






 文章讲述了如何处理不同时间单位的气象和遥感数据,包括年、月、日的数据。主要内容涉及数据清洗,如替换异常值(-9999和0),按比例删除异常值或用平均值填充,构建以月份为索引的数据结构,以及通过concat和merge方法整合不同时间单位的数据。此外,还介绍了从Excel文件读取数据和写入处理后的数据到新文件的过程。
文章讲述了如何处理不同时间单位的气象和遥感数据,包括年、月、日的数据。主要内容涉及数据清洗,如替换异常值(-9999和0),按比例删除异常值或用平均值填充,构建以月份为索引的数据结构,以及通过concat和merge方法整合不同时间单位的数据。此外,还介绍了从Excel文件读取数据和写入处理后的数据到新文件的过程。
各气象数据最后汇总
处理时间单位不一样的数据,重新构建月份为索引
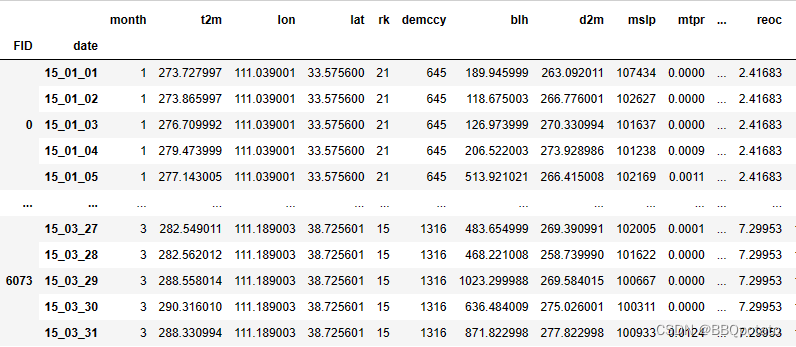
数据预览
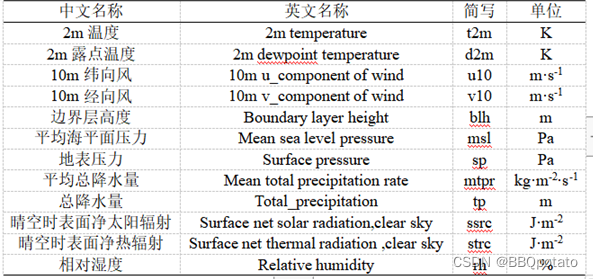
era5气象数据以及遥感数据格式有年月日,单位为年的数据有人口、高程
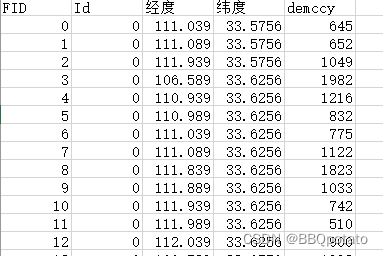
FID是各站点ID,2015列是个站点人口数,demccy是高程
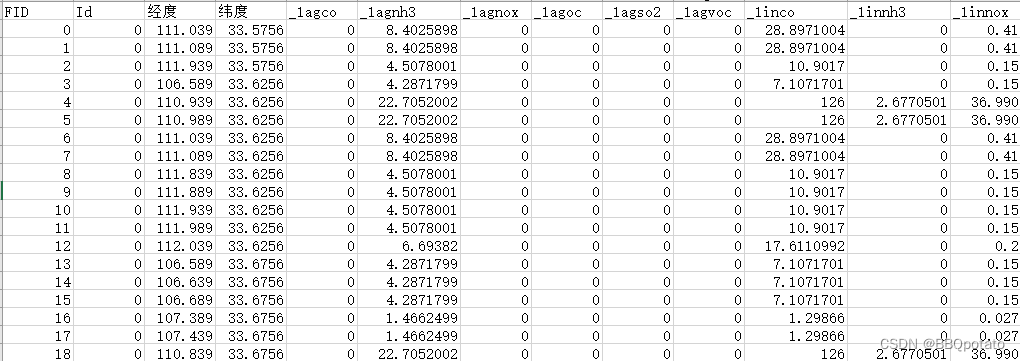
单位为月的数据有前体物, 列标签为 _月份 + 产生前体物的方式 + 产生的前体物
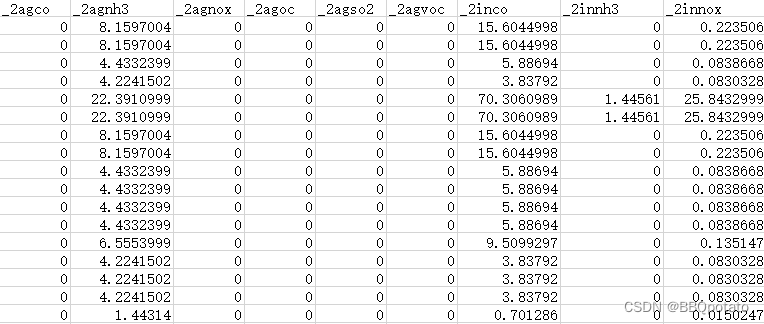
单位为日的数据有各era5的气象因子,有t2m进行举例
其中涉及到nc->tiff转文件格式的代码,参考:
<链接>
最后是列标签为天数的臭氧数据,该数据有许多-9999和0 即未观测到的数据,需要做预处理,并且对应到某天
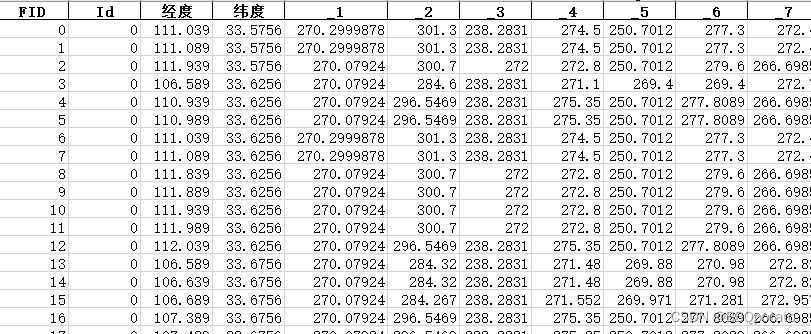
数据预处理
数据预处理部分主要是剔除异常值,异常值主要存在于o3文件中的-9999和0
import numpy as np
import pandas as pd
import math
dataset = pd.read_excel('遥感数据未剔除异常值\omto3e2022.xlsx')
# 将-9999转换成0 方便后续统计异常值占总数居的比例
dataset = dataset.replace(-9999,0)
# 删除某列值为-9999的数据
# df = df[(df!=-9999).all(axis=1)]起初是剔除异常值就可以,后续发现剔除后数据太少,改为剔除数据的15%
# 异常值 > 15% 则删除该列 6是dataset中除了臭氧数据的其他标签
for i in range(1,dataset.shape[1]-6):
if '_'+str(i) in dataset:
if len(dataset[dataset['_'+str(i)]==0])/len(dataset['_'+str(i)]) >= 0.15:
dataset.drop('_'+str(i),axis=1,inplace=True)
后来改为将异常值替换为平均值
# 异常值为-9999和0的 直接填充为该列值不是-9999和 0的数值的平均值
# 从_1 到最后一列 前面的特征值为6列
for i in range(1,dataset.shape[1]):
if '_'+str(i) in dataset:
#正常值筛选出为一列 并求出平均值
dataavg = dataset[(dataset['_'+str(i)]!=0) & (dataset['_'+str(i)]!=-9999)]
avg = round(dataavg['_'+str(i)].mean(),6)
print(avg)
#求出平均值后,如果为异常值则替换成平均值
dataset['_'+str(i)] = dataset['_'+str(i)].replace(0,avg)最后进行删除空值,因为有一些列(一些天)都没有采集到数据,平均值为空 填空也为空
dataset.dropna(axis=1,inplace=True)最后直接写入
dataset.to_excel('遥感数据未剔除异常值\omto3e2022.xlsx')不足之处是没有写批量处理文件的代码,一共有8年的数据都是手动替换的
数据预处理
处理单位为年的数据
处理单位为年的数据和简单,因为相关表格都是2015年的数据,直接按照站点不同直接concat就可以了
import numpy as np
import pandas as pd
# 人口数据就是以年为单位的
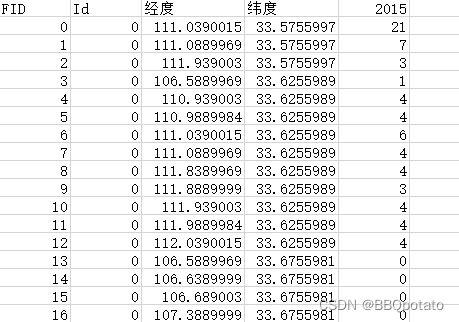
data1 = pd.read_excel(r'2015/rk2015.xlsx',index_col = False)
# 取经度纬度人口作为初始数据集,后续别的数据集直接concat
data1 = data1.loc[:,['经度','纬度',2015]]
data1 = data1.reset_index(drop=True)
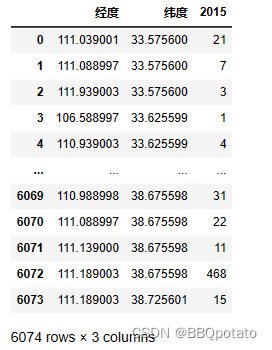
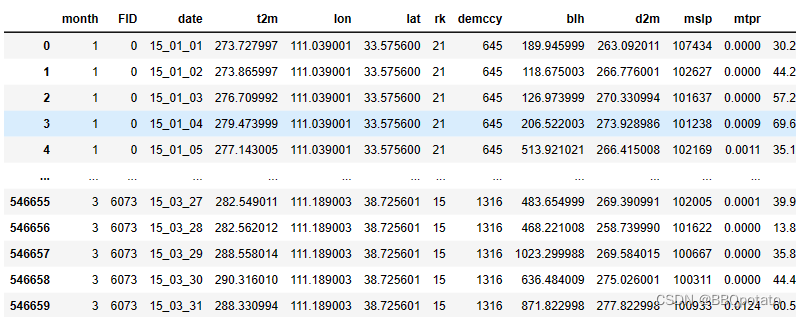
读取温度数据,因为最后的单位是每日,因此需要将年数据concat到日数据中
data2 = pd.read_excel(r'2015\t2m2015.xlsx',index_col='FID')
#这里取第一季度的数据 方便运算
spr2015 = data2.loc[:,data2.columns[(data2.columns >= '15_01_01') & (data2.columns < '15_04_01')]]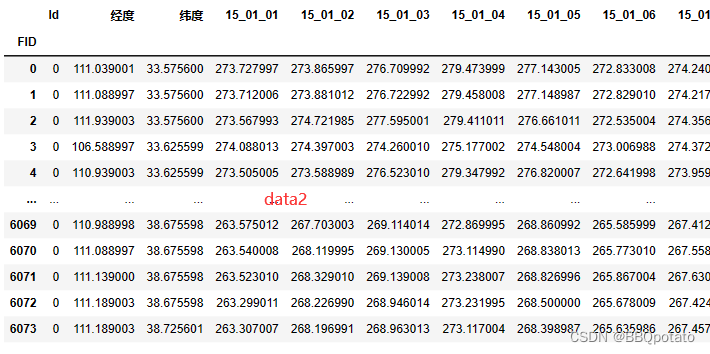
因为需要一个站点全年的数据,并且最后的表格里纵坐标只能是
# 解构
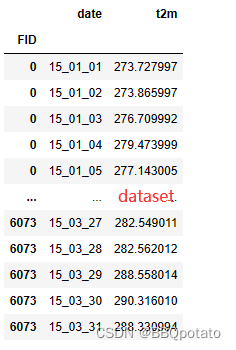
t2m = spr2015.stack()
# 重新设置索引为 FID
dataset = t2m.to_frame().reset_index().set_index('FID')
# 重命名列
dataset.columns = ['date','t2m']
最后合并,并且重新命名
dataset = pd.concat([dataset,data1],ignore_index= False,axis=1)
dataset = dataset.rename(columns={2015:'rk','经度':'lon','纬度':'lat'},index=None,axis=None)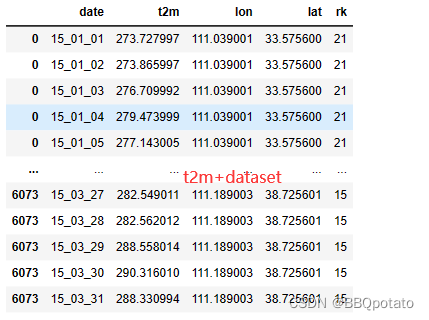
处理单位为日的数据
读取其他单位为日的气象数据,没有写封装方法 可以写,这里依次往下运行的
# 读取其他气象数据并封装
d2m = pd.read_excel(r'2015\d2m2015.xlsx',index_col='FID')
d2m2015 = d2m.loc[:,d2m.columns[(d2m.columns >= '15_01_01') & (d2m.columns < '15_04_01')]]
d2m2015 = d2m2015.stack().to_frame().reset_index().set_index('FID')
d2m2015.rename(columns={'level_1':'date',0:'d2m'},inplace=True)
d2m2015 = d2m2015['d2m']
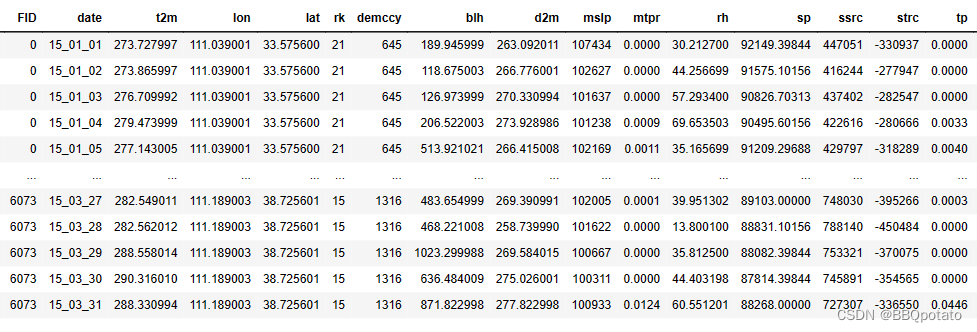
dataset = pd.concat([dataset,d2m2015],ignore_index=False,axis=1)# 读取其他气象数据并封装
mslp = pd.read_excel(r'2015\mslp2015.xlsx',index_col='FID')
mslp2015 = mslp.loc[:,mslp.columns[(mslp.columns >= '15_01_01') & (mslp.columns < '15_04_01')]]
mslp2015 = mslp2015.stack().to_frame().reset_index().set_index('FID')
mslp2015.rename(columns={'level_1':'date',0:'mslp'},inplace=True)
mslp2015 = mslp2015['mslp']
dataset = pd.concat([dataset,mslp2015],ignore_index=False,axis=1)最后运行结果
处理单位为月的数据
# 2020qtw 15_01 15_02 15_03 对应 _1 _2 _3
# 首先删除2020qtw中 为0的列 理解是 说明这种方式不会产生这种前体物 假定是 所有年份都不会产生
qtw = pd.read_excel(r'2015/2020qtw.xlsx',index_col='FID')
qtw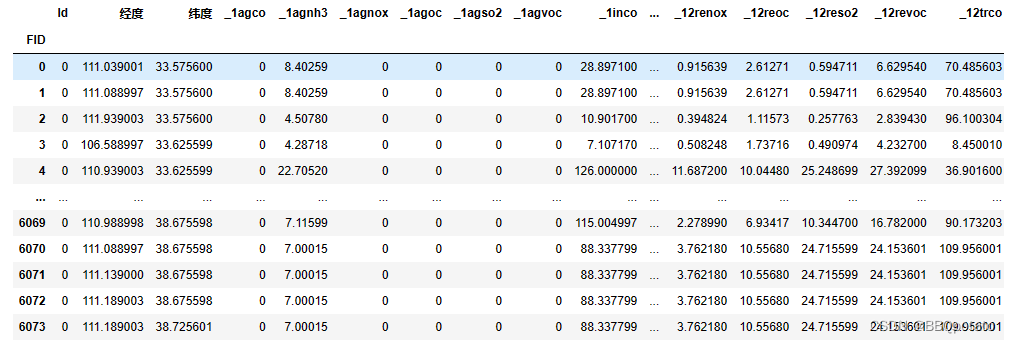
# 删除全为0的列
qtw=qtw.loc[:,~(qtw == 0).all(axis=0)]
# 省略了经纬度
qtw1 = qtw.iloc[:,2:]多级索引,添加month为新的列索引
t1 = qtw1.stack().reset_index().set_index('FID')
# 创建一个新的列month 赋值 并设置为索引
t1['month'] = t1.level_1.str.extract('(\d+)',expand=True).astype(int)
t1 = t1.set_index('month',append=True)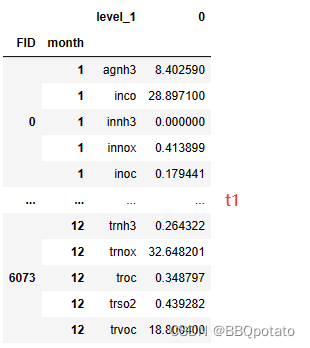 同时在dataset 从date列中提取到月份 生成新的索引。即在DataFrame分割列形成新的索引
同时在dataset 从date列中提取到月份 生成新的索引。即在DataFrame分割列形成新的索引
# str.extract 提取到 由于date列数据格式为 15_01_01 因此取_ _之间的就为月份
dataset['month'] = dataset.date.str.extract('_(\d+)_',expand=True).astype(int)
# 重新命名index列为FID
dataset = dataset.rename(columns={'index':'FID'},index=None,axis=None)
# 设置了多级索引 multindex
dataset = dataset.set_index(['FID'],append=False)
dataset = dataset.set_index('month',append=True)对t1进行数据处理
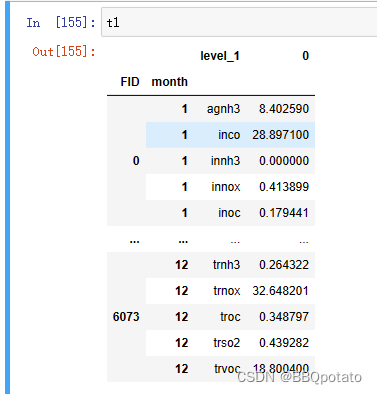
# 循环遍历 level_1标签 一共有24种 传播途径*传播物
for i in range(0,24):
temp = t1[t1.level_1==t1.level_1.iloc[i]]
temp = temp[0].to_frame().rename(columns={0:t1.level_1.iloc[i]})
dataset = pd.merge(dataset,temp,how='left',left_index=True,right_index=True)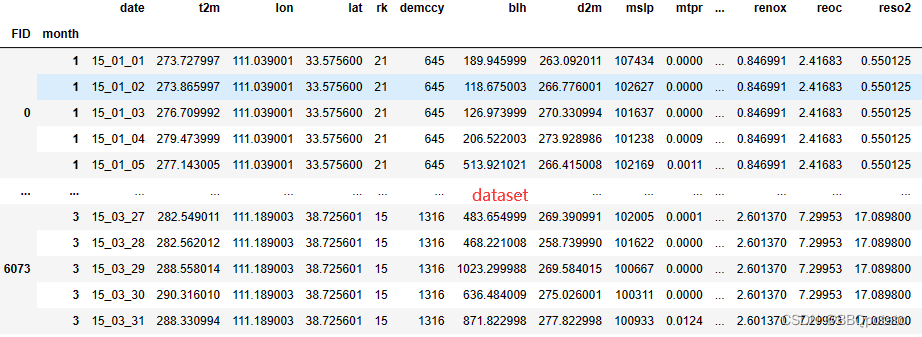
处理单位是第n天的数据
o3= pd.read_excel(r'2015\omto3e2015(卫星臭氧).xlsx',index_col='FID')
# o3舍弃_ 列名中的特殊符号
o3 = o3.rename(columns=lambda x: x.replace("_","")) 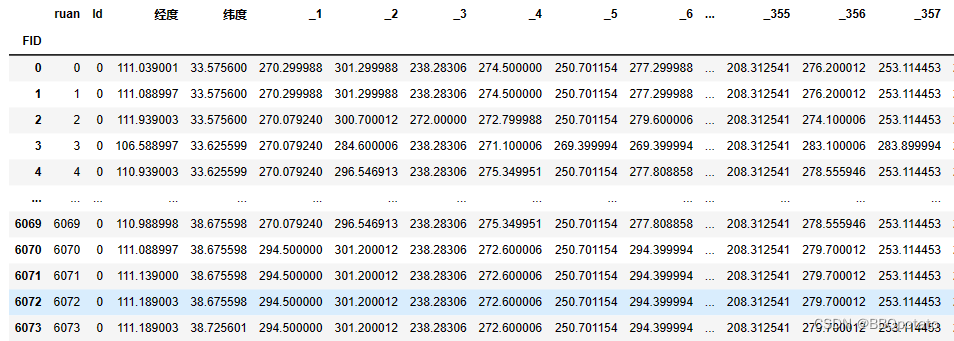
中间是有部分天因为剔除了全为空的值而不存在 要将天数对应到日期
# 打印出不存在臭氧数据的天数
count=0
i=0
while(count<346):
if o3.columns[count] != '_'+str(i+1):
print(i+1)
i = i+1
else:
i=i+1
count = count+1导入新的包,因为要将天数转化为日期
# 将其他天数 转化成时间 并format %y_%m_%d 并写入新的文件
import datetime将第n天转化为当年日期 参考Python日期和天数互相转换
first_day = datetime.datetime(2015,1,1)
o3 = o3.rename(columns=lambda x:datetime.datetime.strftime(first_day+datetime.timedelta(int(x)-1),'%y_%m_%d'))
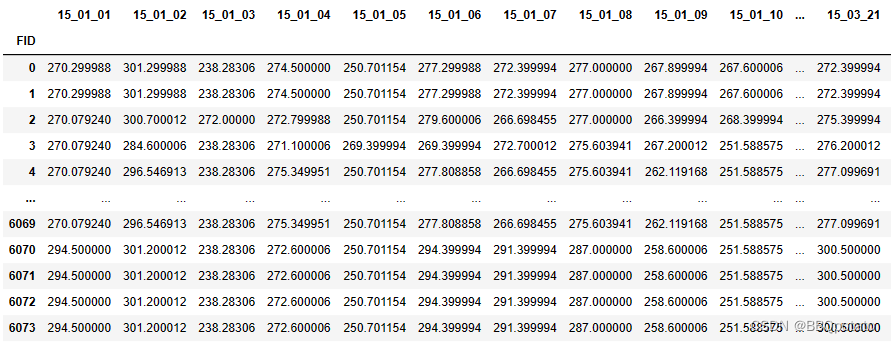
此时可以按照处理日单位的数据 对臭氧数据进行处理
o32015 = o3.loc[:,o3.columns[(o3.columns >= '15_01_01') & (o3.columns < '15_04_01')]]
o32015 = o32015.stack().to_frame().reset_index().set_index('FID')
o32015.rename(columns={'level_1':'date',0:'o3'},inplace=True)
# o32015 = o32015['o3']
o32015 = o32015.set_index('date',append=True)
### 这里因为我先处理了月份数据 所以dataset 的索引是FID month 现在改成FID date
# dataset索引发生了改变需要充值索引
dataset = dataset.reset_index().rename(columns={'level_0':'FID','level_1':'month'}).set_index('FID',append=False)
# append =True 表示是追加index 不删除原来的index
dataset = dataset.set_index('date',append=True)此时
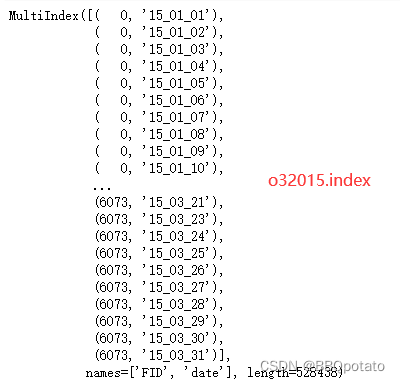
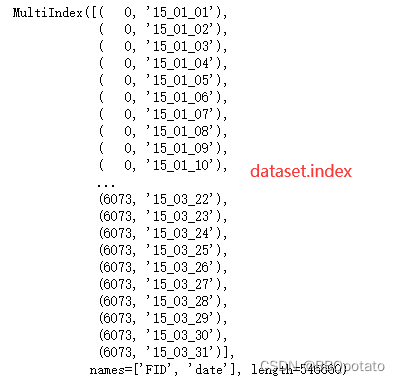
最后完成的数据 写入excel中
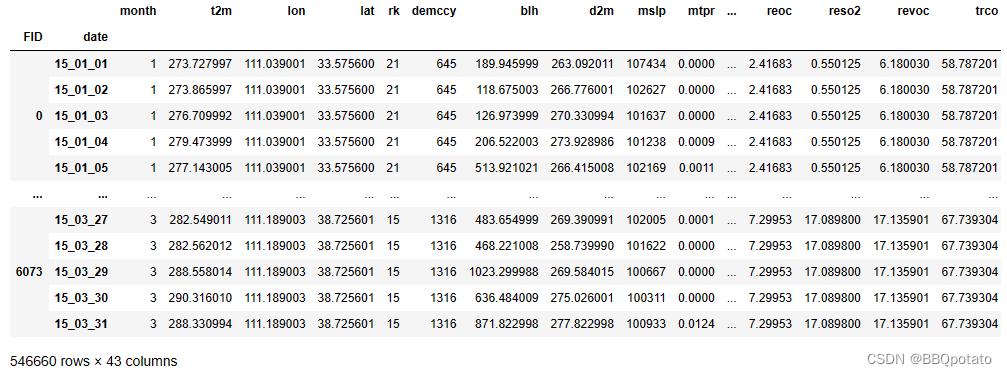
# 将该数据写入test文件夹中
dataset.to_excel(r'test/2015spring.xlsx')主要是针对不同时间单位的数据 分别构建索引 最后用concat、merge、join进行拼接即可


















 6175
6175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









