






1、Detection-aided liver lesion segmentation using deep learning
2、Automatic Liver and Tumor Segmentation of CT and MRI Volumes Using Cascaded Fully Convolutional Neural Networks
https://github.com/IBBM/Cascaded-FCN
一、Method
- 第一步:数据预处理和神经网络分割的准备。
- 原始切片的Hounsfield单位范围为-100-400hu,忽略了不感兴趣的器官和组织。
- 进一步实验直方图均衡化,增强异常组织的对比度。

- 数据增强:弹性编写那个、平移旋转、带有当前切片标准差的高斯噪声。
- 第二步:两个级联的完全卷积神经网络首先第一个U-Net分割肝脏,然后第二个U-Net从第一步分割的肝脏感兴趣区域(ROI)中学习分割病变。
-
类平衡对于医学图像分割很重要。(因为来自自然图像的预先训练的网络不能被正确使用,而且感兴趣的类在数据集中出现得更少。)
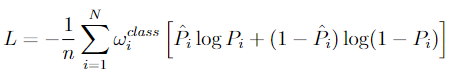
-
将分类网络(如AlexNet[14])的最后一个完全连接的层替换为完全卷积层,以实现密集的像素级预测。
-
级联方法背后的动机是,已经证明,U-Net和其他形式的CNN学习所提供数据的分层表示。卷积滤波器的堆叠层以数据驱动的方式针对所需分类进行定制,而不是设计用于分离不同组织类型的手工特征。
-
使用在其他任务上预先训练的神经网络作为预训练模型,可以避免重复训练识别基本结构。
- 第三步中,后处理,计算出的CFCN概率将使用密集的3D条件随机场进行细化,以产生最终的分割结果。
2、质量度量
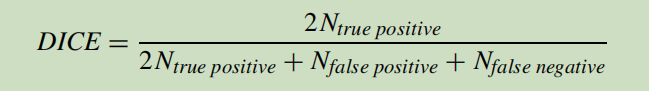
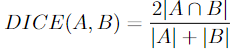
A为前景对象、B为预测对象。A交B表示的就是预测正确的部分。
3、实验结果
3DIRCADb数据集提供了高种类、高复杂性的肝脏和病变数据,并可公开获得。包括20个静脉期增强的CT volumes。
数据集地址
0.19ms and 0.59ms per slice
3、AUTOMATIC LIVER LESION SEGMENTATION USING A DEEP CONVOLUTIONAL NEURAL NETWORK METHOD
rank first in LiTS
(Liver Tumor Segmentation Challenge)
一、Method
预处理:我们将所有扫描的图像强度值截断到[−200,200]Hu,忽略不相关的图像细节。
训练了两个DCNN模型以减少总体计算时间。第一个模型的目的是对肝脏进行快速但粗略的分割,第二个模型的重点是肝脏区域,以便对肝脏和肝脏病变进行更详细的分割。为了训练第一个模型,所有CT扫描都被重新采样到1×1×2.5 mm3的固定粗略分辨率。第二个模型使用原始图像分辨率进行训练,以避免图像重新采样时可能出现的模糊,并避免遗漏小病灶。
FCN允许在一次扫描中完成整个(2D)图像的分割
U-Net体系结构在编码部分和解码部分之间引入了长距离连接,因此编码部分的高分辨率特征可以用作解码部分中卷积层的额外输入
二、输入输出
模型输入:一堆相邻轴向切片(5个)
模型输出:与堆中心切片相对应的分割映射
4、U-Net: Convolutional Networks for Biomedical Image Segmentation
摘要:提出了一种网络和训练策略,该策略依赖于强大的数据增强功能,以更有效地使用可用的注释样本。该体系结构包括一条用于捕获上下文的收缩路径 和 一条能够精确定位的对称扩展路径。这种网络可以从很少的图像中进行端到端的训练,对于512x512图像的分割耗时小于一秒钟。
架构:

- 在上采样部分,有着大量的特征通道,它允许网络将上下文信息传播到更高的分辨率层。(我的理解:更多的特征通道,使用了更多数量的卷积核,会保留更完整的信息)所以收缩路径(左)与扩展路径(右)基本对称
- 该网络没有任何完全连接的层,只使用每个卷积的有效部分(没有padding的卷积),即segmentation map只包含像素点,对于这些像素点,输入图像中有完整的上下文。该策略允许通过overlap-tile策略对任意大的图像进行无缝分割。
- 为了预测图像边缘区域的像素,缺失的上下文是通过镜像输入图像进行外推的
- 数据增强:使用弹性形变(网络学习这种变形的不变性,生物组织变形在生物医学分割上很常见。)
- 另一难点:同一类别接触细胞的分割。为此,我们建议使用加权损失,其中在接触细胞之间的分离背景标签在损失函数中获得较大的权重
Overlap-tile策略:对图像的某一块像素点(黄框内部分)进行预测时,需要该图像块周围的像素点(蓝色框内)提供上下文信息(context),以获得更准确的预测。这样的策略会带来一个问题,图像边界的图像块没有周围像素,因此作者对周围像素采用了镜像扩充。

无缝分割:比如你有一个非常大的图,假设是20482048的,然后直接放进网络,假设你的GPU算力不够,那么可以把他拆成4张512512的图像,然后分别进行分割,如果直接输入那就又有问题了,512512的小图的边缘,在原图中可不一定是边缘(下、右边),而且还在原图中间,细节往往很重要,在512 512中我们需要将这种边缘保留,如果采用same卷积,边缘进行0填充,那么误差就会很大,还不如我直接将边缘像素镜面对称过来进行填充。
三、训练
- 使用随机梯度下降算法
- 批量是一个样本的大小,即每个样本计算后都更新参数
- momentum (0.99)
训练数据集可以分为一个或多个Batch,更新内部模型参数之前要处理的样本数为一个Batch。当所有训练样本用于创建一个Batch时,学习算法称为批量梯度下降。当批量是一个样本的大小时,学习算法称为随机梯度下降。当批量大小超过一个样本且小于训练数据集的大小时,学习算法称为小批量梯度下降。
Epoch数是一个超参数,它定义了学习算法在整个训练数据集中的工作次数。
对于一般的SGD,其表达式为:
w := w - lr * dw
即沿负梯度方向下降。而添加momentum的SGD形式如下:
v := mu * v - lr * dw
w := w + v
其中mu为momentum系数,即如果上一次的momentum(v)与这一次的负梯度方向是相同的,则这次下降的幅度就会很大,就起到加速迭代收敛的作用。
四、损失函数
参考1
参考2
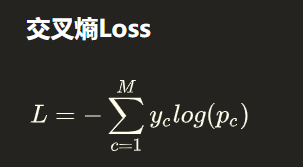
(1) 本文也采用交叉熵损失函数,在上式中,yc要么为0,要么为1. Pc是预测的值。或者说是经过softmax后的值(使得所有预测概率之和为1)。
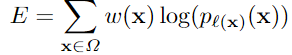
- 上式中的l(x)就是下式中的k,代表了不同的类别(channel)
- p(x) 为soft-max后输出值。
- l :Ω → {1, . . . , K},是每个像素的真实标签;
- w : Ω → R 是在训练过程中添加给每个像素的权重,
(2) soft-max
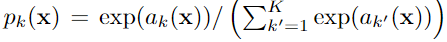
- ak(x)表示的是:位置x的像素在第k个channel上通过激活函数(activation)之后的函数输出值,相对应的pk(x)表示的是在第k个channel上面的像素位置x的通过激活函数(activation)之后的函数输出值经过 soft-max 交叉熵运算之后产生的概率值
- 当某一个像素x在通道k上的值较大,即ak(x)较大,此时在运算得到的pk(x)是接近于1的,说明该像素x属于这个类别k,反之,当某一个像素x在通道k上的值较小,即ak(x)较小,此时在运算得到的pk(x)是接近于0的,说明该像素x不属于这个类别k。
(3)权重图 weights map
在某一个通道处的特征图上,每一个像素点x对应一个 权重,然后整张特征图上面所有的像素的权重,组成了一张 权重图。
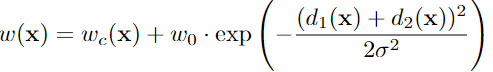
- wc(x)是权重图;预先计算每个 ground truth segmentation的权重图,以补偿训练数据集中某类像素的不同频率,并迫使网络学习我们在接触细胞之间引入的小分离边界
- d1是像素点到距离其最近的细胞的距离, d2是像素点到距离其第二近的细胞的距离
- 当d1、d2都等于0时,后面部分有最大值,且d1、d2越小,后面部分越大,即整个权重越大。当d1、当d2越小,意味着越靠近细胞边界,增大细胞边界的权重,可以迫使网络学习
(4)计算总过程
首先根据训练数据,算出每一个样本图片的w(x),即权值图;对于某一位置,计算其在所有channel上的交叉损失乘以权重图对应位置泉州 并相加;然后对于整个样本图片的所有位置都进行同一操作。
五、数据增强
1、采用平移、旋转,灰度变化进行数据增强。
2、随机弹性形变是训练带有很少注释图像的分割网络的关键。
3、使用随机位移向量在粗略的3x3网格上生成平滑变形。
4、在收缩路径的末端采用drop-out层也能得到隐式的数据增强。















 1046
1046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









