







参考学习资料:https://blog.csdn.net/qq_28258885/article/details/116192244
视频编码基础
文章目录
图像
像素
-
在消费级别,每个像素使用8bit来表示–0~255,其中,0:黑色;255:白色
-
在工业级别,使用10bit来表达一个像素–0~1023,精度高,颜色细腻,细节更丰富
-
事实是:几乎没有硬件芯片、移动设备、软件支持10bit。
颜色深度
存储颜色的强度,需要占用一定大小的数据空间,这个大小被称为颜色深度。假如每个颜色的强度占用 8 bit(取值范围为 0 到 255,即 2 8 2^8 28),那么颜色深度就是 24(8*3)bit(因为RGB三个颜色),我们还可以推导出我们可以使用 2 24 2^{24} 224种不同的颜色。
分辨率
即一个平面内像素的数量。通常表示成宽*高
视频行业常见的分辨率,我们比较熟悉的360P (640x360)、720P (1280x720)、1080P (1920x1080)、4K (3840x2160)、8K (7680x4320)
我发现宽都是高的1.77777倍
视频
帧率
帧率(FRames rate)= 帧数(Frames)/时间(Time)
若单位时间为秒,则等同于 FPS (每秒帧数 Frames Per Second)。
码率、带宽、体积
码率:每秒钟的数据量
比特率:以bit表示数据量的码率,bps(bits per second)
比特率 = 宽 * 高 * 颜色深度 * 帧每秒
带宽:有时指带宽能力,有时指使用了多少带宽,也即达到了多少码率,后一种情况带宽和码率同义
体积和容量:体积一般指文件大小(即总的数据量,区别于码率表示每秒数据量)。容量一般指能力
总结:
- 码率和带宽针对传输,体积和容量针对存储。
- 对于视频编码,节省码率/带宽/体积,意思差不多
为什么要压缩视频
- 以一集FHD《生活大爆炸》为例:
1080p(1920x1080) YUV 4:2:0的图像格式,每秒拍摄24帧,视频长度为22分钟
-
1 pixel => YUV 4:2:0 @1.5 bytes (1 + ¼ + ¼ ) 一个像素
-
1 pictrue => 1920x1080x1.5 bytes = 3MB 一个图片
-
1 second @ 24fps => 24x3M = 72MB => 576M bps
传输带宽576M bps 不压缩,不可能在线实时收看
所以要压缩,消除冗余
为此,我们可以
利用视觉特性:和区分颜色相比,我们区分亮度要更加敏锐。
时间上的重复:一段视频包含很多只有一点小小改变的图像。
图像内的重复:每一帧也包含很多颜色相同或相似的区域。
我们的眼睛对亮度比对颜色更敏感
帧类型
在介绍去除冗余的方法前,需要了解帧类型。
I帧(帧内,关键帧)
P帧(预测)
P 帧利用了一个事实:当前的画面几乎总能使用之前的一帧进行渲染。
实际情况中,一般使用一个I帧多个P帧。但是P帧不能太多,因为离上一个I帧越远,预测难度就越大,丢失的信息也就越多。
B帧(双向预测)
引用前面和后面的帧去做更好的压缩

消除冗余的方法
时间冗余(帧间预测)
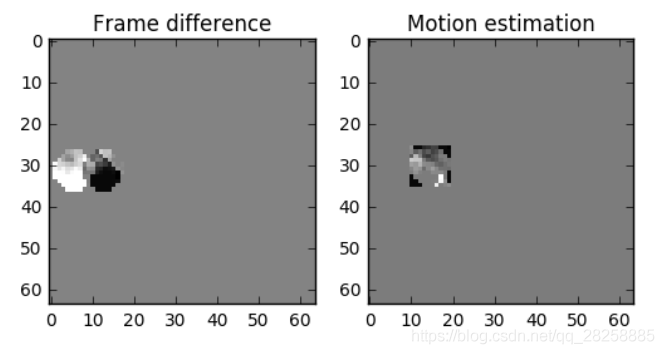
我们可以做个减法,我们简单地用 0 号帧减去 1 号帧,得到残差,这样我们就只需要对残差进行编码。

但我们有一个更好的方法来节省数据量。
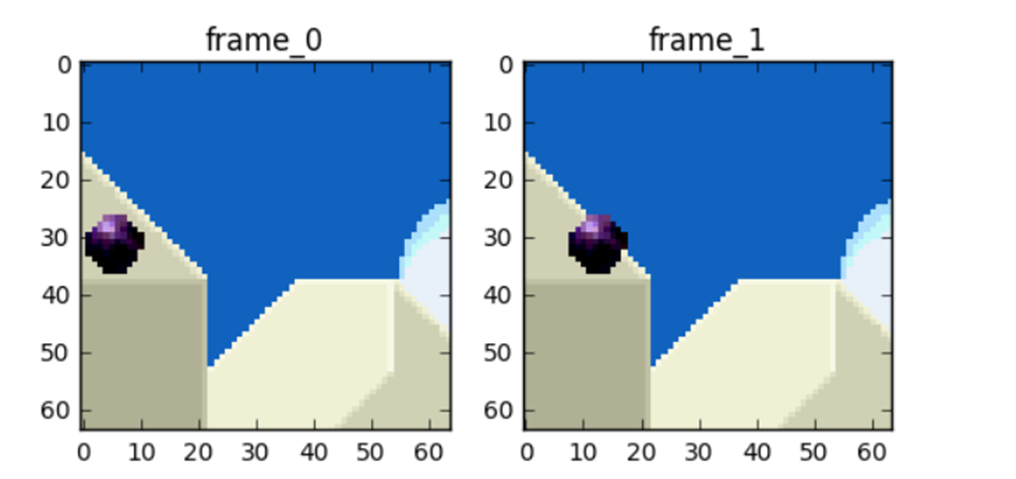
首先,我们将0 号帧 视为一个个分块的集合,然后我们将尝试将 帧 1 和 帧 0 上的块相匹配。我们可以将这看作是运动预测。
运动补偿是一种描述相邻帧(相邻在这里表示在编码关系上相邻,在播放顺序上两帧未必相邻)差别的方法
具体来说是描述前面一帧(相邻在这里表示在编码关系上的前面,在播放顺序上未必在当前帧前面)的每个小块怎样移动到当前帧中的某个位置去。
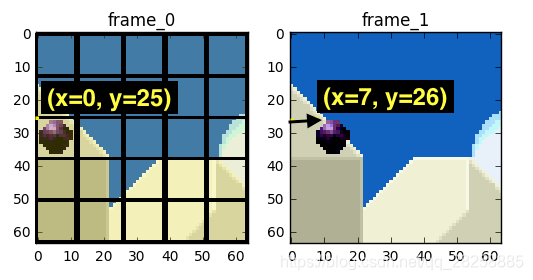
我们预计那个球会从 x=0, y=25 移动到 x=6, y=26,x 和 y 的值就是运动向量。进一步节省数据量的方法是,只编码这两者运动向量的差。所以,最终运动向量就是 x=6 (6-0), y=1 (26-25)。
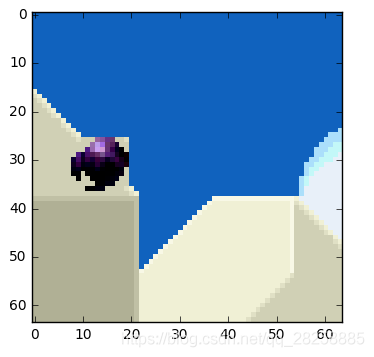
实际情况下,这个球会被切成 n 个分区,但处理过程是相同的。
帧上的物体以三维方式移动,当球移动到背景时会变小。当我们尝试寻找匹配的块,找不到完美匹配的块是正常的。这是一张运动预测与实际值相叠加的图片。
但我们能看到当我们使用运动预测时,编码的数据量少于使用简单的残差帧技术
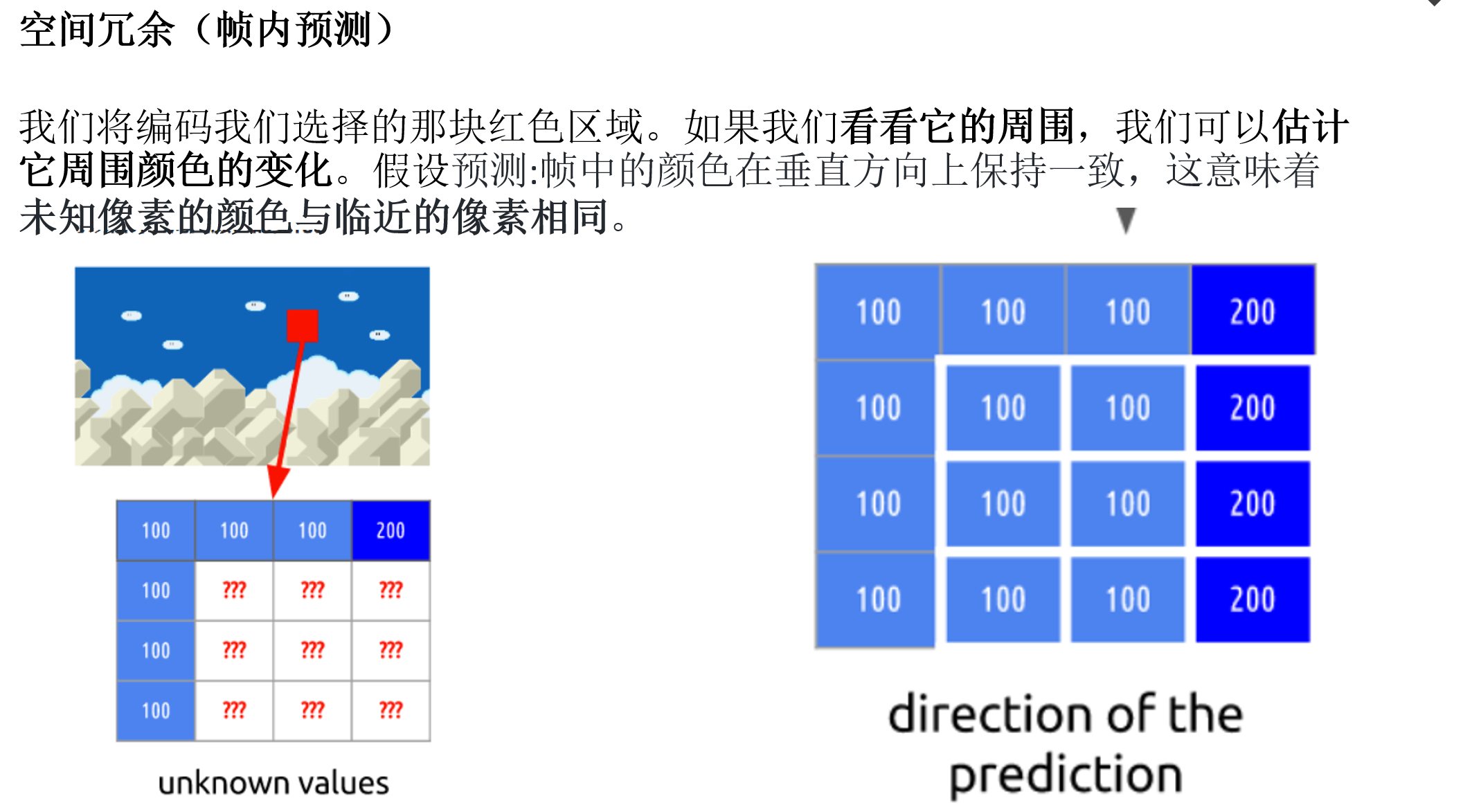
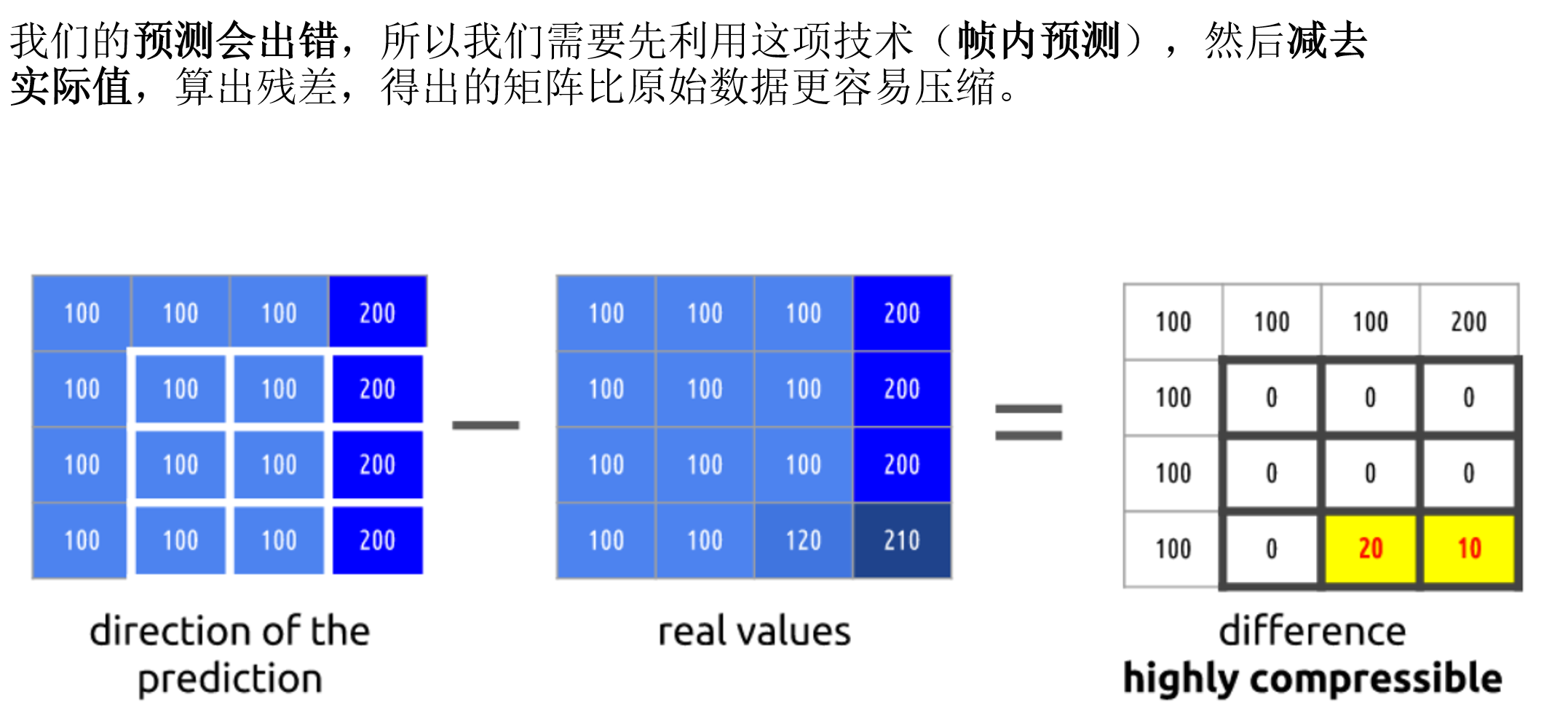
空间冗余(帧内预测)
如果我们分析一个视频里的每一帧,我们会看到有许多区域是相互关联的
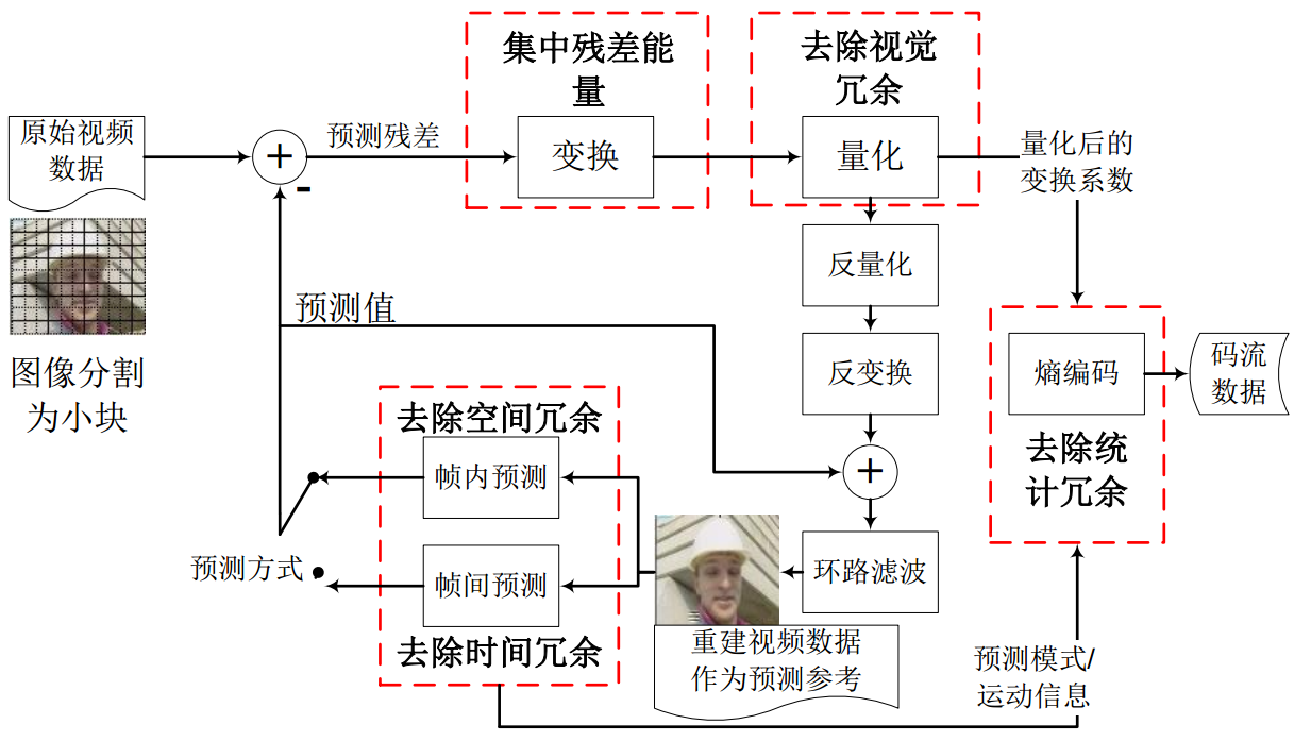
视频编码器关键技术
是什么?就是用于压缩或解压数字视频的软件或硬件
1.分区

有许多原因,比如,当我们分割图片时,我们可以更精确的处理预测,在微小移动的部分使用较小的分区,而在静态背景上使用较大的分区。
通常,编解码器将这些分区组织成切片(slices )或条带(tiles),宏(或编码树单元)和许多子分区。
这些分区的最大大小有所不同,HEVC 设置成 64x64,而 AVC 使用 16x16,但子分区可以达到 4x4 的大小。
2.预测
一旦我们有了分区,就可以在它们之上做出预测。
- 对于帧间预测,我们需要发送运动向量和残差
- 对于帧内预测,我们需要发送预测方向和残差
3.转换
4.量化
有损的
5.熵编码
在我们量化数据(图像块/切片/帧)之后,我们仍然可以以无损的方式来压缩它。有许多方法(算法)可用来压缩数据。
熵编码技术是视频编码技术中基础性关键技术,在经典编码框架中处于系统末端,负责对编码过程中的变换系数、运动矢量等信息进行熵编码,并完成最终编码码流的组织。
熵编码目标是利用信息熵原理进行数据的最终压缩,去除信源符号在信息表达上的冗余。
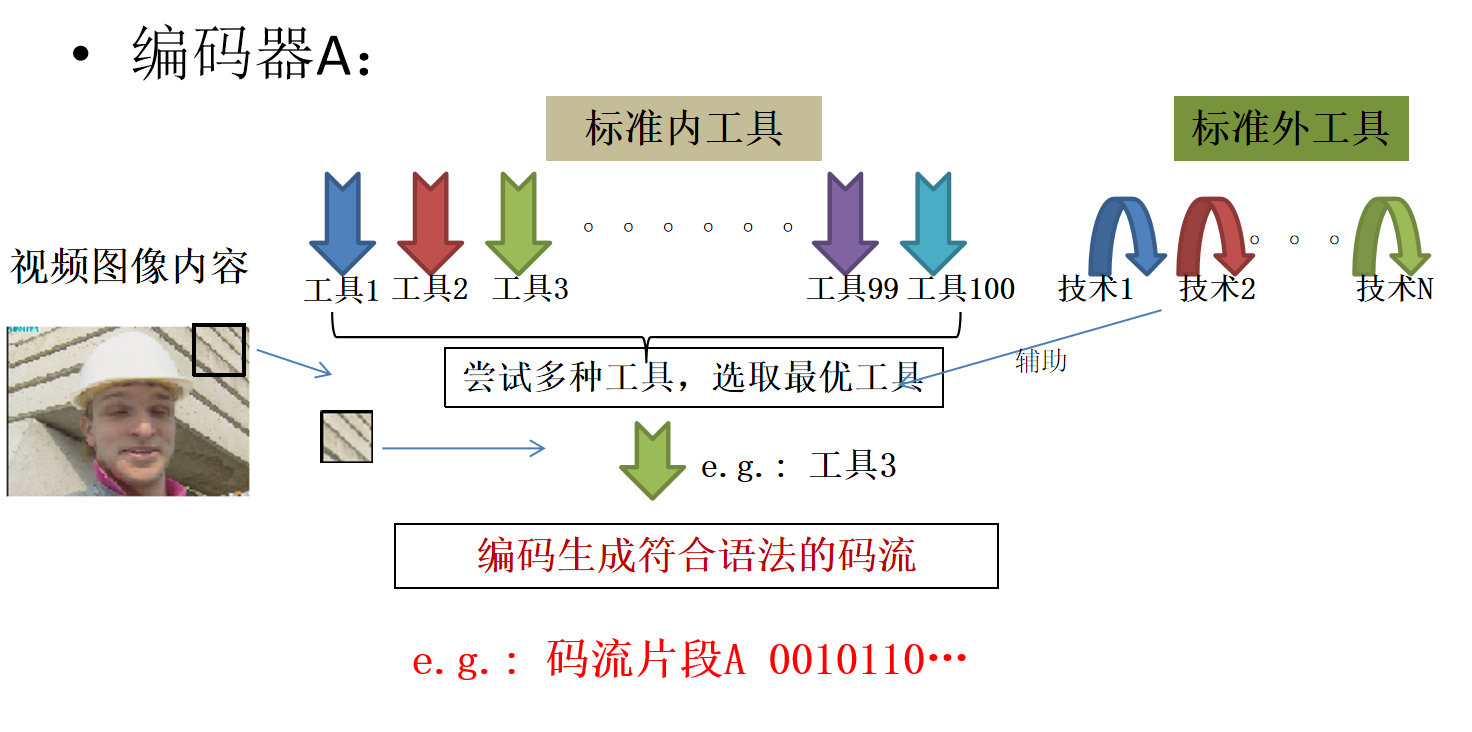
编码器与解码器
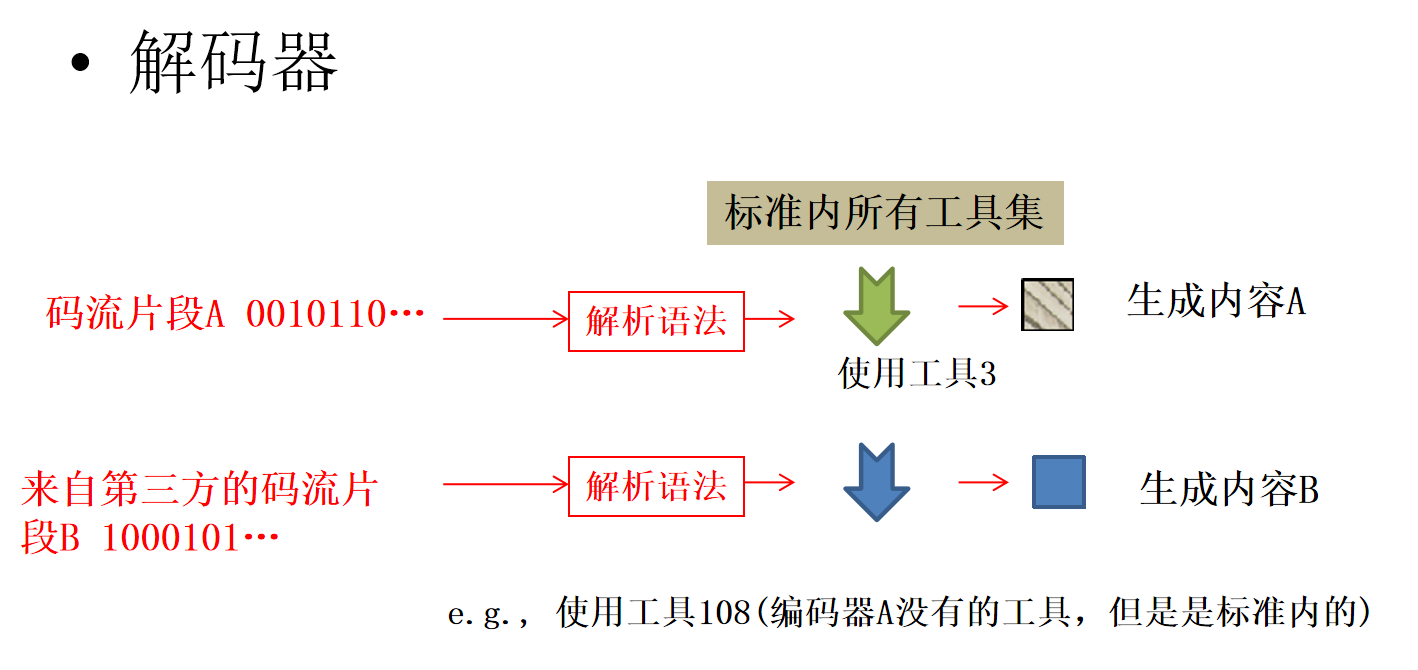
小结
编码器:时间复杂度比解码器高很多,编码器对每一块图像内容要尝试很多种工具,挑选更好的工具
解码器:根据标准语法语义解析码流,生成一块内容只需要执行指定的工具,没有挑选过程,不用执行多种工具
解码器需要支持标准规定的所有工具;而编码器不必
那编码和解码为什么能匹配工作?
因为编码和解码用同一种算法
那解码器怎么知道编码器用了什么算法?
有"标准"规定,在码流里面比如说开头有110110,解码器解析到这一串就知道用的是什么算法
视频编码标准
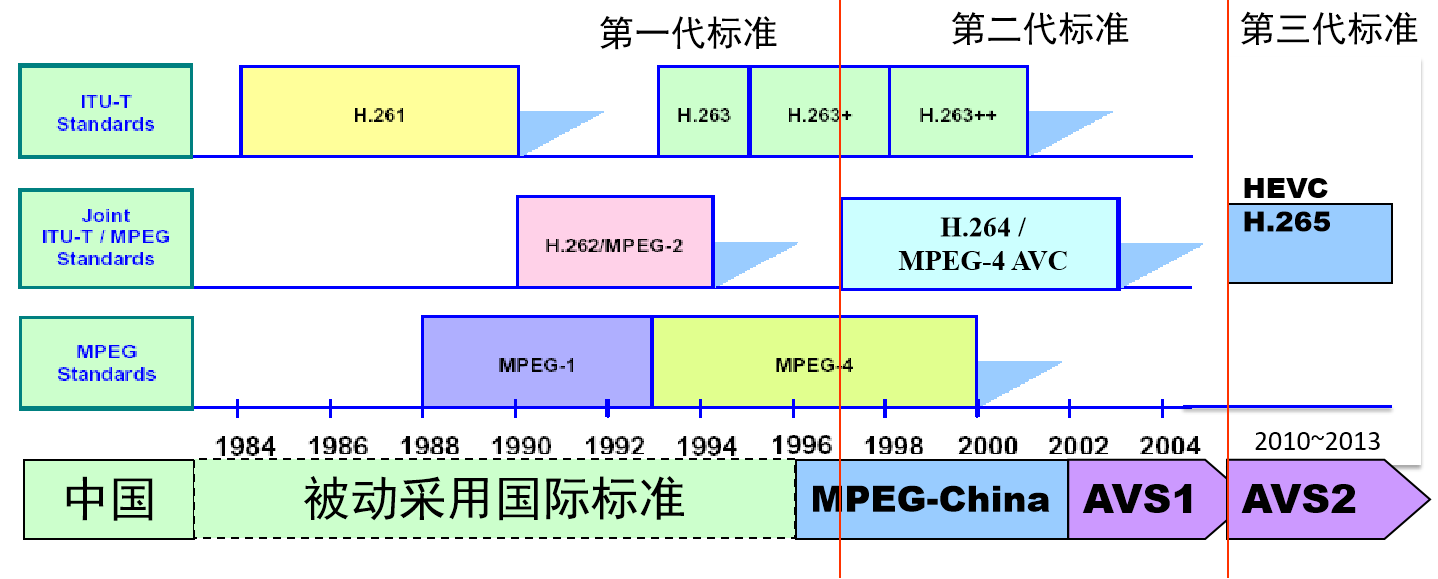
ITU-T和MPEG,后来他们一起合作,所以命名的时候就包含两个组织;例如H.264/MPEG-4 AVC,H.264代表是ITU-T,MPEG-4 AVC代表MPEG
YUV模型
有一种模型将亮度(LUMA)和色度(cb,cr)分离开,它被称为 YUV模型。
我们的眼睛对亮度比对颜色更敏感
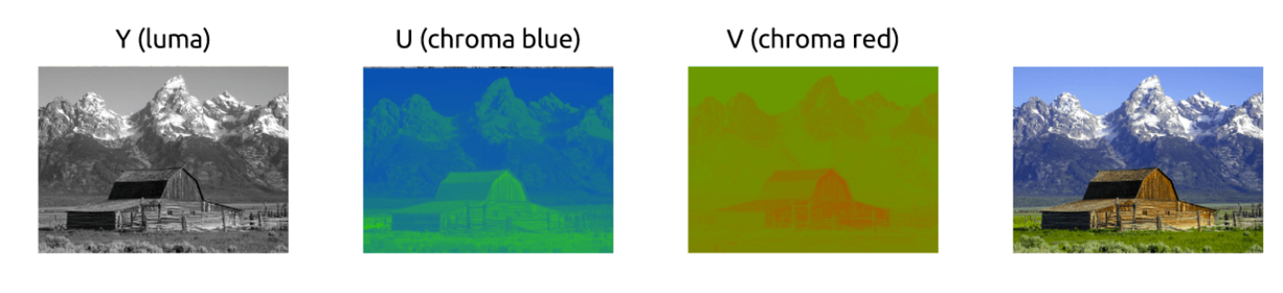
色度子采样
一旦我们能从图像中分离出亮度和色度,我们就可以利用人类视觉系统对亮度比色度更敏感的特点,选择性地剔除信息。色度子采样是一种编码图像时,使色度分辨率低于亮度的技术。
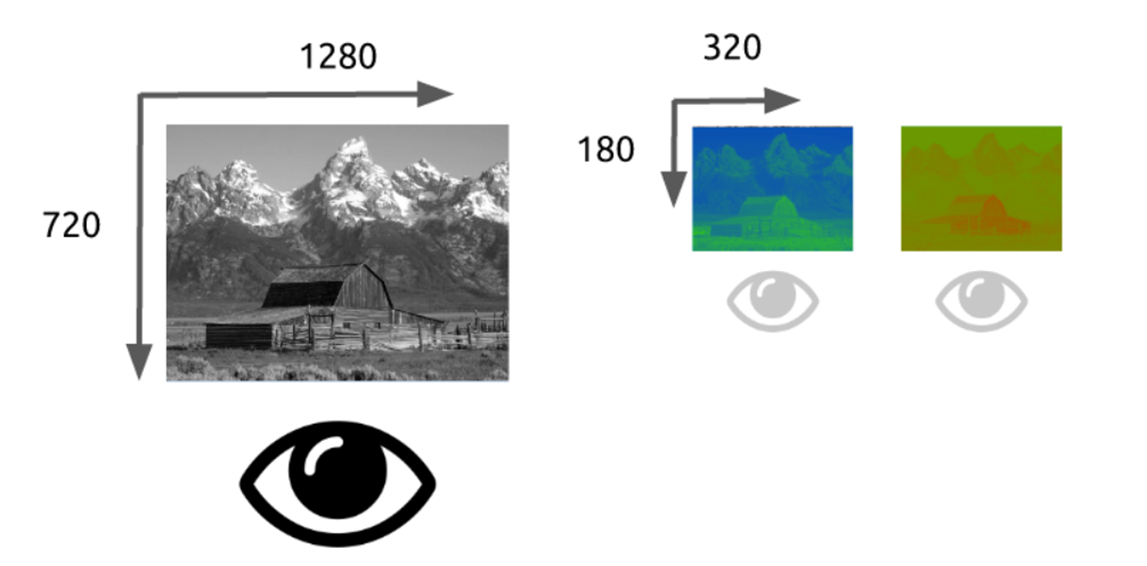
四个亮度像素共享一个色度像素
现代编解码器中使用的常用方案是: 4:4:4 (没有子采样), 4:2:2, 4:2:0,
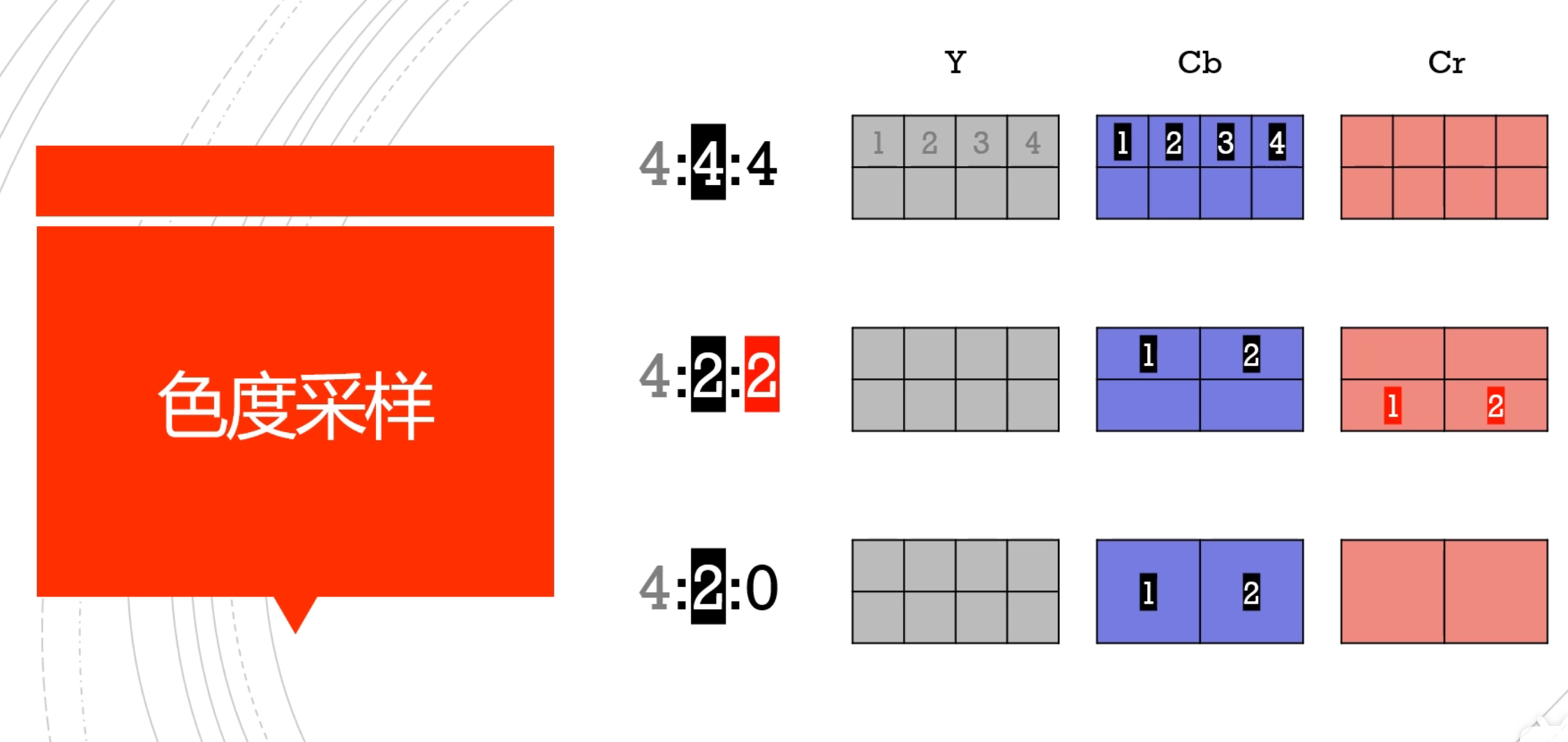
第二个参数代表第一行分成几块
第三个参数代表第二行分成几块
如果我们使用 YCbCr 4:2:0 我们能减少一半的大小















 3476
3476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









