







word2vec (四) 动手训练一个词向量空间
开源的word2vec工具已经有不少了,可以直接使用google开源的C版本,也可以用gensim版本的。这里我就用gensim的word2vec来训练一个词向量空间。
训练语料输入
gensim word2vec的API接受一系列的句子作为输入语料,其中每一个句子是一系列词构成的list。如下所示
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
将语料都转换为一个Python的list作为输入是很方便,但是如果输入的语料特别大,大到内存都装不下,就不能采用这种方式。gensim的API并不要求sentences必须是list对象,只要输入的sentences是iterable的就行,那我们只要一次载入一个句子,训练完之后再将其丢弃,内存就不会因为语料过大而不够了。我们通过下面的代码就可以生成一个iterator。事先已经将训练语料分词,词与词之间采用空格分开,并保存在一个文档里。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
其实用一个函数也可以生成一个迭代器,只不过函数生成的迭代器迭代一轮就失效了,而这里需要迭代多轮。第一轮统计词频,用于生成哈夫曼树。后续用于训练,因此封装成一个类。
训练
准备好语料以后就可以开始训练了,示例代码如下
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
备注:采用的语料是在知乎上抓取的100个topic下的问题,在文末会给出原始语料与分词后语料的网盘地址,感兴趣的可以下载玩玩。
gensim.models.Word2Vec() 有一系列的参数,常用的如下
- size 定义词向量的维度,默认是100
- alpha 初始的学习率,随着训练的进行,逐渐减少至0
- window 扫描句子的窗口大小,默认值为5
- min_count 过滤掉一些低频词,如果一个词在整个语料库里出现的次数小于min_count,在训练的时候就不考虑这个词。
- max_vocab_size 限制一下词汇表的数量,避免太多词占用太多内存,默认为None
- workers 训练模型的线程
- sg 训练采用的算法,sg=0 采用CBOW,sg=1采用skip-gram
- hs 为1的时候采用hierarchical softmax,如果为0且negative也非0,则采用negative sampling方案
- negative negative sampling的词数,通常是5-20
- cbow_mean 0或1。如果为0,则隐层为输入层的SUM,为1隐层为输入层向量的均值。
- iter 迭代遍历语料库的次数,默认值为5
其中,worker参数仅在安装了Cython是有用的,没有Cython由于python的GIL的原因只能用单核。
保存与加载模型
训练好以后可以保存模型用于以后使用。代码如下
- 1
- 2
- 3
- 1
- 2
- 3
看看效果
可以看看基于那些比较少的语料训练出来的效果如何
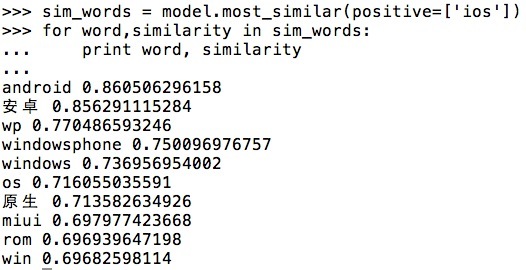
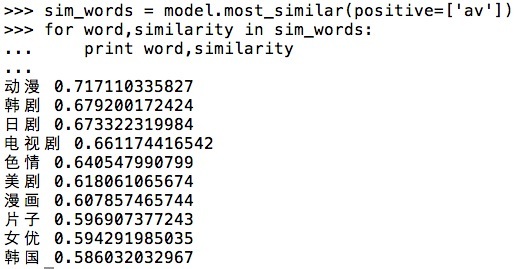
查看了与’iOS’和’av’比较相似的词,结果看起来还挺有意思的
语料
原始语料 http://pan.baidu.com/s/1nviuFc1
训练语料 http://pan.baidu.com/s/1kVEmNTd















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









