







处理过后的数据
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
from sklearn.naive_bayes import GaussianNB
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
# # 设置字体
plt.rcParams["font.sans-serif"] = ["SimHei"]
# 解决图像中的 - 负号乱码的问题
plt.rcParams["axes.unicode_minus"] = False这里用的data.iloc[:,:]区分训练集和测试集,实际上可以用 train_test_split进行数据分割,后续学习中会改进
data = pd.read_csv('DataSet.csv')
# 提取自变量
x_data = data[['CO','NO2','O3','PM10','PM2.5','SO2']].reset_index(drop = True)
# 提取因变量
y_data = data['AQI'].reset_index(drop=True)
# 添加常量x0
x_data['x0'] = 1
# 分割训练集和测试集
# data1 是训练集 data2 是测试集
data1= data.iloc[653:3265,:]
data2 = data.iloc[0:653,:]
print(data2)
print(data1)
这里的数学公式是根据下图得到的,实际上在sklearn机器学习模型中,应该有相应的Regression算法

# 计算x与x的转置的乘积
xTx = xmatrix.T*xmatrix
print(xTx.shape)
# 求解逆矩阵
if np.linalg.det(xTx) == 0:
print("对称矩阵非奇异")
else:
print("矩阵可逆")
# 计算xTx的逆矩阵
xTx1 = xTx.I
# 求解相关系数
A = xTx1 * xmatrix.T * ymatrix
# 测试集data2
data_test = data2[['CO','NO2','O3','PM10','PM2.5','SO2']].reset_index(drop = True)
data_test['x0'] = 1
xtest_narray = np.array(data_test)
xtest_matrix = np.mat(xtest_narray)
# 模型预测 使用参数A 计算预测y值
ytest_predict = xtest_matrix * A相关系数

画图
# 绘制预测真实值和误差值 653条数据
# 首先将矩阵转换为数组 data2['date'] ytest_predict data2['AQI']
y_predict = ytest_predict.tolist();
y_value = data2['AQI'].tolist()
x_value = data2.index.tolist()
plt.title("基于多重线性回归空气质量指数预测")
plt.xlabel('样本点')
plt.ylabel('真实之和预测值')
plt.scatter(x_value,y_predict,color = 'y',label='预测值',s=10)
plt.scatter(x_value,y_value,color = 'g',label='真实值',s=2)
plt.legend()
plt.show()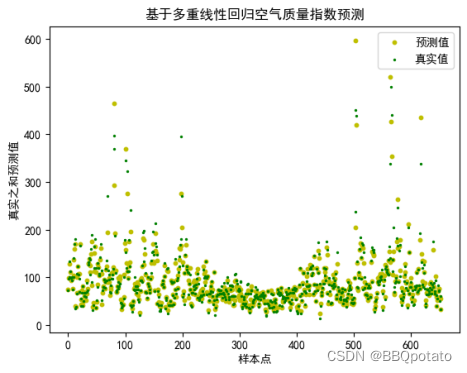
求解r2_score
from sklearn.metrics import r2_score
R2 = r2_score(y_predict,y_value)
R2
r2_score 的概念



















 655
655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









