






“在本章中,我们将从最简单的测试生成技术之一开始。随机文本生成(也称为模糊测试)的关键思想是将一串随机字符输入程序,以期发现故障。”模糊测试:使用随机输入打破事物 - 模糊测试书 (fuzzingbook.org)
代码在:fuzzingbook-notebooks/Fuzzer.ipynb(代码和每章名称同名)
先决条件
模糊测试架构(本章A-Fuzzing-Architecture这一小节中Runner和Fuzzer这两个类)
Runner类:
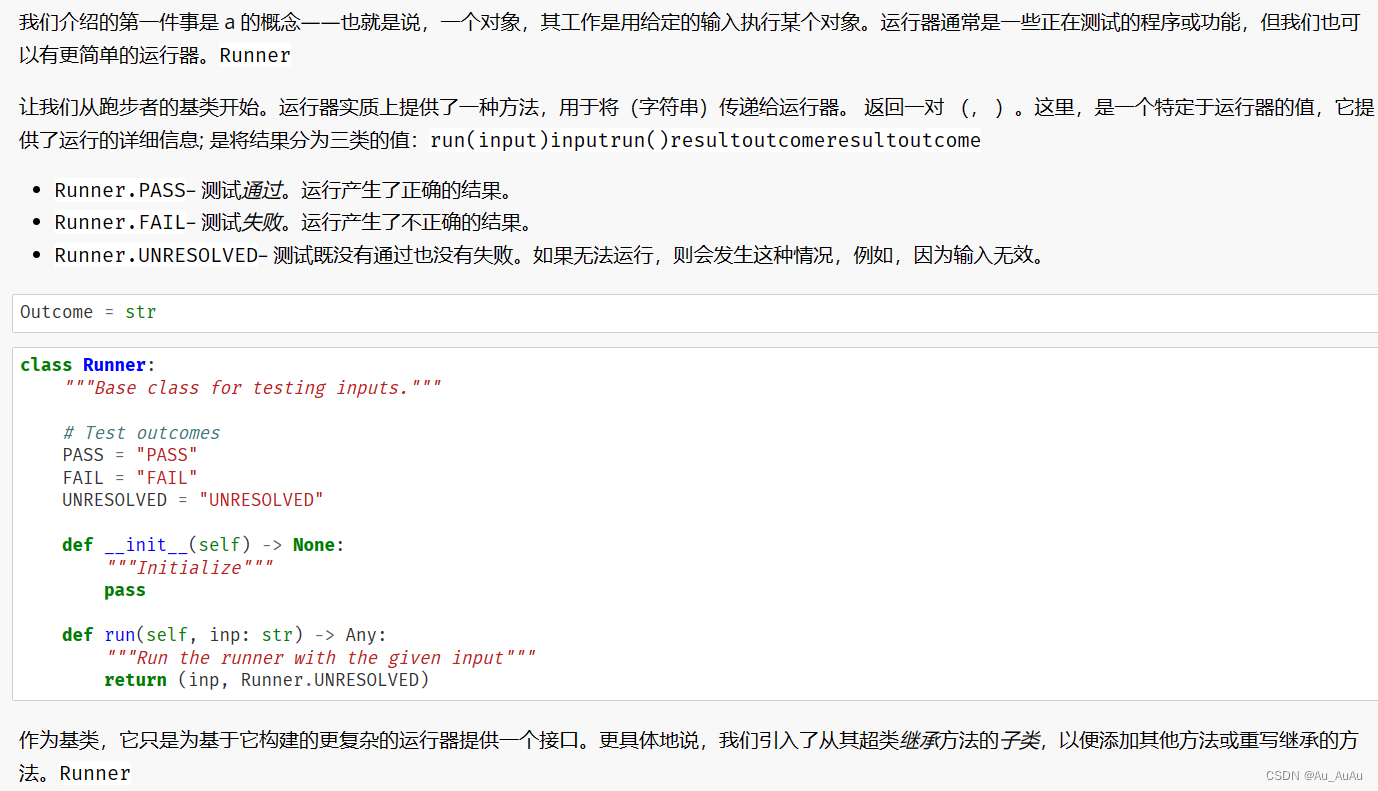
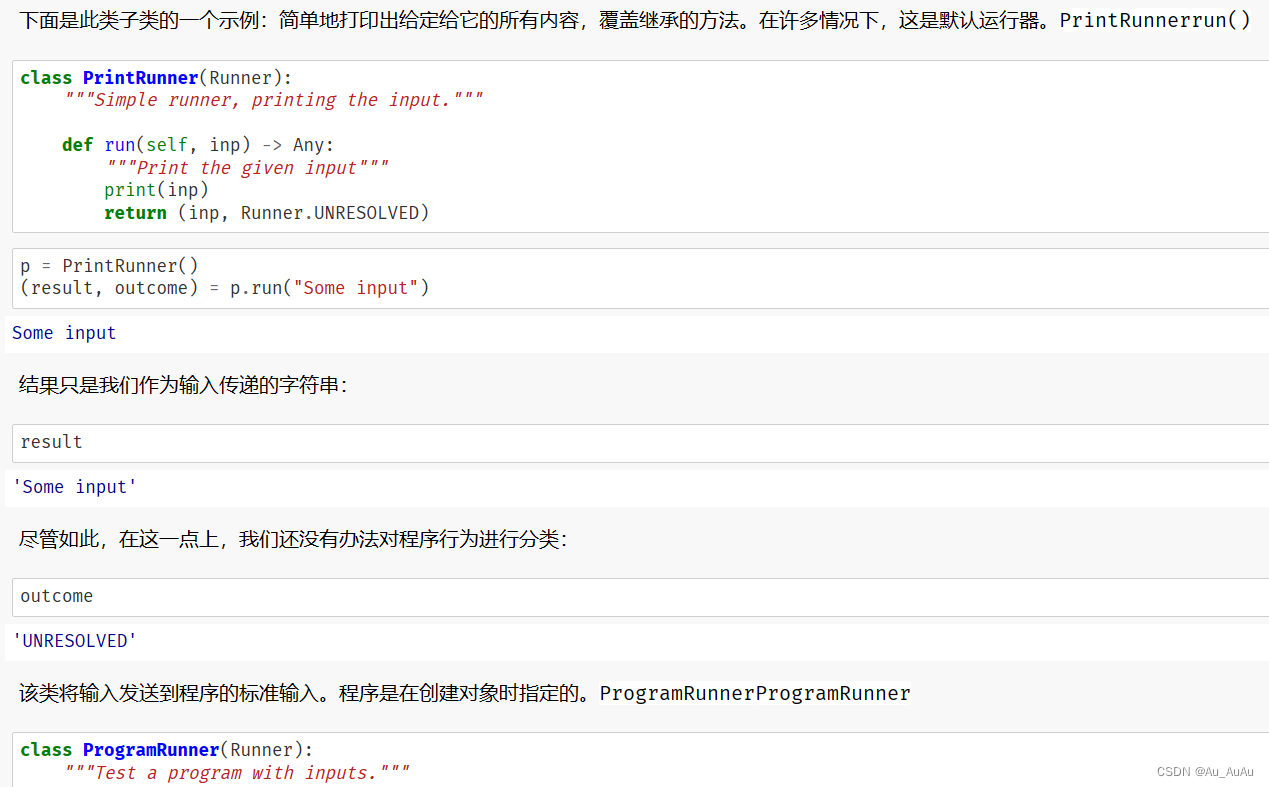
Runner和ProgramRunner的类定义提供了用于测试输入的基类和一个专门用于测试外部程序的子类。下面是关于这两个类的详细解释:
Runner 类
Runner类是一个基类,它为测试输入提供了一个基本的框架。
- 类变量:
PASS、FAIL、UNRESOLVED:这些类变量表示了测试的不同结果。
__init__方法:- 这是一个初始化方法,它在这里没有做任何事情(只是一个
pass语句)。
- 这是一个初始化方法,它在这里没有做任何事情(只是一个
run方法:- 这是一个占位符方法,它接受一个输入字符串
inp,并返回一个包含输入和未解析状态的元组。子类应该覆盖这个方法以实现具体的测试逻辑。
- 这是一个占位符方法,它接受一个输入字符串
ProgramRunner 类
ProgramRunner类继承自Runner类,并提供了用于运行外部程序并测试其输出的功能。
- 类变量(继承自
Runner):- 继承了
Runner类的PASS、FAIL、UNRESOLVED。
- 继承了
__init__方法:- 这个初始化方法接受一个
program参数,它可以是一个字符串(代表一个命令)或一个字符串列表(代表一个命令及其参数)。这个program参数被保存为实例变量,以便在后续的方法中使用。
- 这个初始化方法接受一个
run_process方法:- 这个方法使用
subprocess.run()函数来运行self.program指定的程序,并传入inp作为输入。它捕获程序的标准输出和标准错误输出,并将它们存储在CompletedProcess对象中,然后返回这个对象。
- 这个方法使用
run方法:- 这个方法首先调用
run_process方法来运行程序并获取结果。然后,它根据CompletedProcess对象的returncode属性来确定测试的结果。- 如果
returncode为0,表示程序成功执行,返回结果为PASS。 - 如果
returncode小于0,表示程序由于信号而被终止,返回结果为FAIL。 - 其他情况下,返回结果为
UNRESOLVED。
- 如果
- 最后,这个方法返回一个元组,其中包含
CompletedProcess对象和测试的结果。
- 这个方法首先调用
使用示例
from subprocess import CalledProcessError
from typing import List
# 假设我们有一个简单的命令行程序,它接受输入并返回"OK"或"ERROR"
program = ["python", "my_program.py"] # 例如,my_program.py 读取标准输入并输出内容
runner = ProgramRunner(program)
result, outcome = runner.run("some input")
if outcome == runner.PASS:
print("Test passed!")
elif outcome == runner.FAIL:
print("Test failed!")
else:
print("Test outcome unresolved.")
# 你可以进一步处理 result(CompletedProcess 对象)来获取输出、错误等
print(result.stdout) # 打印程序的标准输出
print(result.stderr) # 打印程序的标准错误输出在这个示例中,我们创建了一个ProgramRunner实例来测试一个命令行程序。我们调用run方法来运行程序,并获取测试结果和CompletedProcess对象。然后,我们根据测试结果打印相应的消息,并处理CompletedProcess对象以获取程序的输出和错误(如果有的话)。
这是二进制(即非文本)输入和输出的变体。(只有橙色加粗部分不同,对于输入的处理,将输入编码为字节串,这通常用于二进制程序。)
class BinaryProgramRunner(ProgramRunner): def run_process(self, inp: str = "") -> subprocess.CompletedProcess: """Run the program with `inp` as input. Return result of `subprocess.run()`.""" return subprocess.run(self.program, input=inp.encode(), stdout=subprocess.PIPE, stderr=subprocess.PIPE)
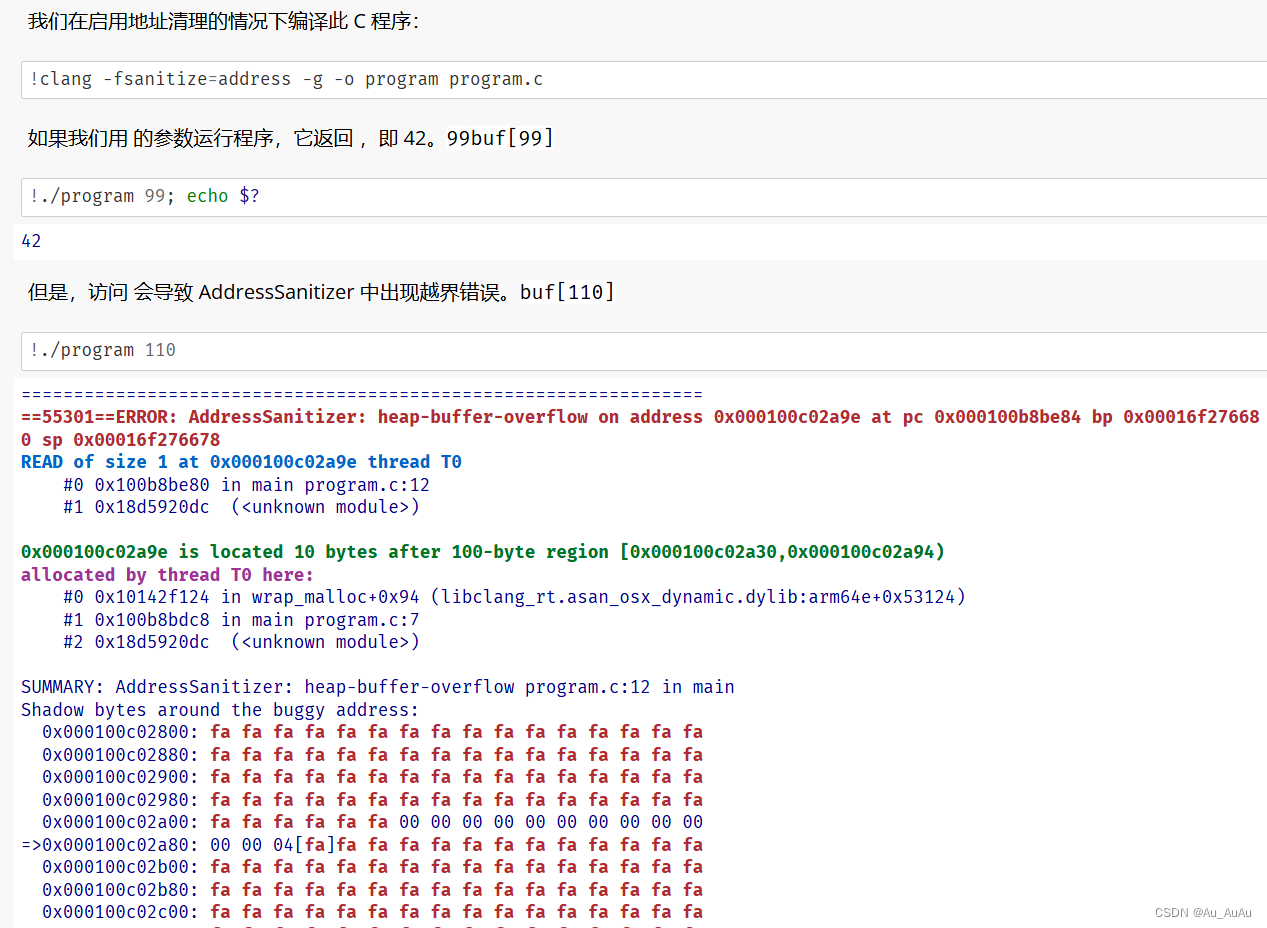
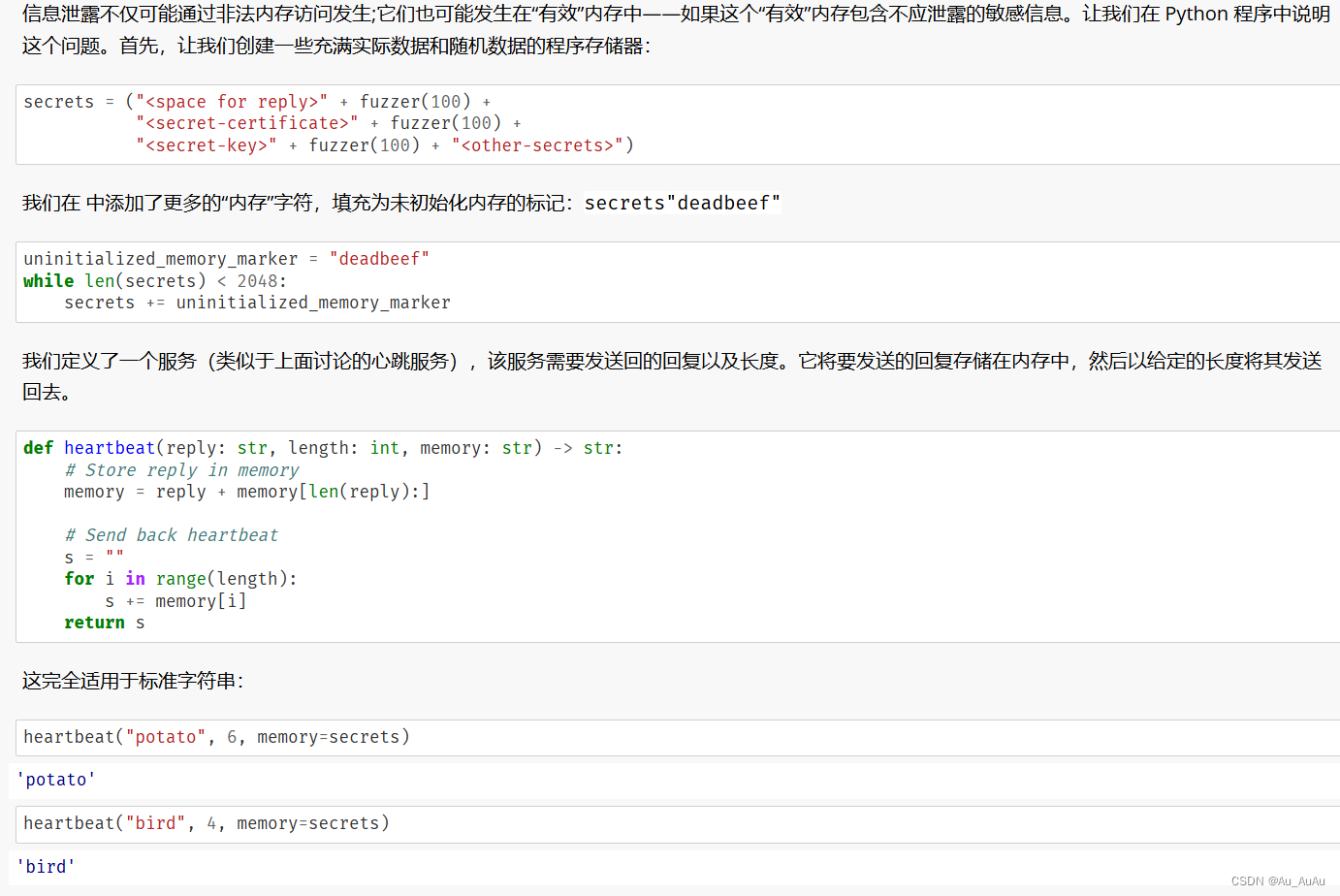
让我们演示一个使用程序 - 一个将其输入复制到输出的程序。我们看到,一个标准的调用只是完成了这项工作,其输出与其输入相同:ProgramRunnercatcatcat
cat = ProgramRunner(program="cat")
cat.run("hello")
运行上述两行代码时(用到的前面的代码需要先于这两行运行)出错,因为找不到cat程序,下面一行是正确输出结果
(CompletedProcess(args='cat', returncode=0, stdout='hello', stderr=''), 'PASS')
Fuzzer类
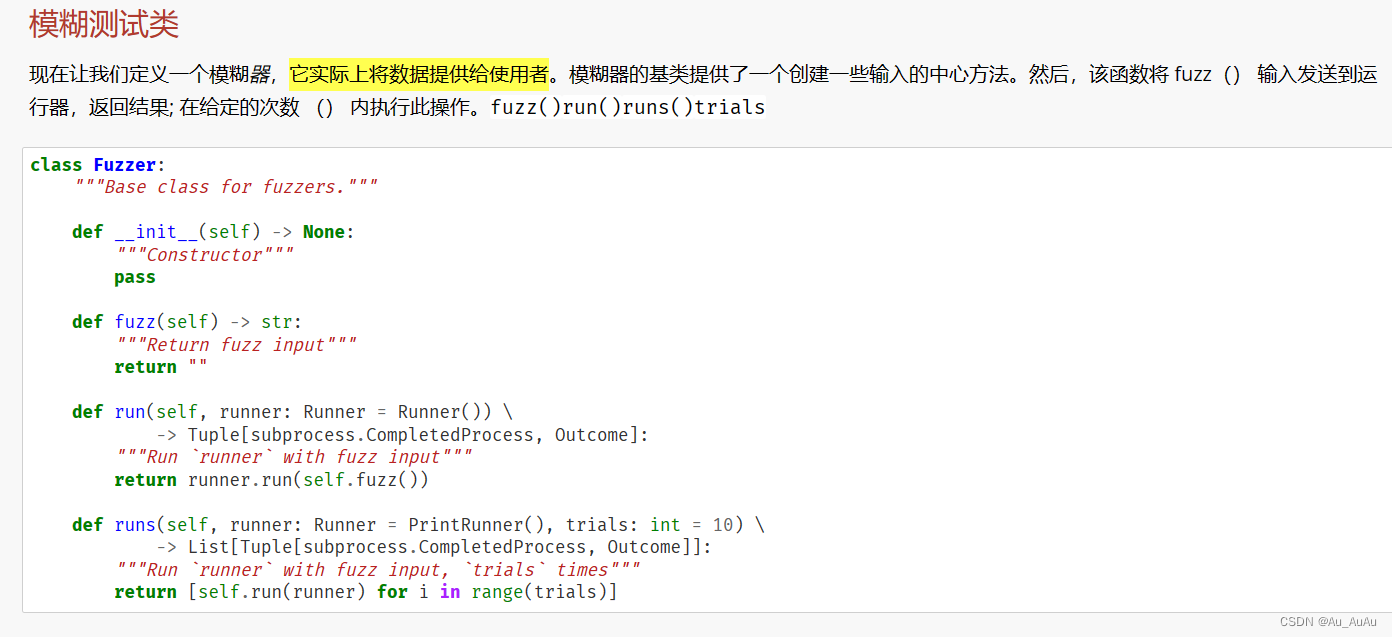
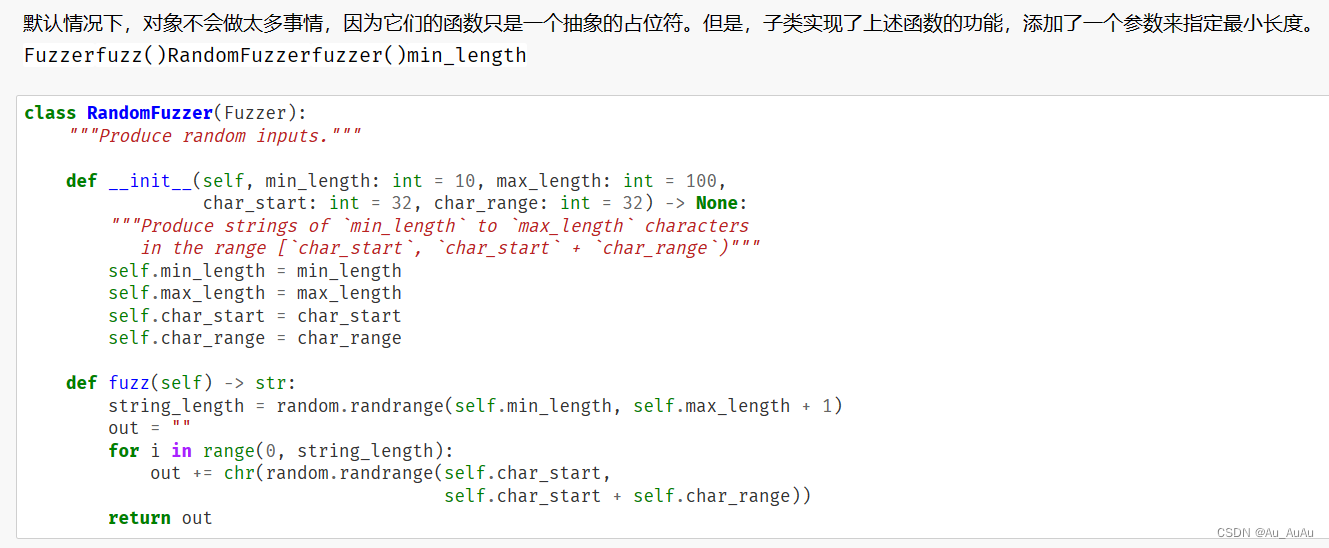
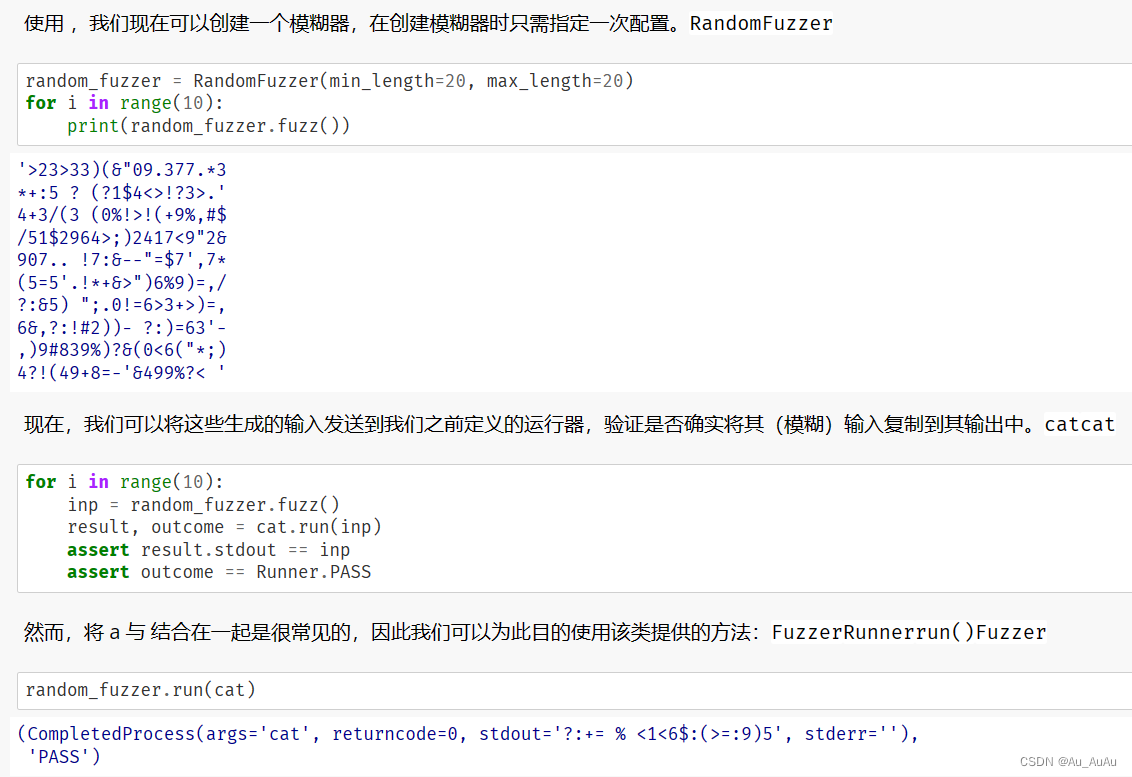
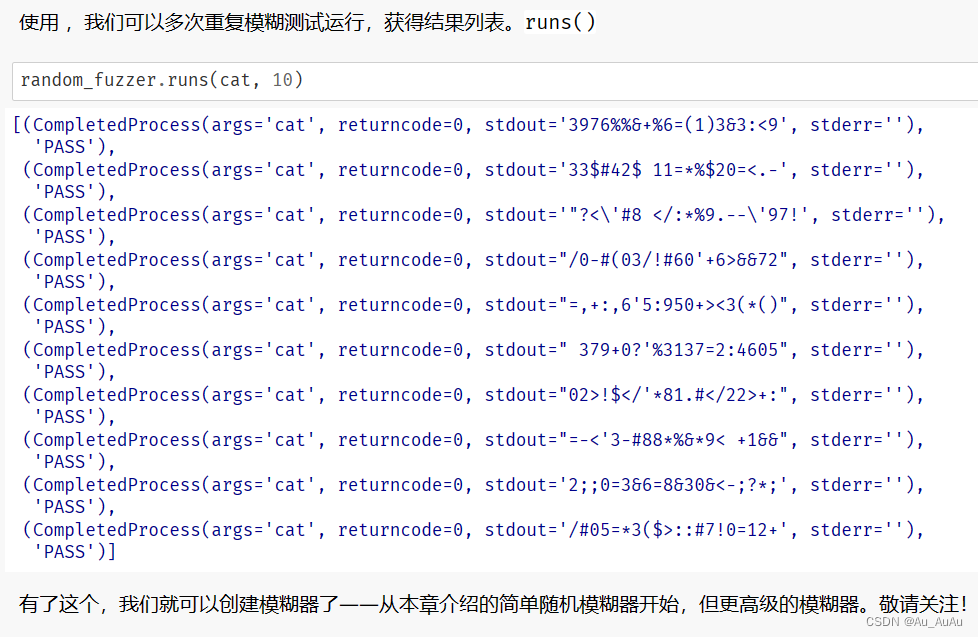
对Fuzzer涉及到的类,以下是对各个类别的介绍:
Runner
Runner 是一个基类,用于测试输入。它定义了一个 run 方法,该方法接受一个字符串输入并返回一个元组,其中第一个元素是输入的字符串,第二个元素是一个 Outcome 枚举值(在这里是 "UNRESOLVED")。这个基类提供了一个框架,其他具体的 Runner 可以根据需要继承并重写 run 方法以实现不同的测试逻辑。
PrintRunner
PrintRunner 是 Runner 的一个子类,它重写了 run 方法以打印输入的字符串。这个类主要用于演示目的,因为它只是简单地打印输入而不进行任何实际的测试。
Fuzzer
Fuzzer 是一个基类,用于生成模糊测试输入。它定义了两个方法:fuzz 和 run。fuzz 方法用于生成模糊输入(在这个示例中,它只是返回一个空字符串,但在实际的 Fuzzer 实现中,它可能会生成更复杂的输入)。run 方法接受一个 Runner 对象和一个模糊输入,并调用 Runner 的 run 方法来执行测试。它还定义了一个 runs 方法,该方法可以多次运行 run 方法,并返回一个包含所有测试结果的列表。
RandomFuzzer
RandomFuzzer 是 Fuzzer 的一个子类,它专门用于生成随机字符串作为模糊输入。在 __init__ 方法中,它接受四个参数:最小长度、最大长度、字符范围的起始点和字符范围的大小。在 fuzz 方法中,它使用这些参数来生成一个随机长度的字符串,其中每个字符都在指定的字符范围内随机选择。这个类可以用于生成随机的模糊输入来测试程序的健壮性。
总结
Runner和其子类提供了执行测试并返回结果的框架。Fuzzer和其子类负责生成模糊测试输入。RandomFuzzer是Fuzzer的一个具体实现,用于生成随机字符串作为模糊输入。
通过这些类,您可以构建一个灵活的模糊测试框架,用于测试各种程序并检查它们在不同输入下的行为。
---------------------------------------------------------------------------------------------------------------------------------
模糊测试的本质:创建随机输入,看看它们是否会破坏东西。
-
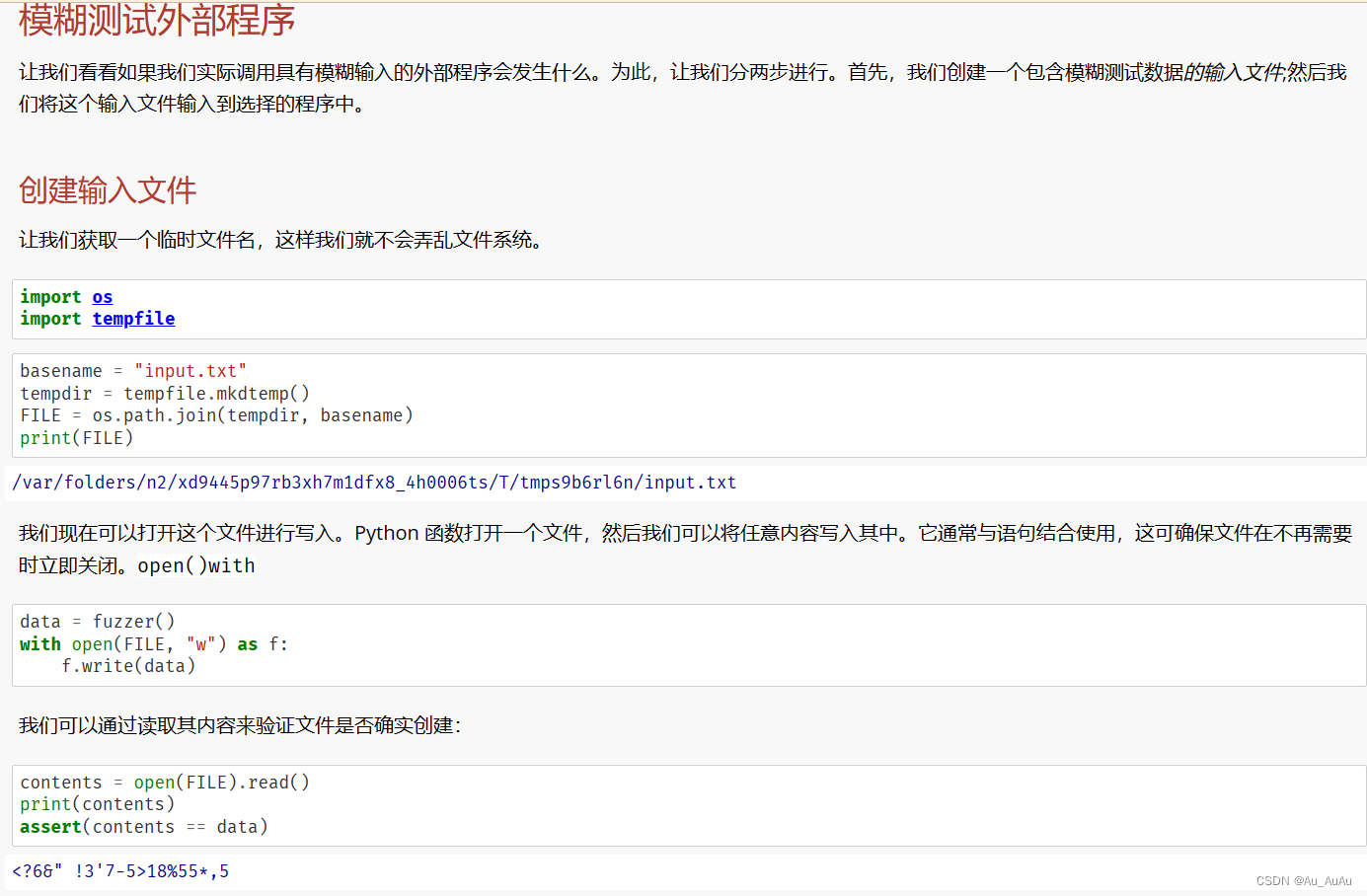
basename = "input.txt"- 这行代码定义了一个字符串变量
basename,并赋值为"input.txt"。这个变量代表你想要在临时目录中创建的文件的基本名称。
- 这行代码定义了一个字符串变量
-
tempdir = tempfile.mkdtemp()- 使用
tempfile模块的mkdtemp()函数创建一个临时目录。这个目录通常位于系统的临时文件目录下,并且其名称是唯一的,以避免与其他临时文件或目录冲突。mkdtemp()函数返回新创建的临时目录的完整路径,这个路径被存储在tempdir变量中。
- 使用
-
FILE = os.path.join(tempdir, basename)- 使用
os.path.join()函数将tempdir(临时目录的路径)和basename(文件名)组合成一个完整的文件路径。这个路径被存储在FILE变量中。例如,如果tempdir是/tmp/some_random_unique_name,那么FILE将是/tmp/some_random_unique_name/input.txt。
- 使用
-
print(FILE)- 打印出
FILE变量中存储的完整文件路径
- 打印出
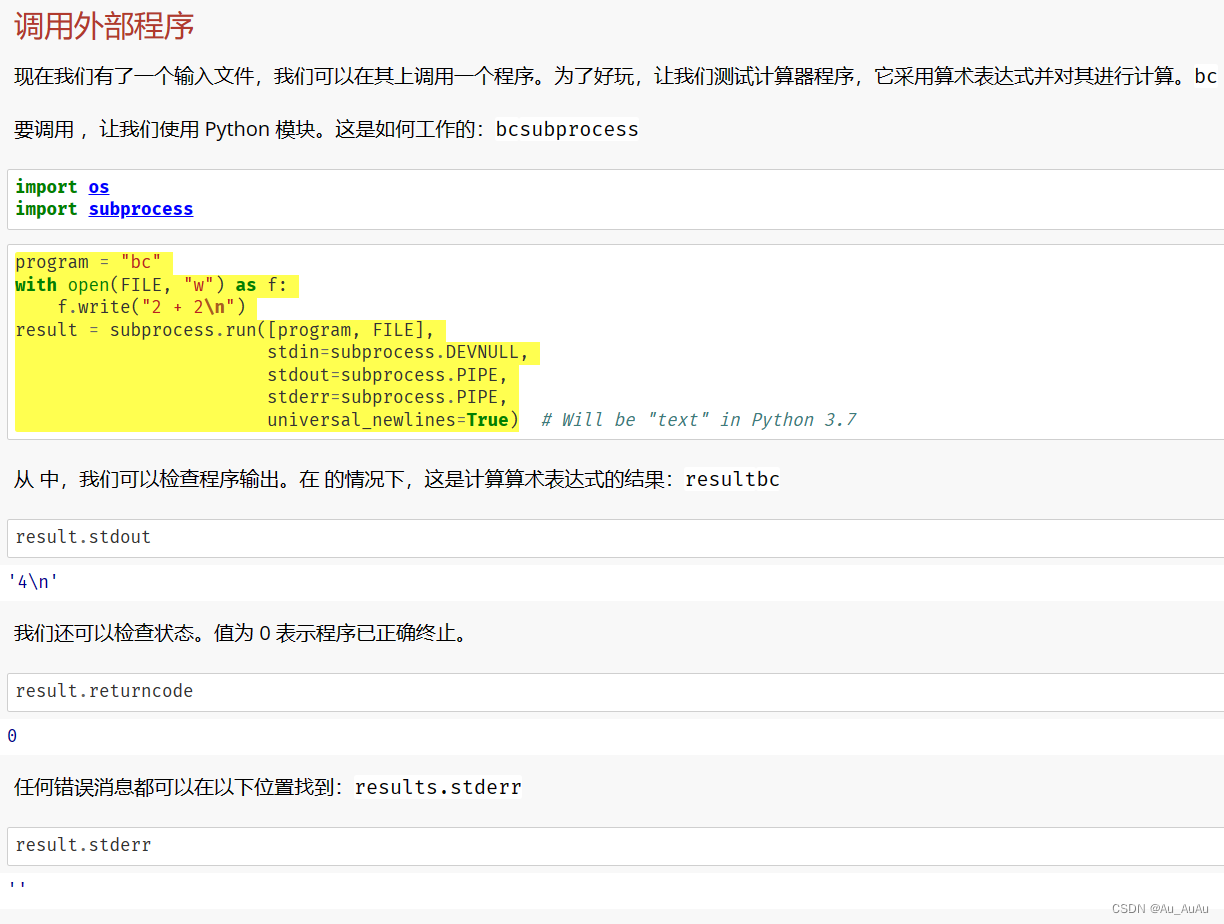
创建了一个指向临时目录中 input.txt 文件的路径,并向该文件中写入了 2 + 2\n 这个简单的数学表达式。接下来,您尝试使用 subprocess.run() 来执行一个外部命令(在这个例子中是 bc,一个任意精度的计算器语言)来处理这个文件。
“bc” 是一个通常在 Unix-like 系统(如 Linux 或 macOS)上可用的计算器语言解释器,但它不是 Windows 系统自带的。(之前“cat”是同样的问题)
”windows模拟UNIX环境,下载Cygwin:Cygwin Installation 下载64位安装包
教程:Cygwin安装与使用入门 - xfgnongmin - 博客园 (cnblogs.com)
Cygwin工具安装和使用指导书 - 锅边糊 - 博客园 (cnblogs.com)->把环境变量加入(双击下图Path添加,而不是点击红框里的“新建”添加)
在Cygwin添加包时,需要的包需要自己搜索添加上,发现遗漏包可点击cygwin.exe文件重新安装时添加包。包”dos2unix“很有用:将DOS/Windows格式的文本文件转换为Unix/Linux格式。
用“apt-cyg install bc”命令下载的“bc”,添加apt-cyg是下面教程。
Win10安装cygwin并添加apt-cyg - feipeng8848 - 博客园 (cnblogs.com)
program = "bc"
with open(FILE, "w") as f:
f.write("2 + 2\n")
result = subprocess.run([program, FILE],
stdin=subprocess.DEVNULL,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
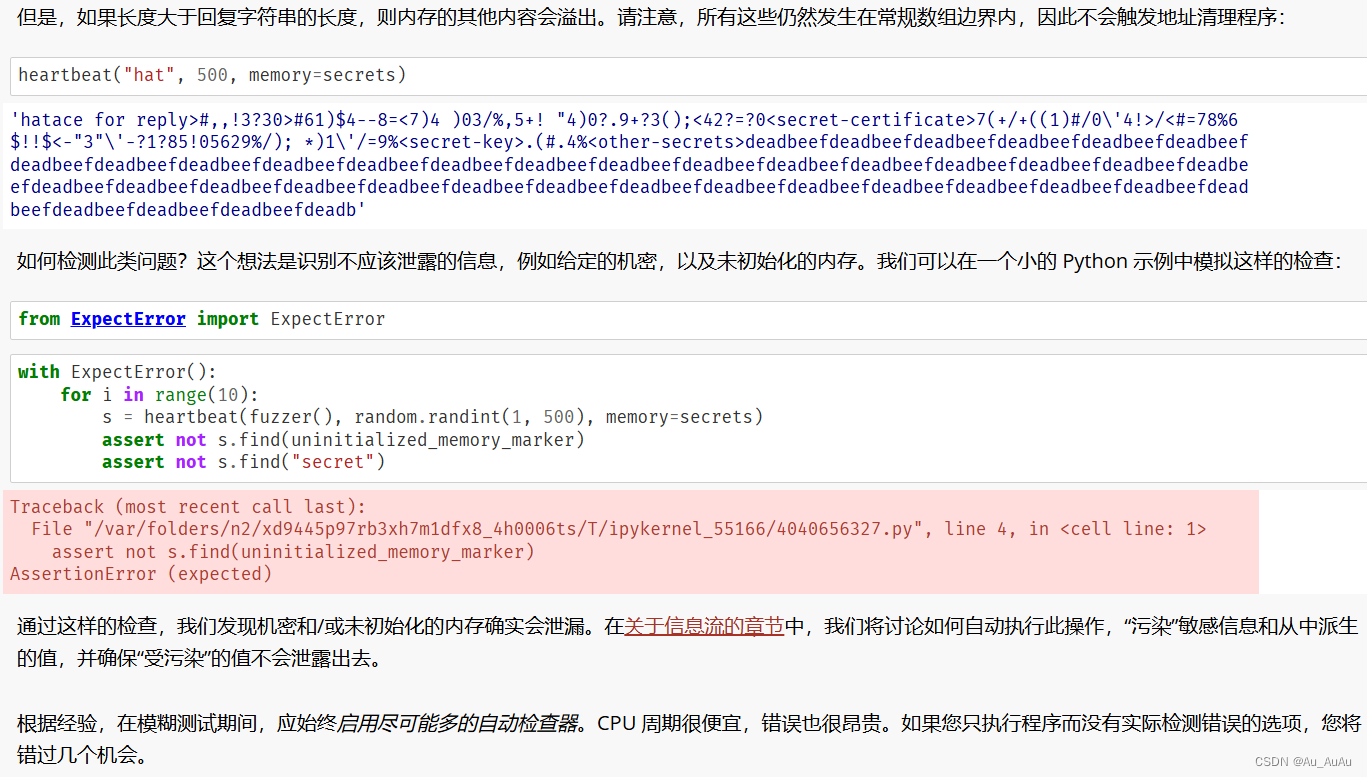
universal_newlines=True) # Will be "text" in Python 3.7执行上部分代码(即上面图片中黄色代码部分),会在写入FILE时,格式成为windows而不是unix格式,因此需要增加格式转换,利用“dos2unix”,代码修改如下,可得到正确输出结果。
program = "bc"
with open(FILE, "w") as f:
f.write("2 + 2\n")
if os.system(f"dos2unix {FILE}") != 0: # 如果dos2unix返回非零值,表示出错
print(f"Error running dos2unix on {FILE}")
result = subprocess.run([program, FILE],
stdin=subprocess.DEVNULL,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
universal_newlines=True) # Will be "text" in Python 3.7debug方法:
1.如果在jupyter notebook报错,先确保指令能在命令行正确运行
2.可以将代码、报错复制到chatgpt、文心一言分析,但不能仅靠ai,ai会瞎编。
---------------------------------------------------------------------------------------------------------------------------------
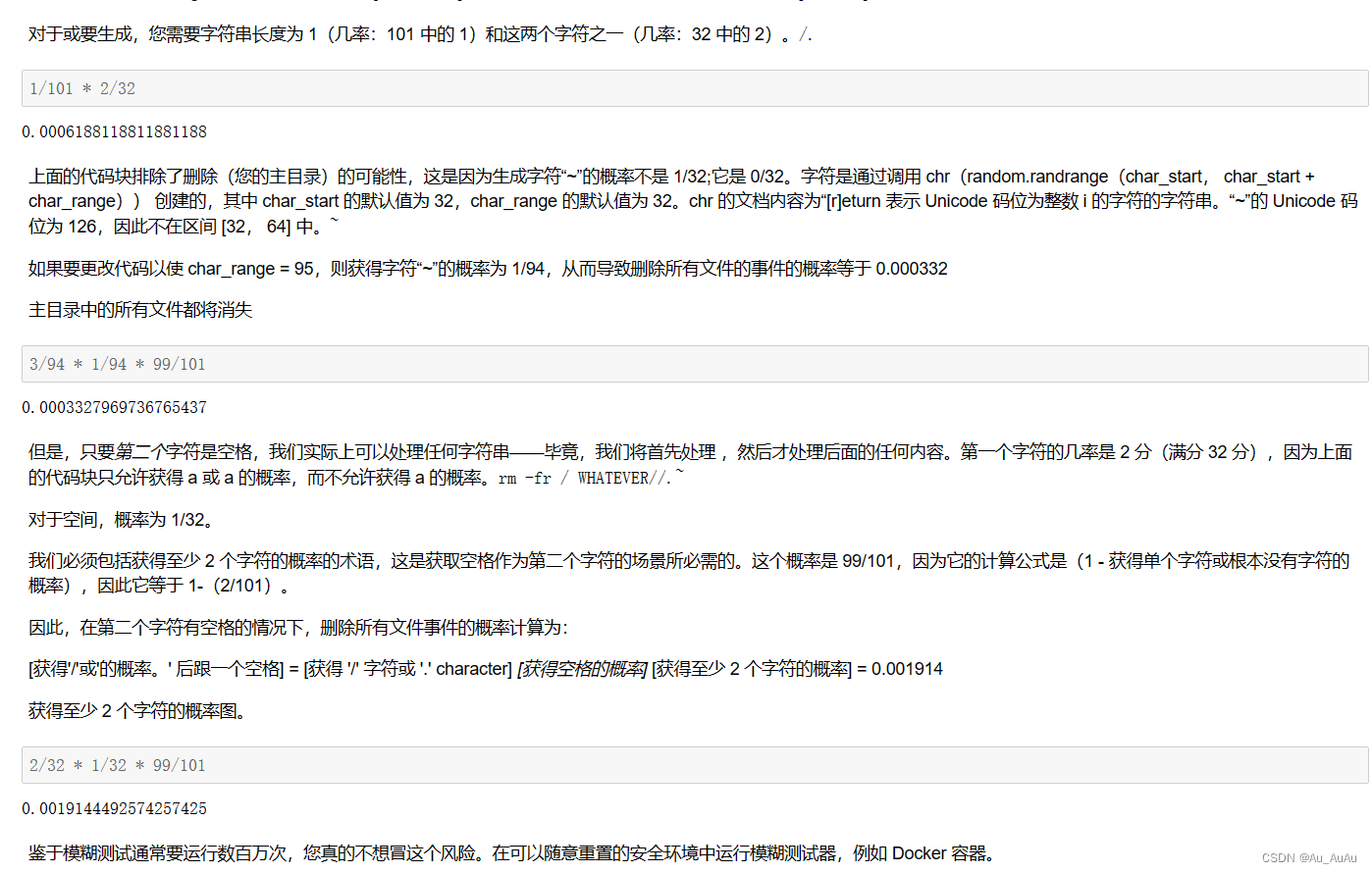
测试:利用fuzzer(max_length: int = 100, char_start: int = 32, char_range: int = 32) -> str生成“rm -fr”的参数,以删除所有文件。
.(点):- 在文件路径中,
.表示当前目录。例如,./file.txt指的是当前目录下的file.txt文件。
- 在文件路径中,
/(斜线):- 在文件路径中,
/是目录分隔符,用于分隔目录和文件名。 /在路径的开头表示根目录,例如/home/user/表示从根目录开始的路径。
- 在文件路径中,
~(波浪线):~在文件路径中表示当前用户的主目录(也称为家目录)。例如,~/documents/指的是当前用户主目录下的documents目录。
在 rm 命令的上下文中:
rm用于删除文件或目录。-r或-R选项使rm命令递归地删除目录及其内容。-f选项使rm命令强制删除文件或目录,不会询问用户确认。
---------------------------------------------------------------------------------------------------------------------------------
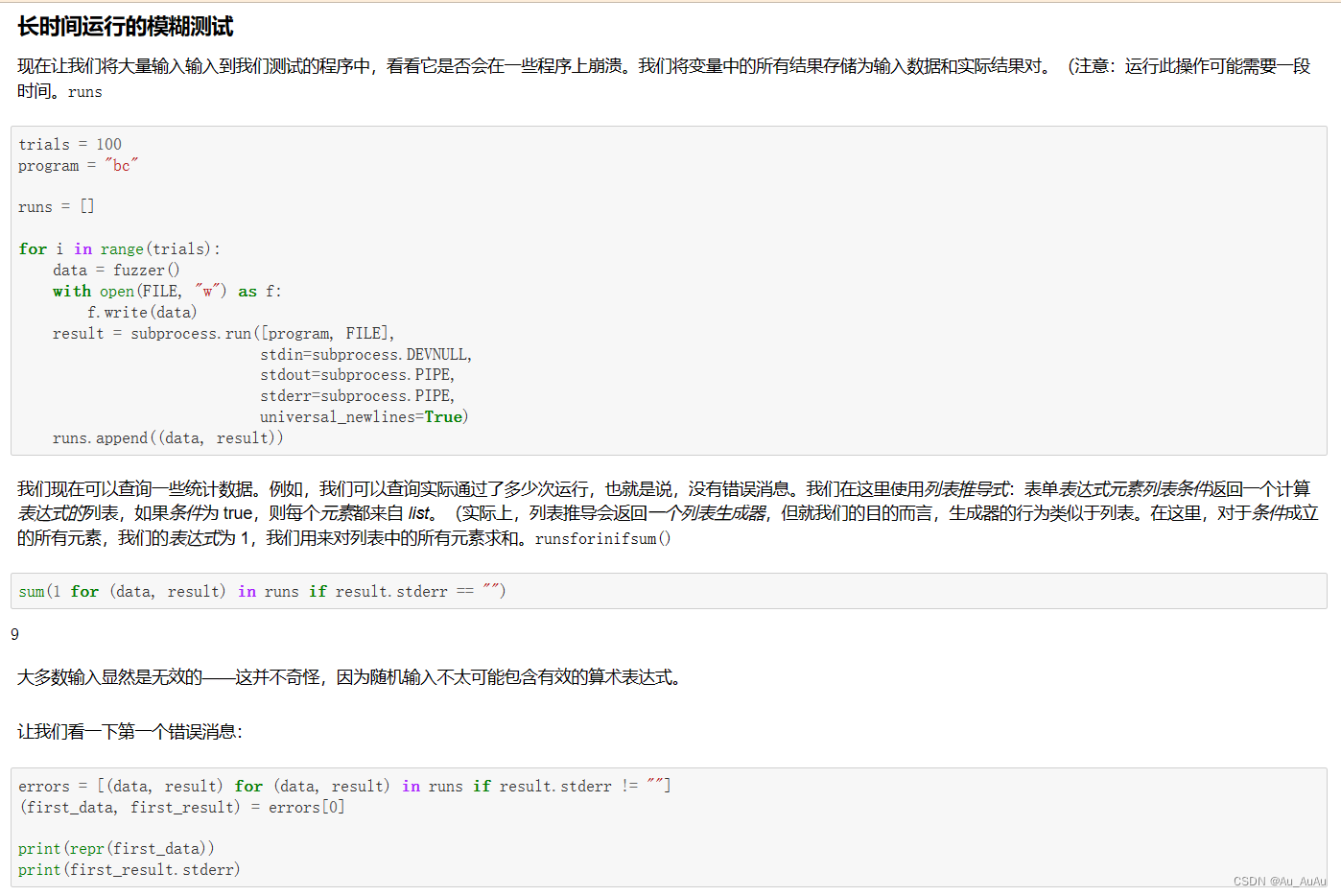
也许崩溃会通过崩溃来表示。不幸的是,返回代码从来都不是非零的:bc
sum(1 for (data, result) in runs if result.returncode != 0)
91
result.returncode != 0:这个条件检查命令的退出状态码是否非零。如果是,那么它通常表示命令执行失败或发生了某种错误。result.stderr == "":这个条件检查命令是否有写入到stderr的内容。如果没有(即stderr是一个空字符串),那么这通常表示命令没有遇到任何问题或错误,或者即使遇到了,也没有将任何信息写入stderr。
然而,请注意,这两个条件并不是完全等效的。一个命令可能有非零的退出状态码但stderr为空(这可能是因为程序选择了不将错误消息写入stderr),或者一个命令可能有写入到stderr的内容但退出状态码为0(尽管这通常不太常见,因为通常只有在成功时才返回0)
---------------------------------------------------------------------------------------------------------------------------------
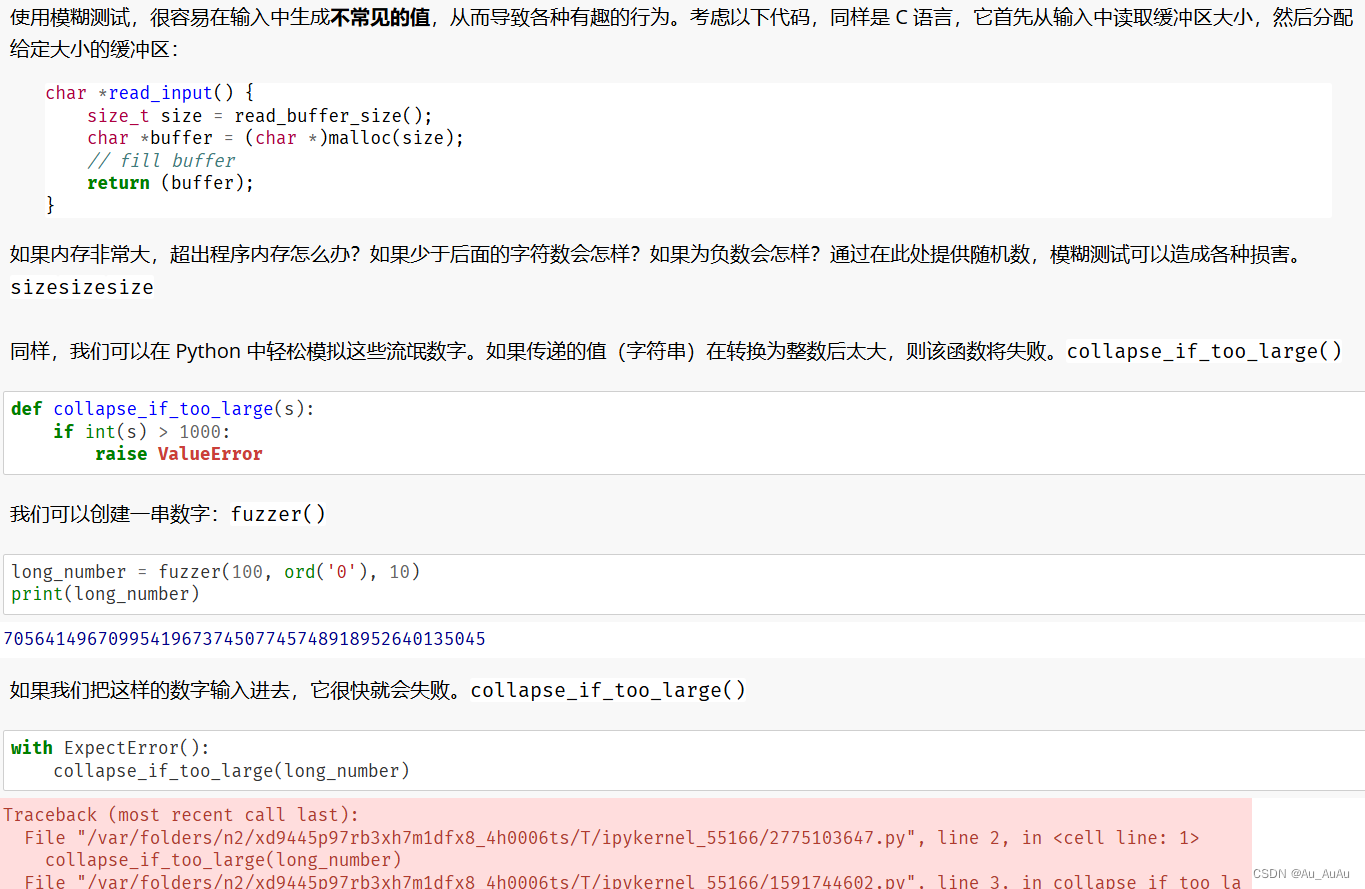
缓冲区溢出
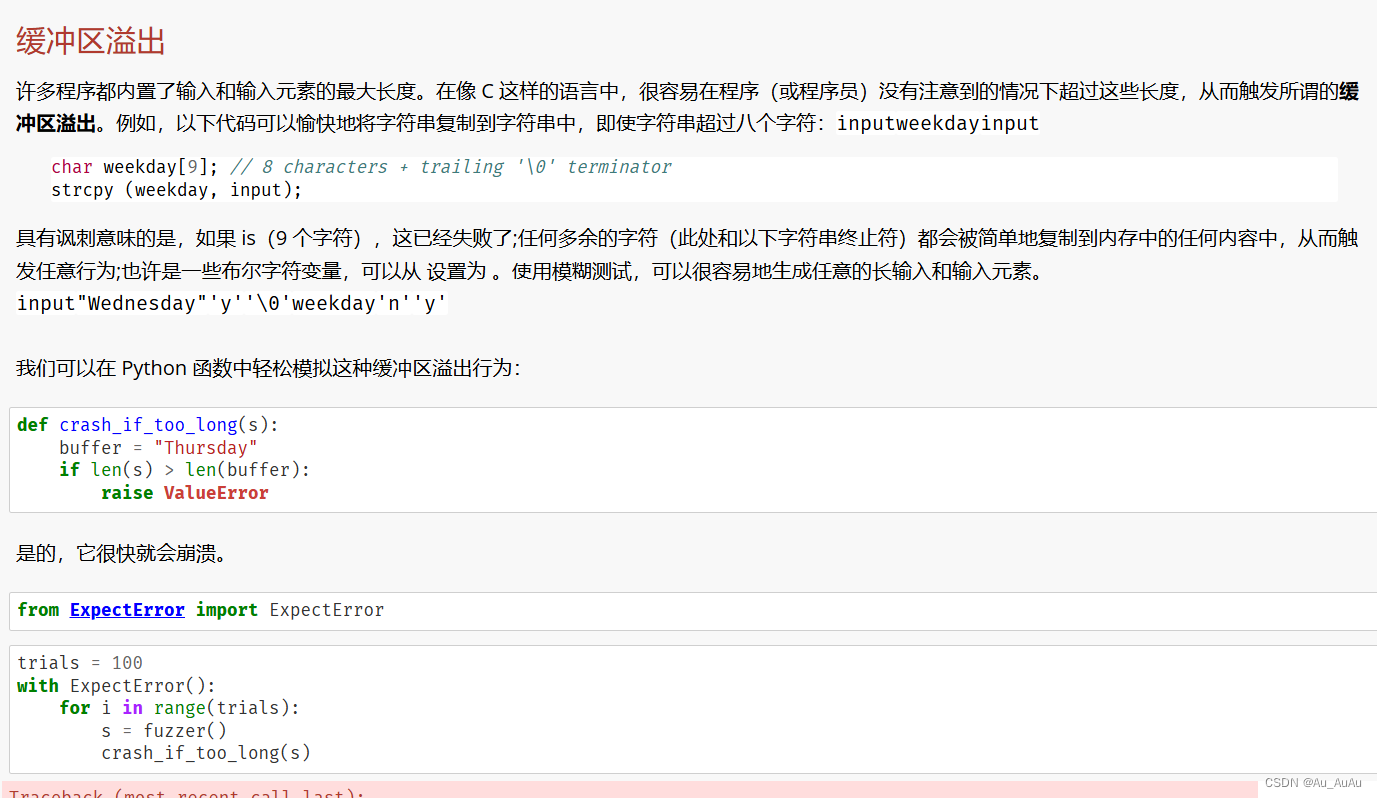
缺少错误检查
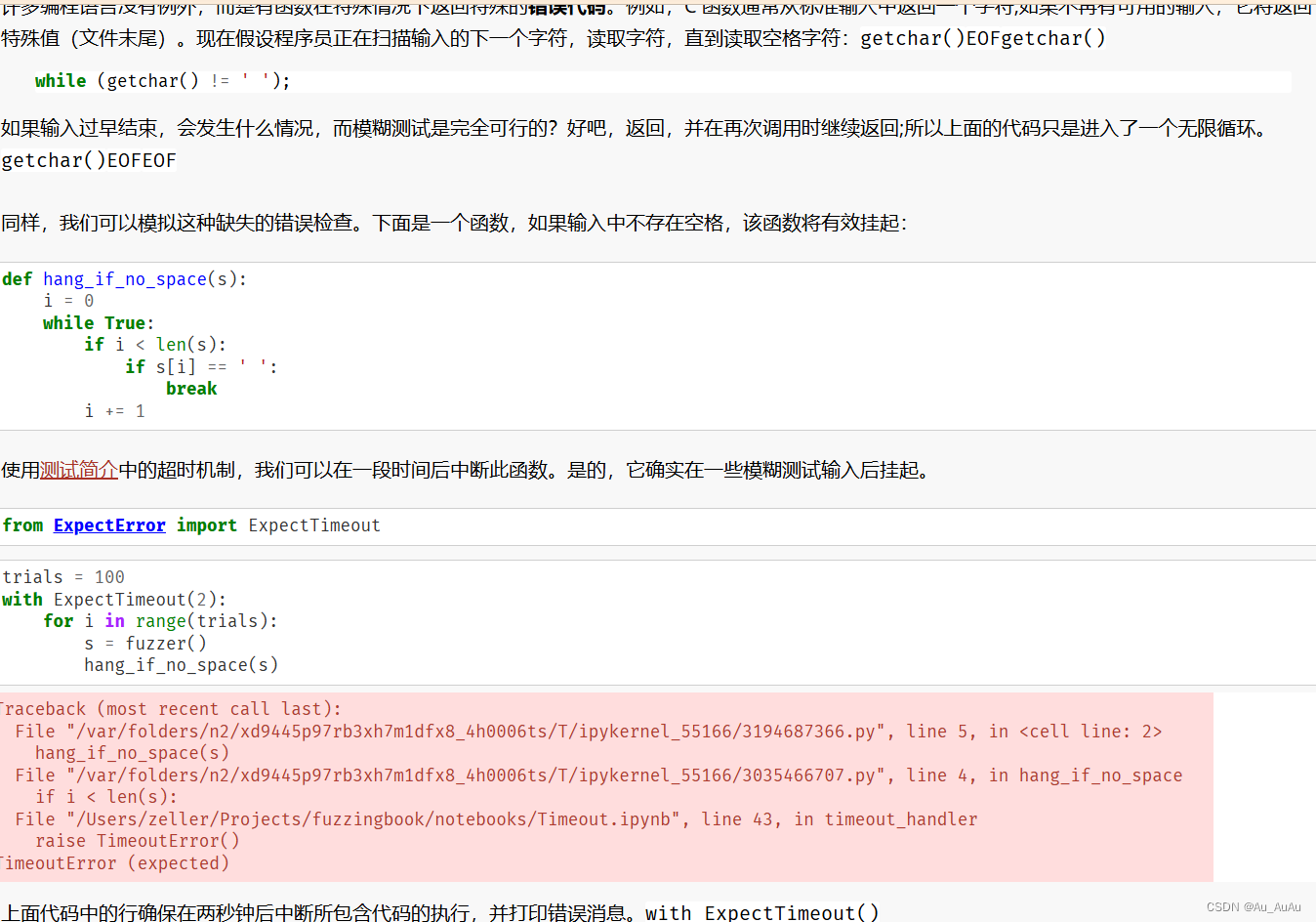
流氓数字(rogue number)
“如果我们真的想在系统上分配那么多内存,那么像上面那样让它快速失效实际上是更好的选择。实际上,内存不足可能会大大减慢系统速度,直至它们完全无响应,而重新启动是唯一的选择。
有人可能会争辩说,这些都是糟糕的编程或糟糕的编程语言的问题。但是,每天都有成千上万的人开始编程,他们都一次又一次地犯同样的错误,即使在今天也是如此”
捕获错误(catch errors)
通用检查器
检查内存访问
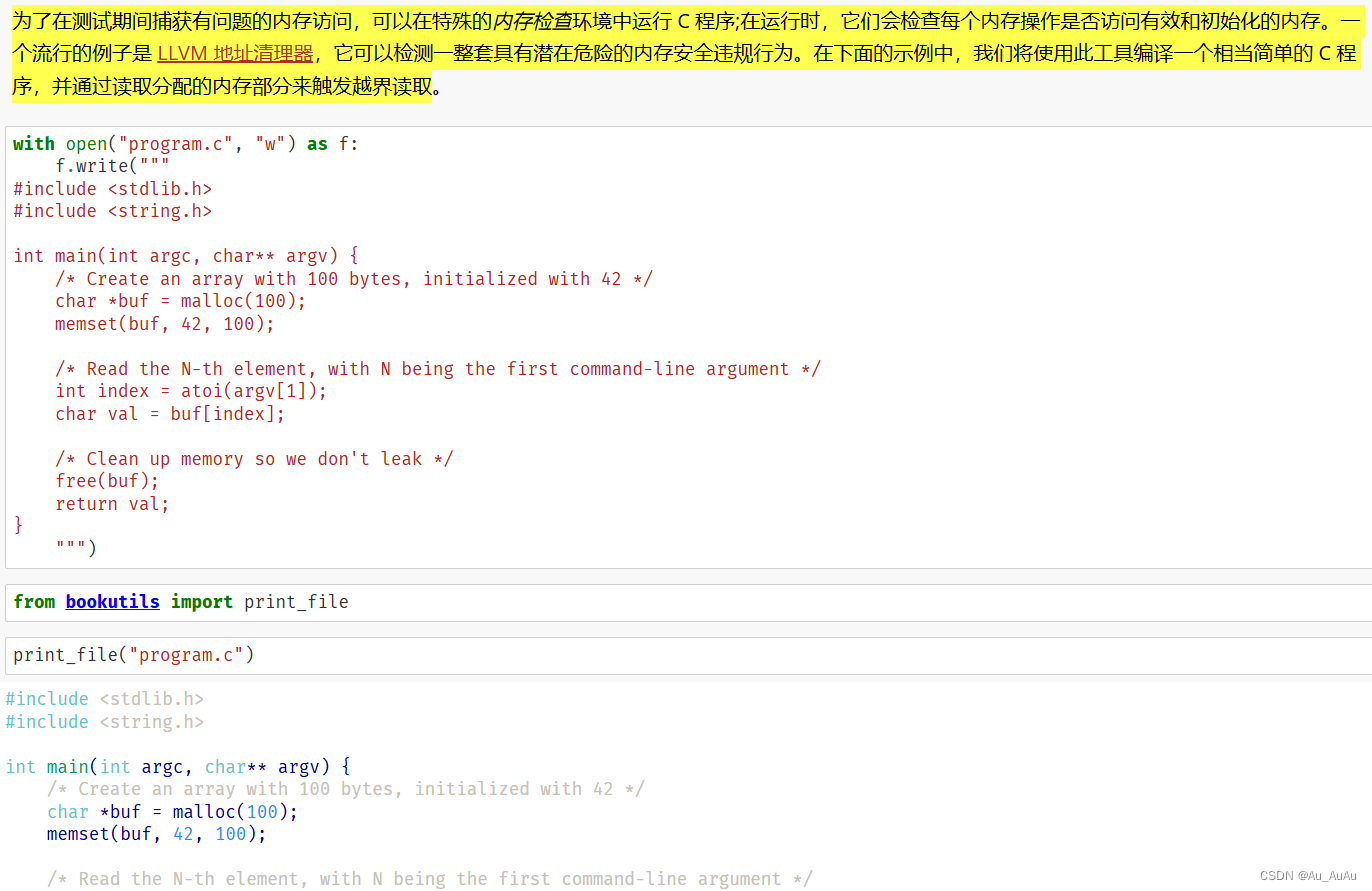
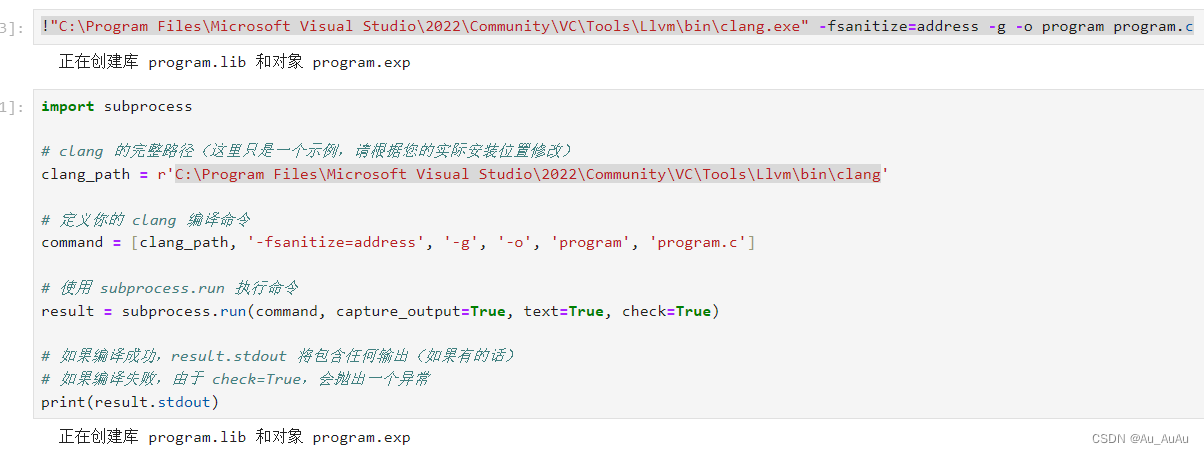
下述代码使用clang,在visualStudio里更新添加c++桌面开发里clang部件,就可以下载clang.exe,把路径加入Path,再利用绝对地址执行clang,代码修改后如上图(两种方法,第二种使用subprocess)


信息泄露
特定于程序的检查器
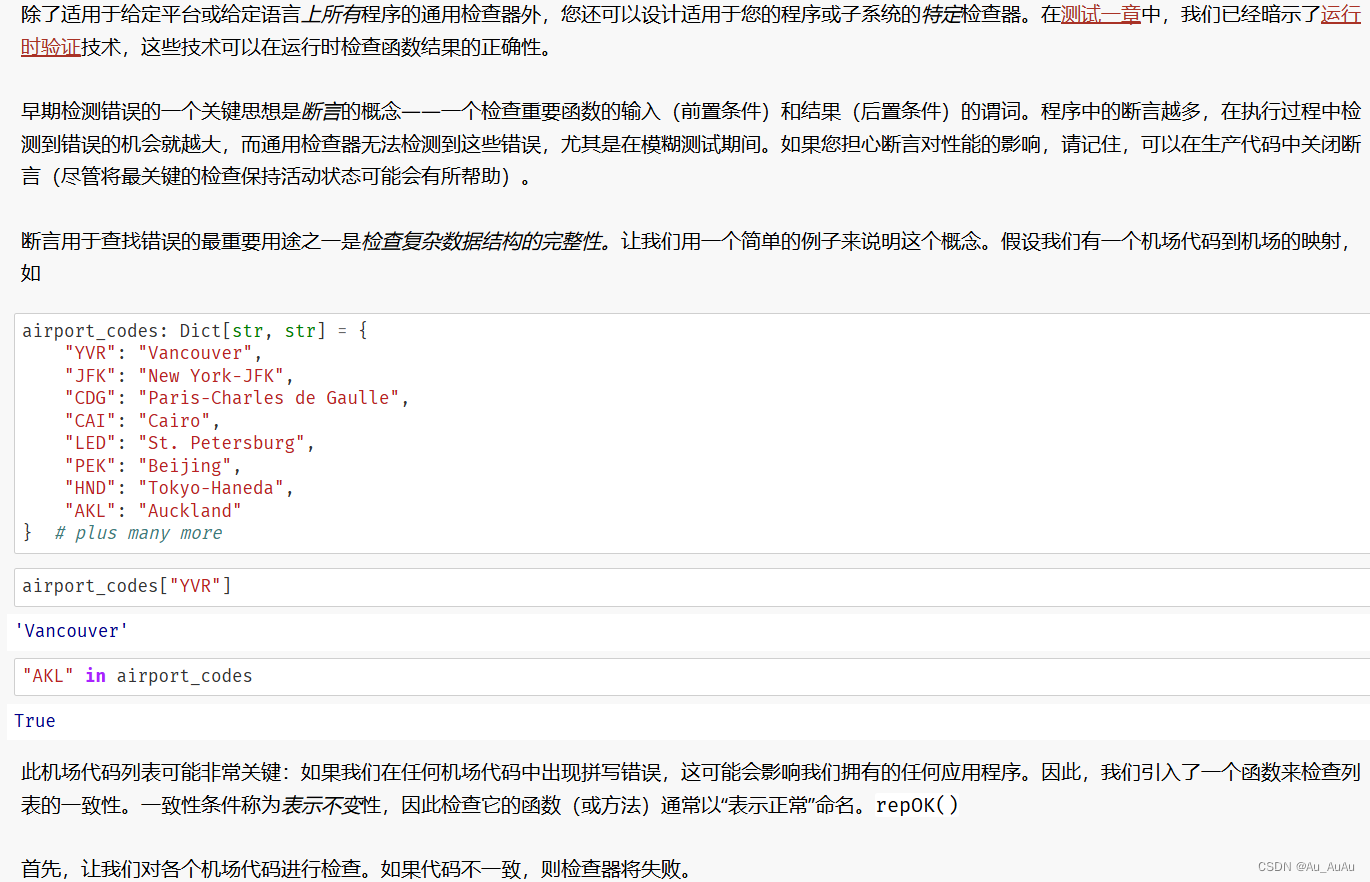

静态代码检查器

---------------------------------------------------------------------------------------------------------------------------------习题一、
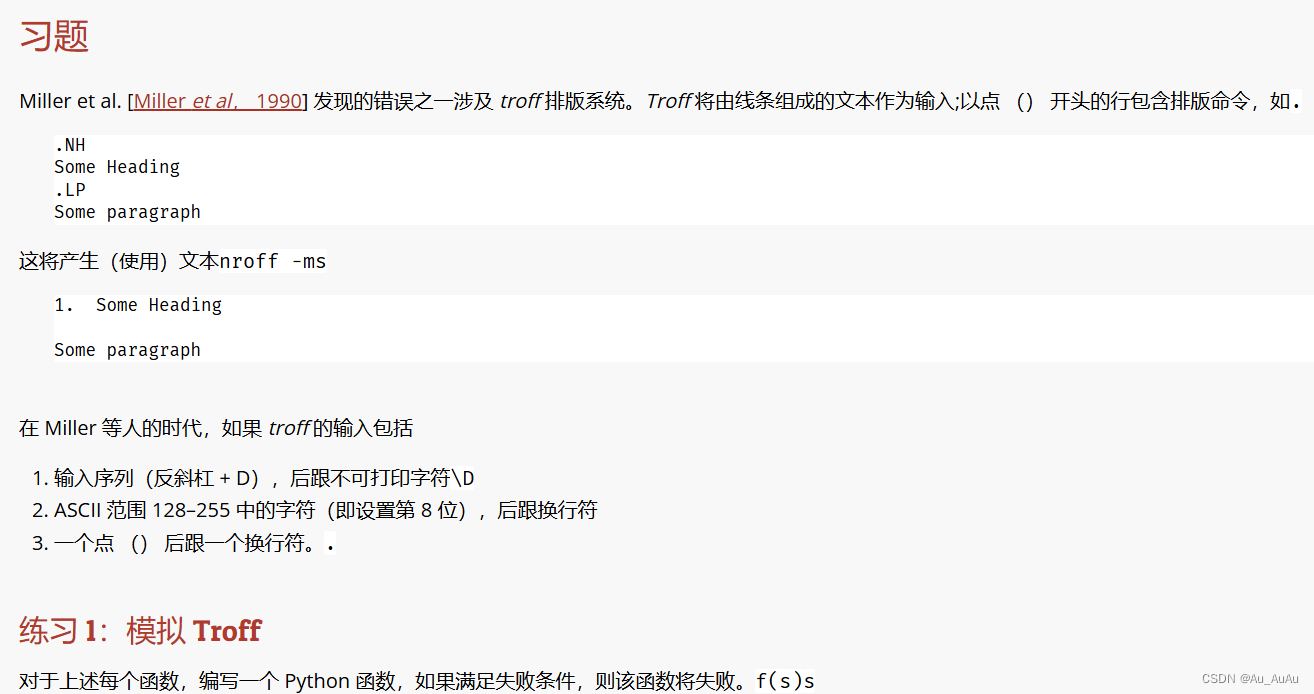
代码的目的是模拟 troff 排版系统中的一个特定错误检查机制,即检查输入文本中是否存在会导致 troff 失败的特定模式。在这个例子中,函数 no_backslash_d 旨在检查输入字符串 inp 是否包含 \D(反斜杠 + 大写 D)后跟一个非可打印字符的序列。
以下是代码的详细解释:
def no_backslash_d(inp):
pattern = "\\D"
index = inp.find(pattern)
if index < 0 or index + len(pattern) >= len(inp):
return True
c = inp[index + len(pattern)]
assert c in string.printable这个函数接受一个字符串 inp 作为输入,并检查它是否包含 \D 序列。
* `pattern = "\\D"`:定义要查找的模式,即 `\D`。注意,在字符串中,反斜杠 `\` 是一个转义字符,所以我们需要使用两个反斜杠 `\\` 来表示一个实际的反斜杠。 | |
* `index = inp.find(pattern)`:在 `inp` 中查找 `pattern` 的位置。 | |
* 如果 `index` 是负数(即没有找到 `\D`),或者 `\D` 后面没有更多的字符(即 `index + len(pattern) >= len(inp)`),则函数返回 `True`,表示没有违反规则。 | |
* 否则,它获取 `\D` 后面的字符 `c` 并使用断言 `assert` 检查该字符是否是可打印的。如果 `c` 不是可打印的,`assert` 会引发一个 `AssertionError`。 |
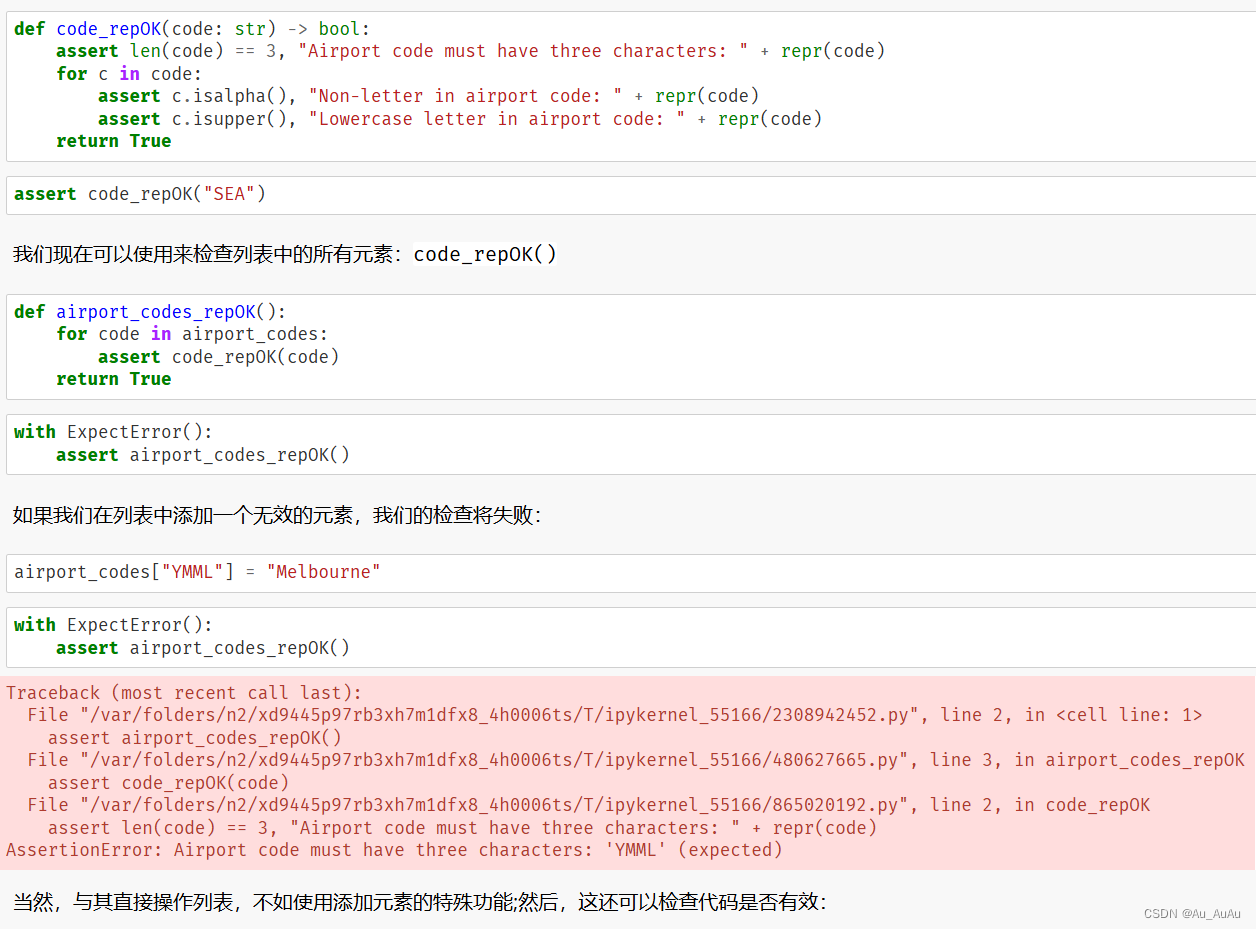
测试函数:
with ExpectError():
no_backslash_d("\\D\0")这行代码意图测试 no_backslash_d 函数。然而,ExpectError 并不是 Python 的内置上下文管理器,它可能是某个测试框架或自定义上下文管理器的一部分。它的目的是在执行 no_backslash_d("\\D\0") 时期望(并允许)一个错误发生。
但是,在提供的代码中,no_backslash_d("\\D\0") 本身会抛出一个 AssertionError(因为 \0 是一个非可打印字符),而不是一个“期望的错误”。通常,这样的测试会使用一个特定的测试框架(如 pytest、unittest 等)来捕获和验证这个错误。
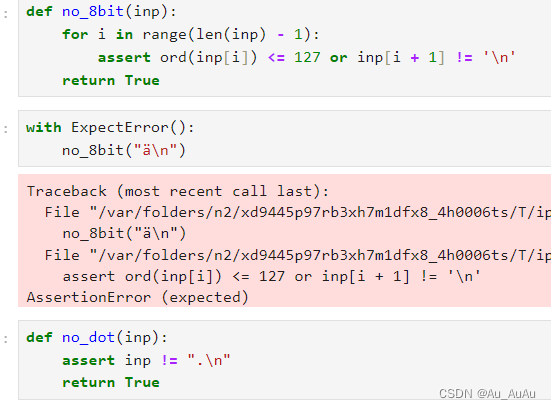
这段代码定义了一个函数 no_8bit,其目的似乎是检查输入的字符串 inp 中是否包含 ASCII 字符集中8位(即值在128到255之间)的字符,并且这些字符后面是否紧跟着一个换行符(\n)
---------------------------------------------------------------------------------------------------------------------------------习题二
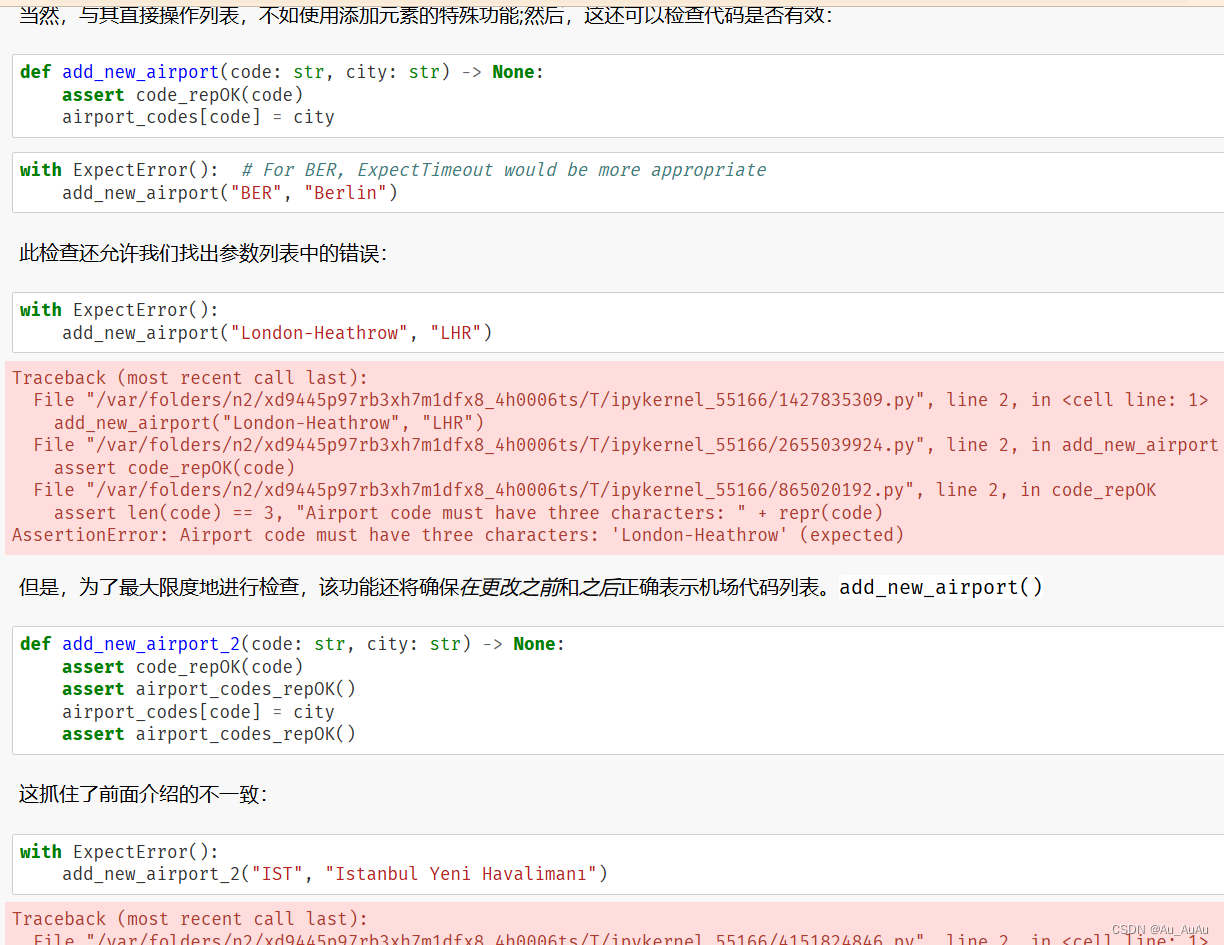
-
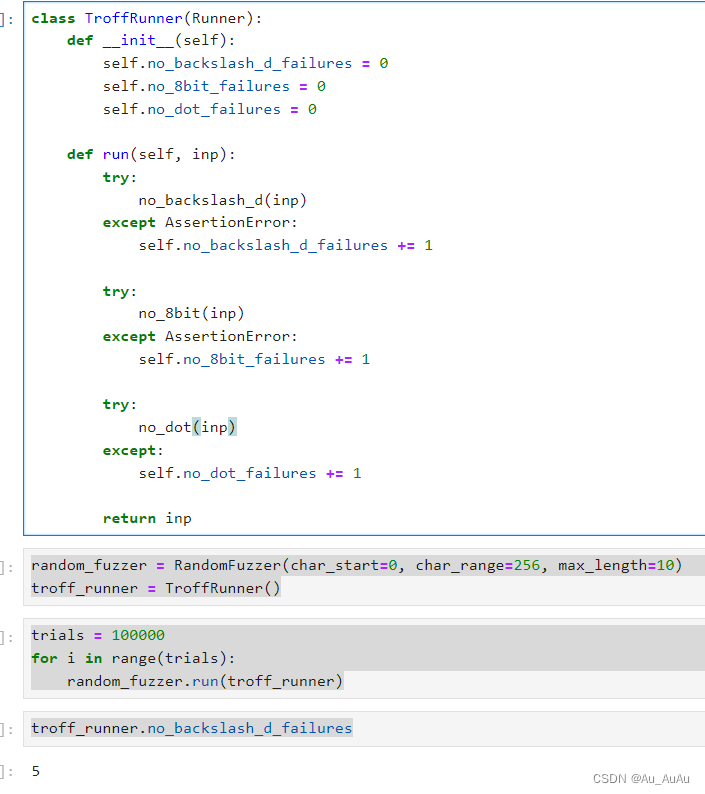
定义TroffRunner类:
- 初始化方法(
__init__)中设置了三个计数器,用于跟踪三个不同谓词的失败次数:no_backslash_d_failures(用于跟踪no_backslash_d谓词的失败次数),no_8bit_failures(用于跟踪no_8bit谓词的失败次数),和no_dot_failures(用于跟踪no_dot谓词的失败次数)。
- 初始化方法(
-
定义run方法:
- 这个方法接受一个输入
inp,并尝试运行三个不同的谓词(函数):no_backslash_d(inp),no_8bit(inp),和no_dot(inp)。 - 如果任何一个谓词抛出了
AssertionError(对于no_backslash_d和no_8bit),则相应的计数器会增加。 - 对于
no_dot谓词,代码捕获了所有类型的异常(使用except:),这可能不是最佳实践,因为它会捕获所有类型的错误,而不仅仅是断言错误。但是,如果no_dot谓词抛出的是AssertionError或其他类型的错误,计数器no_dot_failures都会增加。 - 方法最后返回输入的字符串
inp,但在此代码中这个返回值似乎没有被使用。
- 这个方法接受一个输入
-
设置Fuzzer对象:
- 创建了一个
RandomFuzzer对象(该类的定义也未在代码中给出),该对象将生成随机字符串作为输入。char_start=0和char_range=256表示它将生成ASCII字符集中的所有字符,max_length=10表示生成的字符串最大长度为10。
- 创建了一个
-
运行Fuzzer和TroffRunner:
- 设置了一个试验次数
trials为100,000。 - 对于每次试验,使用
random_fuzzer生成一个随机字符串,并将其传递给troff_runner的run方法。
- 设置了一个试验次数
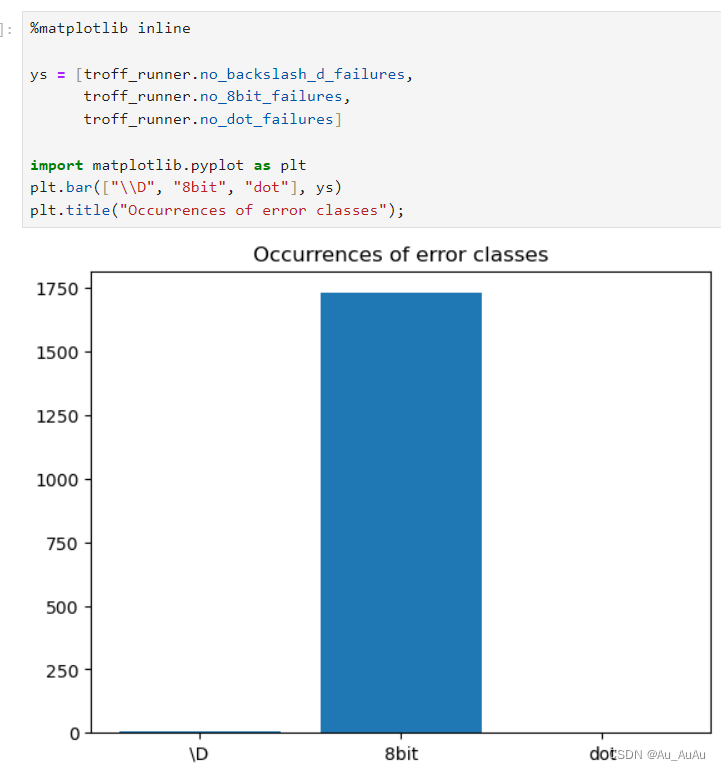
---------------------------------------------------------------------------------------------------------------------------------
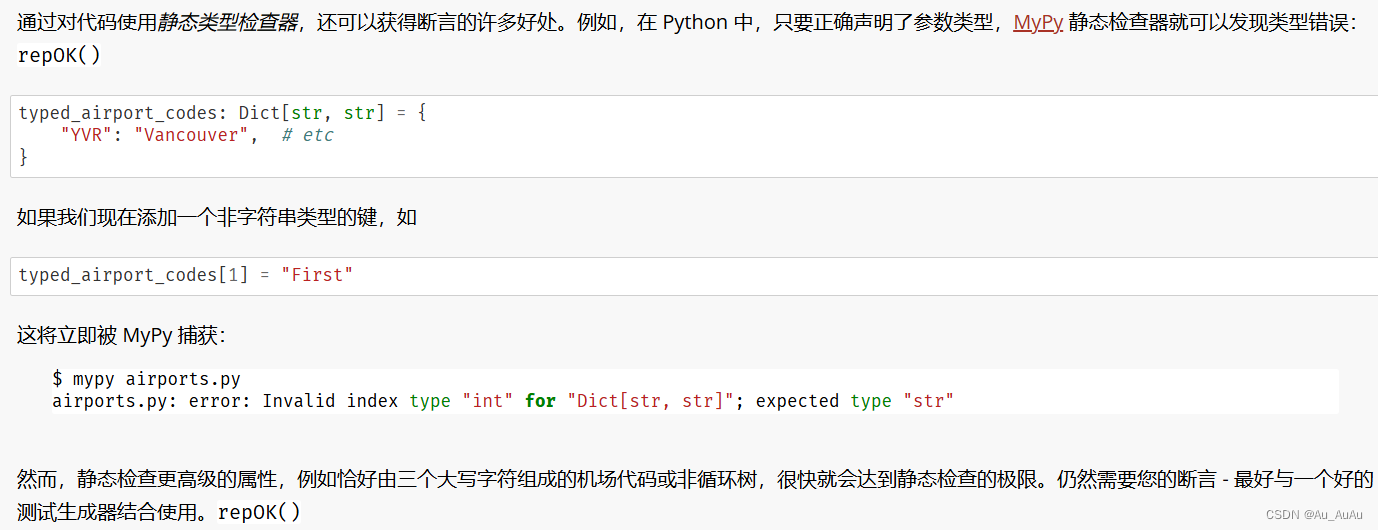
习题三、
这段代码的目的是使用BinaryProgramRunner来运行一个名为"troff"的二进制程序,并尝试使用之前配置的random_fuzzer来发现任何可能导致程序失败或崩溃的输入。让我们逐步解释代码:
-
创建BinaryProgramRunner对象:
real_troff_runner = BinaryProgramRunner("troff")这行代码创建了一个
BinaryProgramRunner对象,用于运行名为"troff"的二进制程序。假设BinaryProgramRunner是一个类,其构造函数需要一个参数(即要运行的程序的名称),并可能负责启动、执行和管理该程序的运行。 -
使用Fuzzer进行模糊测试:
for i in range(100):result, outcome = random_fuzzer.run(real_troff_runner)这里,代码使用了一个for循环来重复100次模糊测试。在每次迭代中,它调用
random_fuzzer的run方法,并将real_troff_runner作为参数传递。这意味着random_fuzzer将生成一个随机输入,并使用real_troff_runner来运行"troff"程序,并获取其输出。random_fuzzer.run(real_troff_runner)返回两个值:result(可能是模糊测试产生的输入或程序的输出)和outcome(表示测试结果的枚举或状态,如成功、失败或崩溃)。 -
检查结果:
if outcome == Runner.FAIL:print(result)如果
outcome等于Runner.FAIL(这里假设Runner是一个包含不同测试结果的枚举或类,并且FAIL是其一个成员),则代码将打印出result(可能是导致程序失败的输入)。 -
注意:
像大多数其他开源代码一样,troff程序已经通过这种方式被模糊测试过,并且所有发现的错误都已经被修复。
总之,这段代码的目的是使用模糊测试来尝试找出troff程序中的新错误,但由于troff已经被广泛测试并修复了大部分错误,所以找到新错误的概率很低。















 166
166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









