽至每步10词,但仍显著优于CoT
(2)延迟对比实验
在AWS g5.12xlarge实例上,处理1000次并发请求:
- CoT(200 Tokens):平均响应4.2秒,费用$0.15/千次
- CoD(40 Tokens):平均响应1.0秒,费用$0.03/千次
4. 总结
Chain of Draft并非简单的“压缩”,而是对LLM推理本质的重新思考。它证明:高质量的思维输出无需冗长,关键信息的提取与传递才是核心。
对于企业而言,这项技术可立竿见影地降低80%以上的推理成本;对于开发者,它提供了平衡性能与资源的全新范式。
参考:
- 论文地址:https://arxiv.org/abs/2502.18600
- GitHub代码库:https://github.com/sileix/chain-of-draft
如果觉得本文对你有帮助,麻烦点个赞和关注呗 ~~~
- 大家好,我是 同学小张,持续学习C++进阶、OpenGL、WebGL知识和AI大模型应用实战案例
- 欢迎 点赞 + 关注 👏,持续学习,持续干货输出。
- +v: jasper_8017 一起交流💬,一起进步💪。
- 微信公众号搜【同学小张】 🙏
私信免费领取AI、C++等相关资料,持续收集更新中! 包括但不限于:
清华大学 - DeepSeek资料合集(多篇)
DeepSeek指导手册(24页).pdf
《如何向 ChatGPT 提问以获得高质量答案:提示技巧工程完全指南》
《OpenAI:GPT 最佳实践(大白话编译解读版)》
人工智能精选电子书




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











