






一、
.ipynb是 Jupyter Notebook 文件的扩展名。Jupyter Notebook 是一个开源的 Web 应用程序,在数据科学、机器学习、数据分析等领域被广泛应用,下面为你详细介绍:
特点
交互性强:允许你在同一个文档中混合编写代码、运行代码片段、查看输出结果以及添加文本注释(如 markdown 格式的文本用于解释代码逻辑、分析结果等),实现了代码执行与文本说明的无缝交互。
支持多种编程语言:常见的如 Python、R、Julia 等语言都能在 Jupyter Notebook 中很好地使用,你可以根据具体的项目需求选择合适的编程语言进行开发和分析。
数据可视化便捷:能方便地将数据分析过程中的各种结果(如表格、图表等)直接在 Notebook 中展示出来,无需频繁切换到其他专门的可视化工具,有助于快速理解数据和分析思路。
结构组成
代码单元(Code Cells):用于编写和执行代码。你可以在这些单元中输入各种代码语句,然后通过运行该单元来查看代码的执行结果,结果会直接显示在代码单元下方。
文本单元(Markdown Cells):采用 markdown 语法,用于添加文本注释、标题、列表、链接等各种格式的说明性内容,以便更好地记录和解释整个分析过程。
应用场景
数据分析与探索:在对数据进行初步探索时,可以方便地导入数据、进行数据清洗、统计分析等操作,并实时查看每一步的结果,有助于快速把握数据特征。
教学与学习:教师可以利用 Jupyter Notebook 创建包含代码示例、讲解说明以及练习题的交互式教学文档,学生则可以在自己的电脑上运行这些代码并进行实践,更好地理解所学知识。
数据科学项目开发:在数据建模、算法开发等项目中,团队成员可以通过共享 Jupyter Notebook 文件来交流代码、分析思路以及项目进展,方便不同成员之间的协作。
如何使用
安装 Jupyter Notebook:通常可以通过 Python 的包管理器(如 pip 或 conda)进行安装。例如,使用 pip 安装的命令是:pip install jupyter notebook。
启动与运行:安装完成后,在命令行中输入jupyter notebook即可启动 Jupyter 服务,之后会在浏览器中打开 Jupyter 的主页面,你可以在该页面创建新的 Notebook 或打开已有的.ipynb文件进行编辑和运行操作。
二、使用的工具为Visual Studio Code
相关快捷键:
1、文件操作
Ctrl + N:新建一个文件。当你需要创建一个新的脚本(如 Python 脚本用于数据分析)或者新的配置文件时可以使用。
Ctrl + O:打开一个文件。这可以用于打开已有的数据文件(如 CSV、JSON 等格式的数据文件)或者已有的代码文件。
Ctrl + S:保存文件。在编辑代码或者数据配置文件后及时保存。
Ctrl + Shift + S:另存为文件。如果需要将文件保存为不同的名称或者格式,可以使用这个快捷键。
2、编辑操作
Ctrl + X:剪切选中的文本。在调整代码结构或者移动数据相关内容时很有用。
Ctrl + C:复制选中的文本。例如复制一段数据分析代码或者数据字段的名称。
Ctrl + V:粘贴文本。
Ctrl + Z:撤销上一步操作。如果在编写代码或者修改数据相关内容时出错,可以撤销操作。
Ctrl + Y:恢复上一步撤销的操作。
Ctrl + F:在当前文件中查找文本。可以用于查找特定的代码关键字、变量名或者数据标签。例如,查找数据分析代码中特定函数的调用位置。
Ctrl + H:在当前文件中替换文本。比如替换代码中过时的变量名或者数据格式相关的术语。
3、代码导航与查看
Ctrl + Home:跳转到文件开头。在查看长代码文件或者大型数据配置文件时,可以快速回到开头。
Ctrl + End:跳转到文件末尾。
Ctrl + PageUp:切换到上一个打开的文件。当同时打开多个数据分析相关文件(如数据读取文件、数据清洗文件、可视化文件等)时可以方便地切换。
Ctrl + PageDown:切换到下一个打开的文件。
F12:跳转到定义。如果你的代码中引用了函数或者变量,按 F12 可以查看它们的定义位置。例如,查看数据分析函数的具体实现代码。
4、代码运行与调试(取决于所安装的插件)
F5:启动调试。在调试数据分析代码(如 Python 脚本中的数据处理逻辑错误)时使用。不同的编程语言可能需要进行相应的调试配置。
Shift + F5:停止调试。
Ctrl + F5:不调试直接运行程序。比如直接运行一个数据清洗或者数据分析的脚本。
5、插件相关(对于数据分析扩展很有用)
Ctrl + Shift + X:打开扩展视图。可以用于安装和管理与大数据分析相关的插件,如 Python 扩展、数据可视化扩展等。在这个视图中可以搜索、安装、更新和卸载插件。
三、分析思路:
1.数据预处理:
加载数据并查看基本信息和前几行。对数据进行清洗,处理缺失值和异常值。选择与账号价值和游戏进度相关的特征进行分析。对特征进行标准化处理,以消除不同特征之间的量纲差异。
2.聚类分析:
使用 KMeans 聚类算法对账号进行聚类。
使用层次聚类算法对账号进行聚类。
使用 DBSCAN 聚类算法对账号进行聚类。
四、实践代码:
1.引入数据库
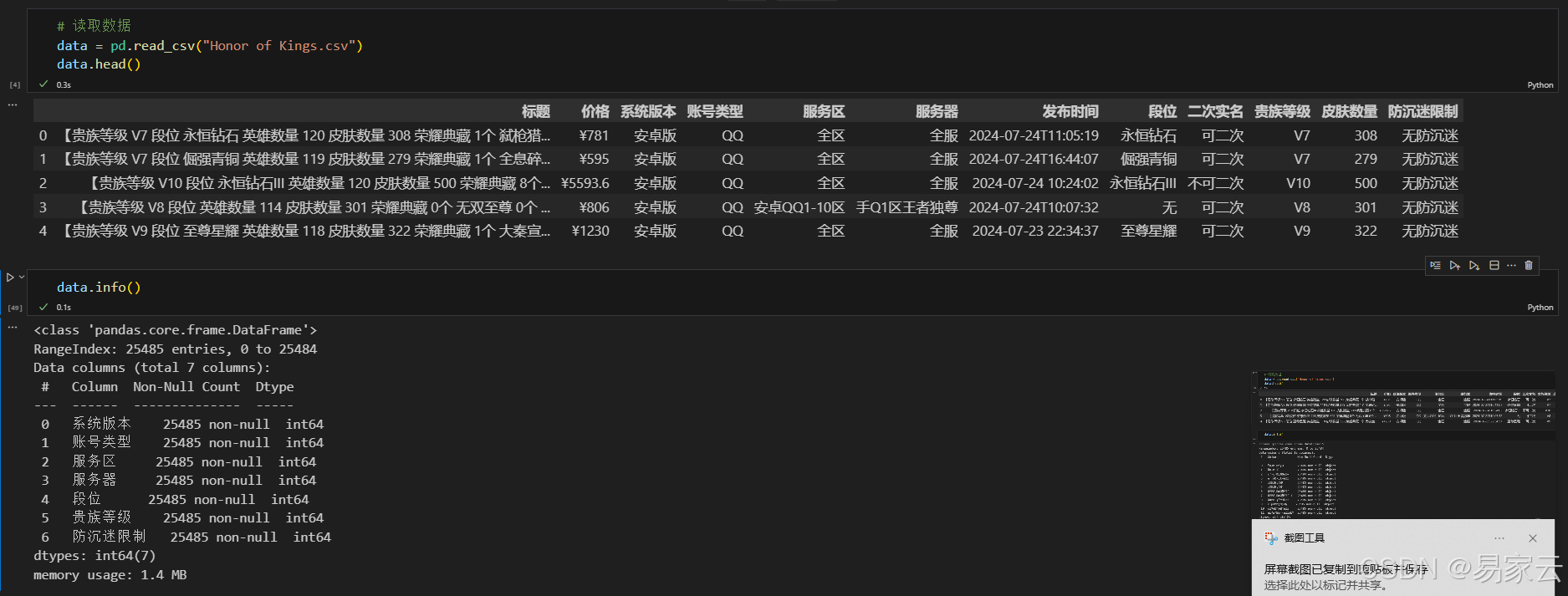
2.读取数据表,并用head(),info()查看
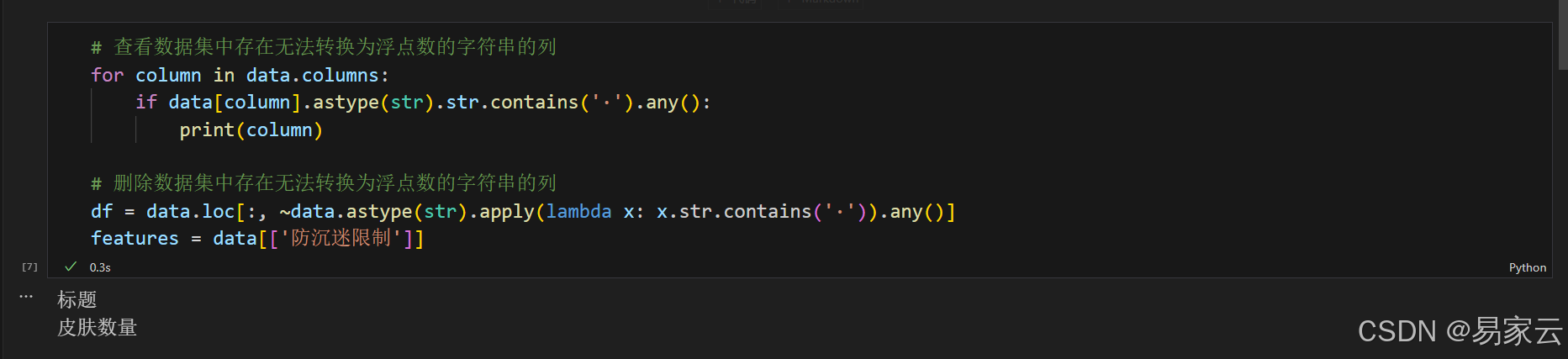
3. 查看数据集中存在无法转换为浮点数的字符串的列,并删除删除数据集中存在无法转换为浮点数的字符串的列
4.提取需要分析的字段

5.对分类字段进行编码

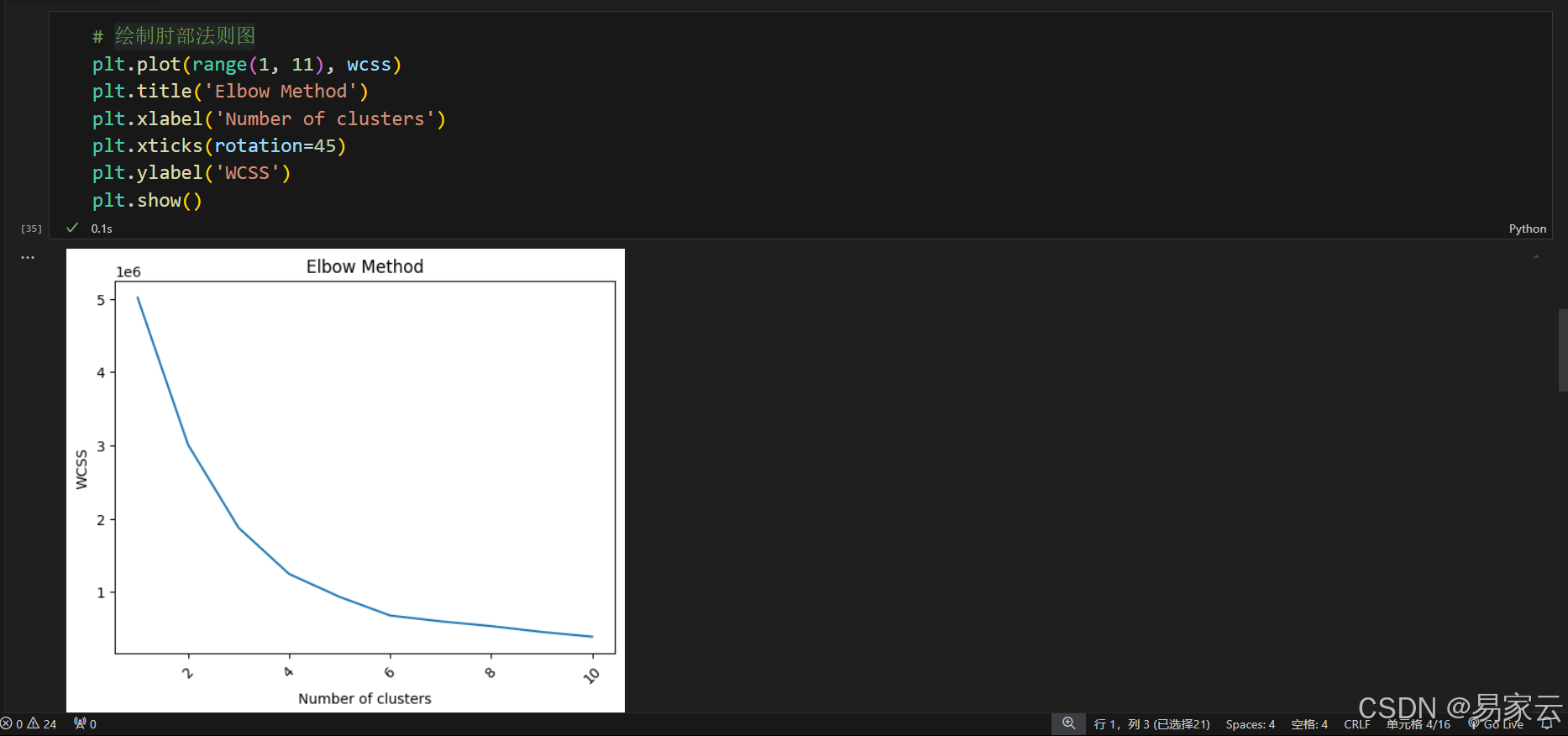
6. 使用肘部法则确定KMeans聚类的最优簇数

7.绘制肘部法则图
8.计算不同聚类数量下的轮廓系数

9.找到轮廓系数最大的聚类数量

10.使用KMeans聚类

11.使用层次聚类

12.使用DBSCAN聚类

13.输出结果
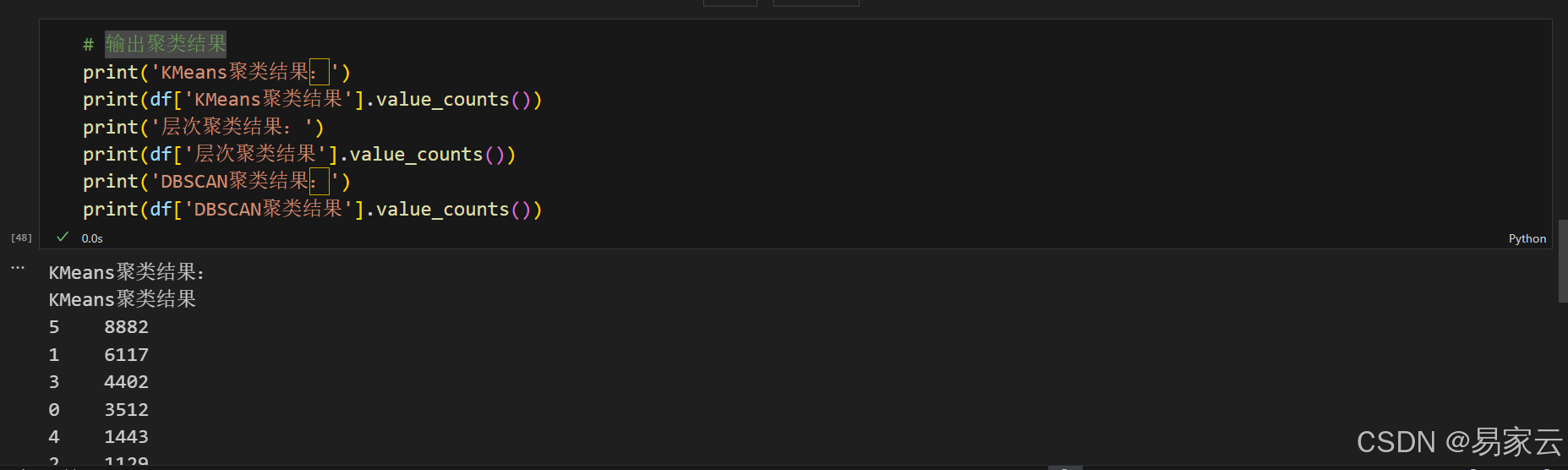
五、结论:
通过聚类分析,可以将王者荣耀交易账号分为不同的类型,每个类型的账号具有不同的特征。例如,某些聚类可能包含高等级、高皮肤数量的账号,而另一些聚类可能包含低等级、低皮肤数量的账号。
不同聚类方法的聚类结果可能存在一定的差异,这可能是由于不同聚类方法的原理和假设不同。因此,在选择聚类方法时,需要根据数据的特点和分析目的进行选择。
通过对聚类结果的可视化,可以更直观地了解不同聚类之间的差异和关系。例如,可以使用散点图展示账号在不同特征上的分布情况,从而更好地理解账号的特征和类型。
对于准备购买王者荣耀账号的玩家,可以根据聚类结果选择符合自己需求的账号。例如,如果玩家注重账号的等级和皮肤数量,可以选择属于高等级、高皮肤数量聚类的账号;如果玩家注重账号的安全性,可以选择属于二次实名和防沉迷限制聚类的账号。
需要注意的是,以上结论仅为可能的结论,具体的结论需要根据实际的聚类结果和数据分析来确定。同时,在购买王者荣耀账号时,玩家需要注意账号的安全性和合法性,避免购买到被盗或违规的账号。

















 666
666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









