







从图像处理到数据分析。。。硬接活啊,就当做对自己的一种历练了。
需求介绍:
读入的数据表格中有很多缺失值,由于数据量很大,不需要对缺失值进行中值填充、均值填充,直接删除即可。每一条数据都有很多特征。。。
像这样:x1,x2,x3,x4,nan,x6,x7,y
x表示特征值,y表示该条数据的标签,nan表示空值
废话不多说,直接上代码:
导包、构建虚拟的数据集
import numpy as np
import pandas as pd
n = 7
DataList = [[str(n-i) for j in range(n-i)]+[np.nan for j in range(i)] for i in range(n)]
df = pd.DataFrame(DataList)
df 如下:
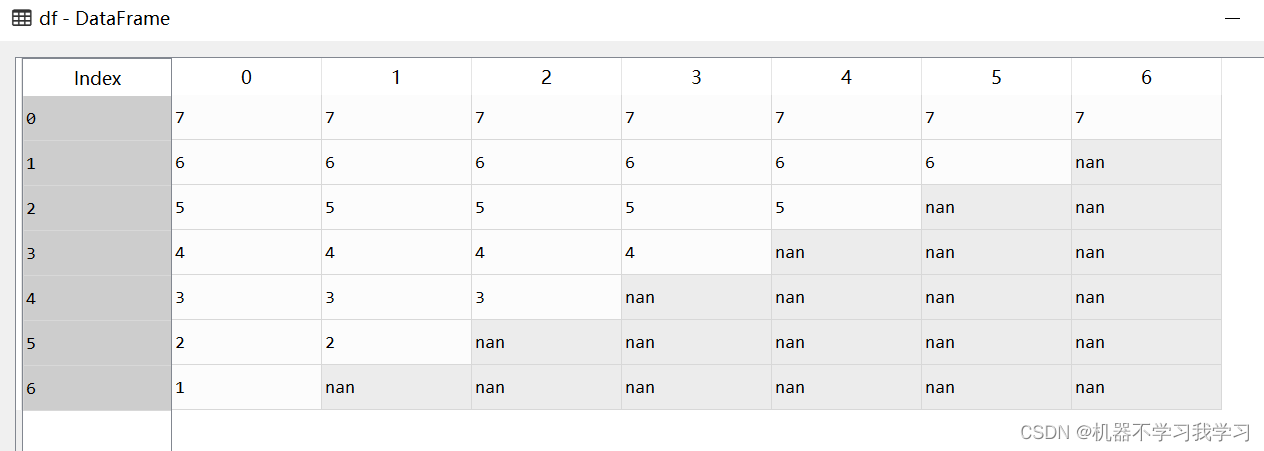
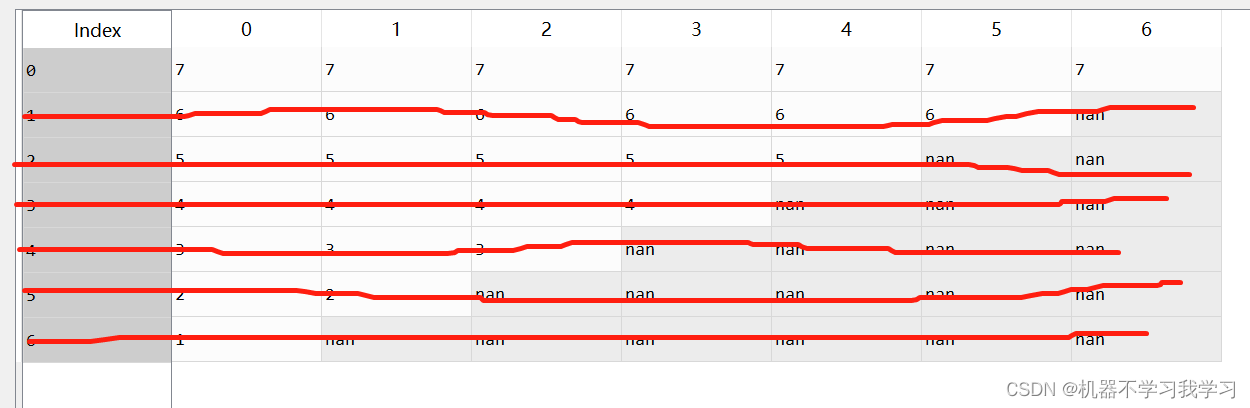
1.默认参数
df.dropna()
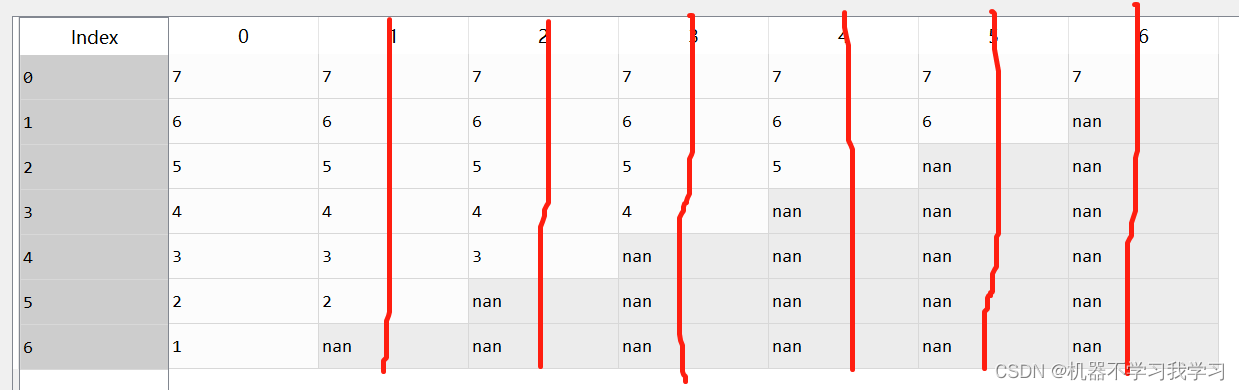
2.axis
df.dropna(axis=1)
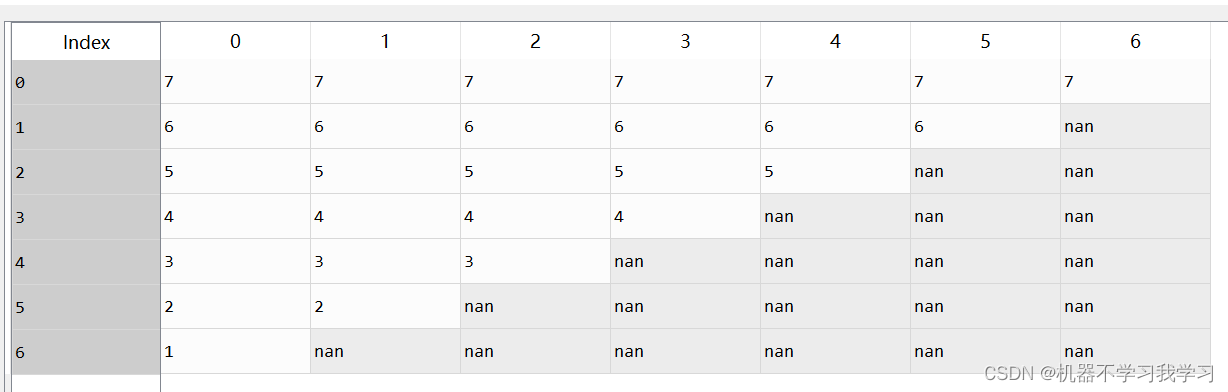
3.how
df.dropna(how="all") # 删除全部为空值的行
本立中没有全部为空值的行,数据不动
df.dropna(how="any") # 删除该行只要有一个以上的空值
4.thresh
根据设定的阈值进行删除。
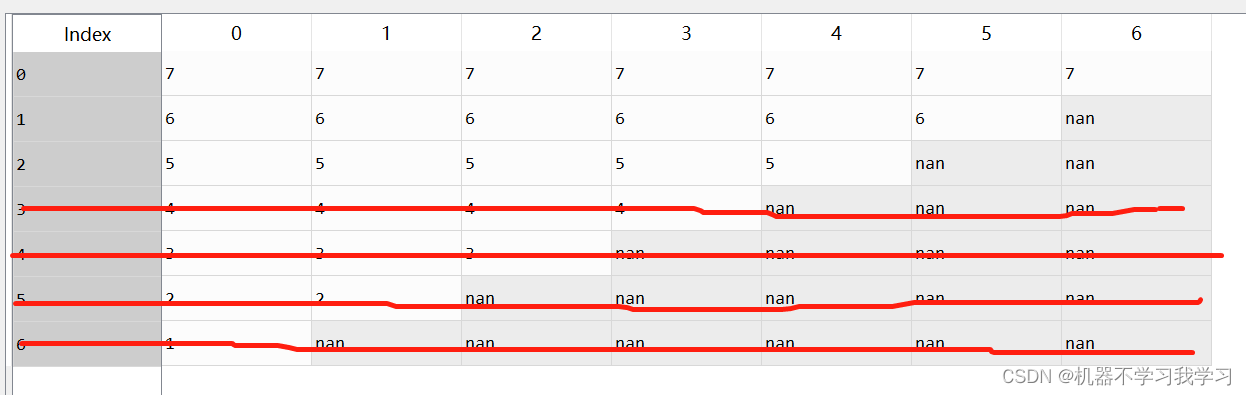
df.dropna(thresh=3) # 删除空值数量大于等于3的行
5.subset
根据设定的子集进行删除。
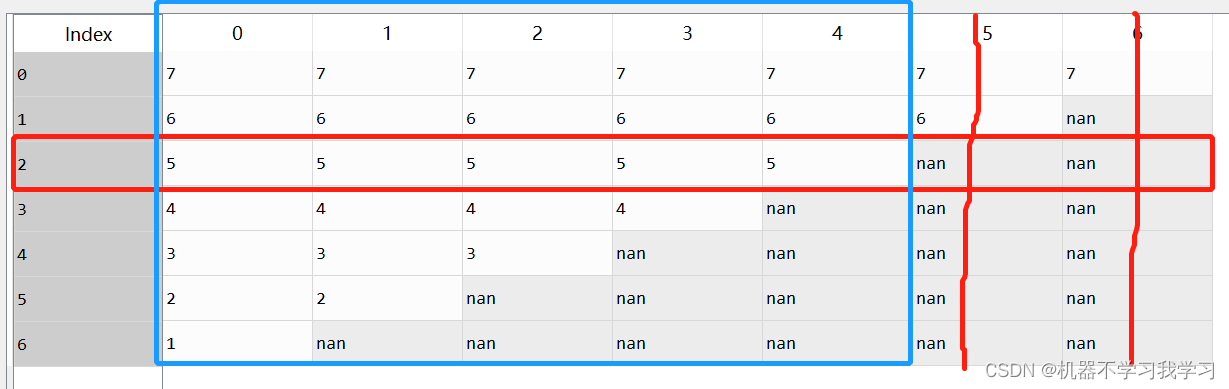
df.dropna(subset=[2],axis=1) # 删除索引为2的行中,存在空值的列
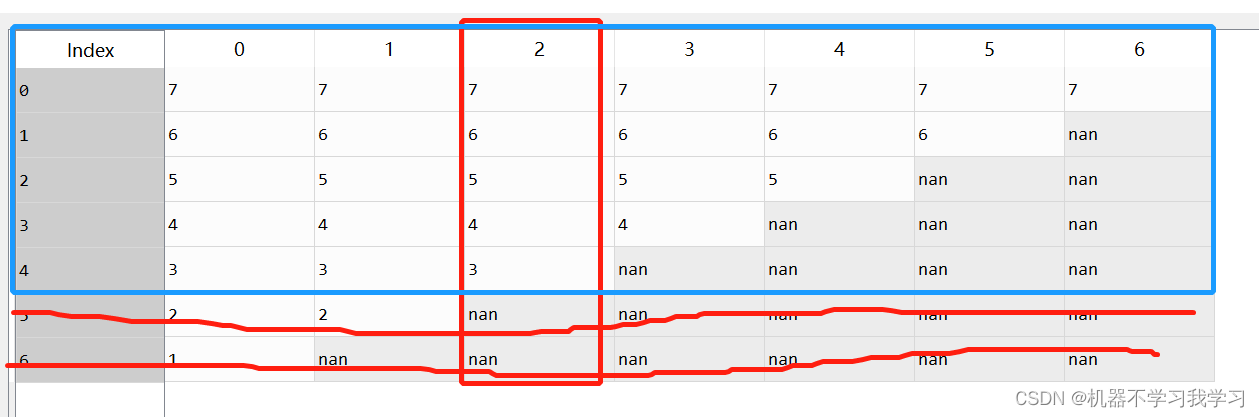
df.dropna(subset=[2],axis=0) # 删除索引为2的列中,存在空值的行

















 1395
1395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











