







1.前言
时间如白驹过隙,转眼之间就到了2016年的年末,近来回想自己这一年的收获,感慨颇多。翻看之前的学习,觉得自己依旧存在着很多的问题,上学期大四的最后日子,做完毕设悠哉悠哉了很久,暑假回家找了个兼职,其中的经历个中滋味只有自己知道。下学期在实验室,刚开始的时候一度迷茫和抱怨过,后来渐渐的也想明白了,既然事实依然如此,不如就躺下来享受吧。最近想着把以前做的工作好好的总结一下,做一个回顾。
2 线性回归
线性回归问题是机器学习中常见的基本问题之一,问题模型如下:给定一系列的数据样例和标记,用一个线性的方程来表示这些数据。简单点也就是给出点,求拟合曲线。在Andrew Ng的课程里,给出一系列房屋的面积和售价,求二者之间的线性关系。
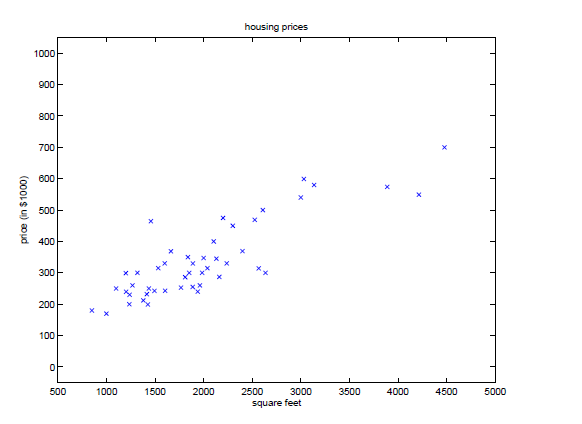
这是一个二维的问题,用一条直线就可以进行拟合。对于多维的情况,用表示多维的数据,用Y表示数据的标记,对于线性回归,是要找到这样的一个
使得:
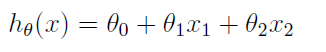
成立,如果令=1,则有下面的式子成立:
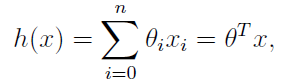
有了线性回归的模型,定义下面的代价函数:
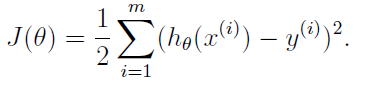
现在要求取使得代价函数J最小,求J最小的方法可以采用梯度下降算法和最小二乘法来实现。
3 梯度下降算法
梯度下降算法是典型的利用搜索算法来求取最优化的问题,每次求取函数的负梯度方向,沿着函数的负梯度方向进行搜索,知道找到函数的最有解为止。对J进行求导,过程如下:
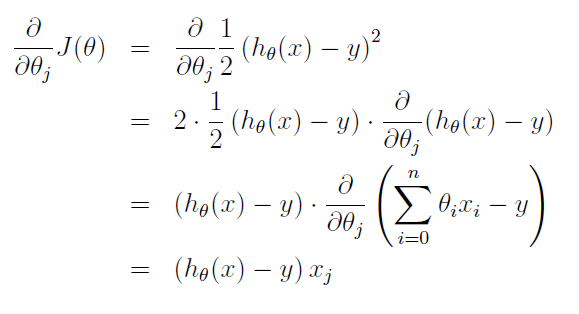
所以对于,可以进行如下迭代:
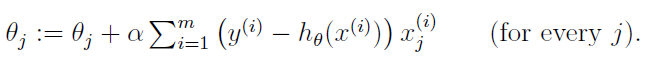
可以看出,梯度下降算法在每次对进行迭代的时候都要计算所有样本的一个梯度值,在样本数字比较小的时候,可以在较短的时间内找到全局的最优解,当样本的个数比较多的时候,这样的方法是很费时间的。这种方法叫做批梯度下降算法,与批梯度下降算法对应的是随机梯度下降算法。
4 随机梯度下降算法
随机梯度下降算法每次在对进行迭代的时候选择一个样本,利用一个样本的梯度值对
来进行该进,所以在时间性能上优于批梯度下降算法。批梯度下降方法在每次迭代的时候总是可以向着最优化的方向进行,但是批梯度下降算法每次并不一定是向着最优化的方向进行,但是整体的效果是向着最优化的方向。
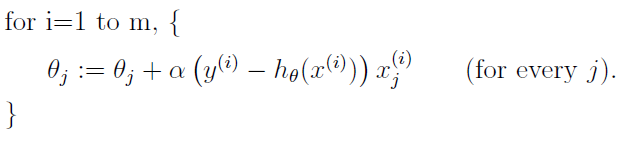
5.最小二乘法
用最小二乘法来求取最优解,上述的问题可以简化为下述方程问题
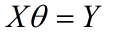
其中X表示样本,Y表示标记,为求取的变量,现在方程组中方程的个数多于变量的个数,所以只能求取最优解,由线性代数的内容可以知道该方程的最有解可以通过 在方程两边同时乘以X的转置来实现。所以:
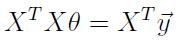
最终求得的
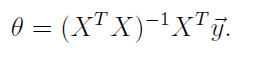
6 实验实现
实验采取的数据的散点图如下:
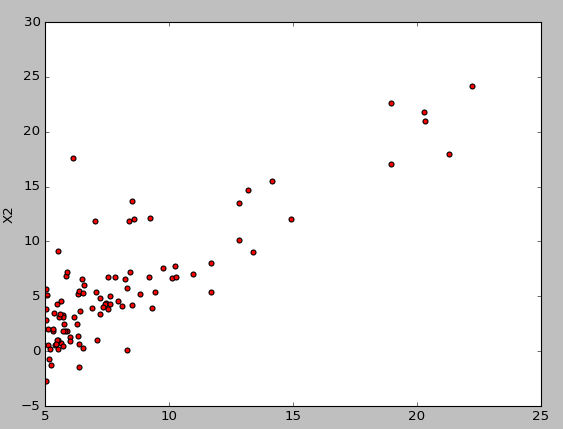
最终求得的结果如下所示:
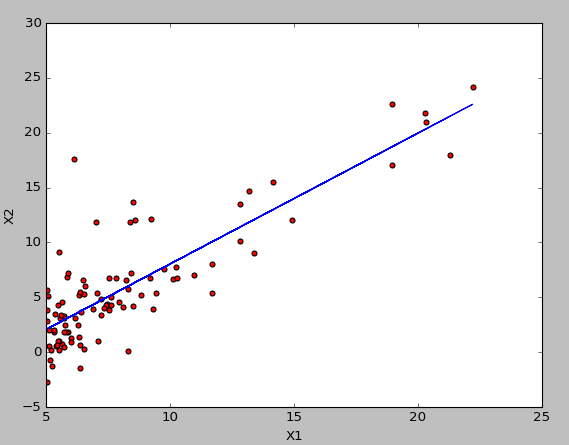
所有的代码如下:
#简单线性回归
import numpy as np
import matplotlib.pyplot as plt
#导入数据
def ReadFile(filename):
data=[]
label=[]
lines=open(filename,encoding='utf-8').readlines()
for i in range(len(lines)):
xy=lines[i].strip().split(',')
data.append([1,float(xy[0])])
label.append(float(xy[1]))
return data,label
#定义代价函数
def costfunction(X,Y,thea):
m=np.shape(Y)[0]
return sum((X.dot(thea)-Y)**2)/(2*m)
#批梯度下降函数
def batchgrad(data,label):
X = np.array(data)
m, n = np.shape(X)
Y = np.array(label).reshape(m,1)
alpha=0.01 #定义步长
iterations = 1500; #定义迭代次数
thea=np.ones((2,1)) #定义初始的点
for k in range(iterations):
H = X.dot(thea)
T = np.zeros((2, 1))
for i in range(m):
T=T+((H[i]-Y[i])*X[i]).reshape(2,1)
thea = thea - (alpha * T)/m
return thea
#随机梯度下降函数
def Randomgrad(data,label):
X = np.array(data)
m, n = np.shape(X)
Y = np.array(label).reshape(m,1)
alpha=0.01 #定义步长
thea=np.ones((2,1)) #定义初始的点
for i in range(m):
thea=thea+alpha*((Y[i]-X[i].dot(thea))*X[i]).reshape(2,1)
return thea
#最小二乘法
def Leastsquares(data,label):
X = np.array(data)
m, n = np.shape(X)
Y = np.array(label).reshape(m, 1)
return np.linalg.inv(X.T.dot(X)).dot(X.T).dot(Y)
if __name__=="__main__":
data,label=ReadFile('ex1data1.txt')
X = np.array(data)
#thea=batchgrad(data,label)
#thea=Randomgrad(data,label)
thea=Leastsquares(data,label)
print(thea)
Y=X.dot(thea)
fig=plt.figure()
ax=fig.add_subplot(111)
x=[]
y1=[]
y2=[]
for i in range(len(data)):
x.append(data[i][1])
y1.append(label[i])
y2.append(Y[i])
ax.scatter(x,y1,c='red')
ax.plot(x,y2)
plt.xlim(5,25)
plt.xlabel("X1")
plt.ylabel("X2")
plt.show()















 3406
3406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









