






目录
回归问题概述
根据训练数据是否拥有 标记信息,学习任务可大致划分为 有监督学习 和 无监督学习。分类和回归是前者的代表,聚类是后者的代表。
回归任务时,需要标签(例如年龄、工资)和数据
回归方程:Y=X1*θ1 + X2 * θ2,由于X1 和 X2 已知,故需求出θ1和θ2
X1表示工资,X2表示年龄,Y表示可贷款的额度
由于Y=X1*θ1 + X2 * θ2 是个线性方程无法满足所有的数据, 只能尽可能多的去拟合当前的数据
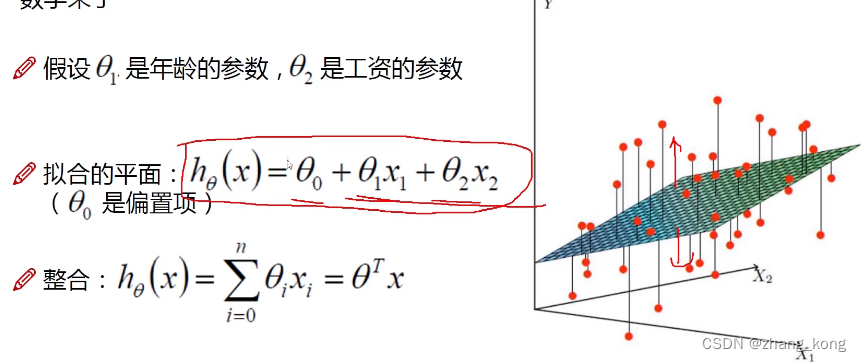 偏置项是对拟合的平面进行微调,使得更符合大多数数据。
偏置项是对拟合的平面进行微调,使得更符合大多数数据。
在给出来的数据中,每一行代表一个样本,每一个列代表一个特征(标签),由于对数据所有的操作都是对矩阵进行一系列的变换。但是因为偏置项加入,无法把回归方程转换为矩阵的表达形式去计算。
| X0 | X1工资 | X2年龄 | Y额度 |
| 1 | 4000 | 25 | 20000 |
| 1 | 8000 | 30 | 70000 |
| 1 | 5000 | 28 | 35000 |
| 1 | 7500 | 33 | 50000 |
| 1 | 12000 | 40 | 85000 |
需要添加X0一列,是数据可以转为矩阵的形式进行计算

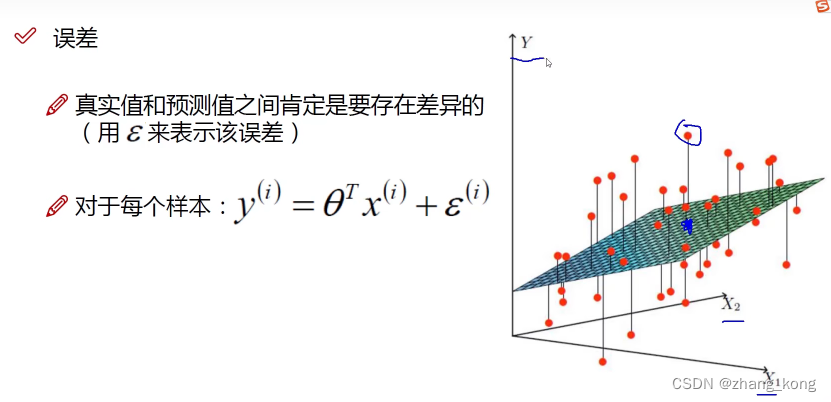
误差项定义
红色点代表真实数据,蓝色点代表了预测值的数据,两者之间的误差通过ε表示,机器学习通过 数据 + loss function 完成一个目标,给出需要的参数
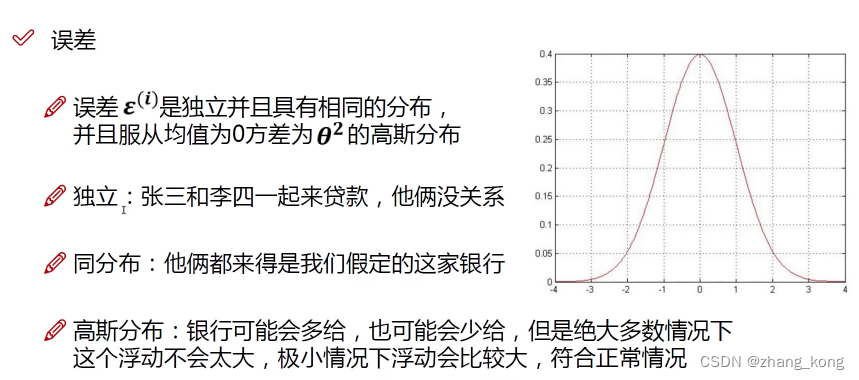
独立同分布的意义
由于Y(i) 、X(i)、 ε(i)都已知道,需要求出θ(i)

θ和X(i) 结合之后,成为真实值Y(i)的可能性越大越好,要是可能性越大越好需要使用到似然函数,似然函数中的累乘符号表示,通过大量的数据去找到一个适合的参数。独立同分布前提下,联合概率密度等于边缘概率密度的乘积,故可以用累乘。
似然函数的作用

由于所要求的是极值点,而不是极值,故可以将乘法转换为加法
参数求解

由于需要A-B的结果越大越好,因为A为常数项,而B恒正,故当B最小时符合要求。
去掉常数1/δ^2,保留1/2因为后面需要用到。

实对称矩阵,由于A的转置等于A 故A的平方等于A的转置乘以A 。
要求极小值点,对J(θ)求θ的偏导,令导数等于0,两边再用逆矩阵去抵消。在上图的求解过程中并没有体现出学习过程,而且也会出现找不到逆矩阵来抵消的情况。
梯度下降通俗解释

为啥叫梯度下降呢?① 下山要越快越好 ② 沿着梯度的反方向才是下山方向。
每走一步求一个梯度,步子小点走,直到损失值不会在下降。
参数更新方法

θ0和θ1都会对结果产生影响,对θ0 和 θ1 分开来处理,因为X0 和 X1是相互独立的,对θ0 和 θ1 分别求偏导找它们的方向(斜率)。
优化参数设置
在数学中来描述下山任务
目标函数中乘以1/m是对m个样本的loss函数的值之和进行求平均——批量梯度下降,加了平方是当loss函数做的不好时,放大该结果,例如loss函数得出结果是2,平方之后就是4,可以看出做的有多不好了。

对J(θ)中某个θj进行求偏导,由于梯度下降,需要反方向,为所求偏导添加负号,再加上当前位置量可以得到新的位置。
表示第i个样本的第j列,是一个数。

小批量梯度下降法中,1/10表示10个样本算出的loss函数值之和进行平均,α表示学习率(步长)
批量梯度下降更新一次参数就需要算m次,当m很大时就很吃力。而随机梯度下降很难控制方向,实际使用的是小批量梯度下降法,每次更新从样本从选择一小部分的数据来算。batch选择比较大,则当前结果会越精确,但是速度也会有所慢,而batch越小则相反。

机器学习问题没有直接求解,都是用优化算法进行求解,梯度下降是最常用的。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









