






使用MMSegmentation进行语义分割
一、前言
本实例将通过使用语义分割,将道路在实际场景中分割出来,从而为无人驾驶小车提供道路信息和前进方向信息。
语义分割作为计算机视觉中一项基础任务,同时在自动驾驶/视频编辑等领域中有重要的应用,因此一直受到学术界和工业界的广泛关注。在近几年的会议中,语义分割的论文层出不穷,但是市面上一直缺乏一款能够相对公平比较各种方法的框架。为了方便研究员和工程师们,MMLab开源了一套基于 PyTorch 实现的标准统一的语义分割框架:MMSegmentation。
https://github.com/open-mmlab/mmsegmentation
在 MMSeg 下,其复现和比较了很多语义分割的算法,并对训练测试的超参进行了优化和统一,在精度,速度,稳定性等方面都超过目前开源的其他代码库。
MMSegmentation
MMSegmentation 保持了 MM 系列一贯的风格,拥有灵活的模块化设计和全面的高性能model zoo。目前支持18种算法,大部分算法都提供了多种 setting 以及在 Cityscapes,ADE20K,Pascal VOC 2012上的训练结果(目前应该是语义分割中最大的 模型库)。
- https://github.com/open-mmlab/mmsegmentation/blob/master/docs/dataset_prepare.md#nighttime-driving)
MMSeg 作为全新的语义分割框架,和其他的框架相比,它提供了更强更快的主流算法,统一超参的公平比较,附带丰富的配置文件和五花八门的 tricks,而且非常灵活易于拓展。
二、制作数据集
使用Labelme来标注自己的数据集:
https://github.com/wkentaro/labelme
https://blog.csdn.net/u014061630/article/details/88756644
1. Labelme介绍
Labelme 是一个图形界面的图像标注软件。用 Python 语言编写的,图形界面使用的是 Qt(PyQt)。

labelme作用:
- 对图像进行多边形,矩形,圆形,多段线,线段,点形式的标注(可用于目标检测,图像分割,等任务)。
- 对图像进行进行 flag 形式的标注(可用于图像分类 和 清理 任务)。
- 视频标注
- 生成 VOC 格式的数据集(for semantic / instance segmentation)
- 生成 COCO 格式的数据集(for instance segmentation)
2.Labelme安装
首先安装Anaconda:
https://www.cnblogs.com/dream-it-possible/p/14301540.html
然后运行以下命令:
##################
## for Python 2 ##
##################
conda create --name=labelme python=2.7
source activate labelme
# conda install -c conda-forge pyside2
conda install pyqt
pip install labelme
# 如果想安装最新版本,请使用下列命令安装:
# pip install git+https://github.com/wkentaro/labelme.git
##################
## for Python 3 ##
##################
conda create --name=labelme python=3.6
source activate labelme
# conda install -c conda-forge pyside2
# conda install pyqt
pip install pyqt5 # pyqt5 can be installed via pip on python3
pip install labelme
使用labelme命令打开标注界面
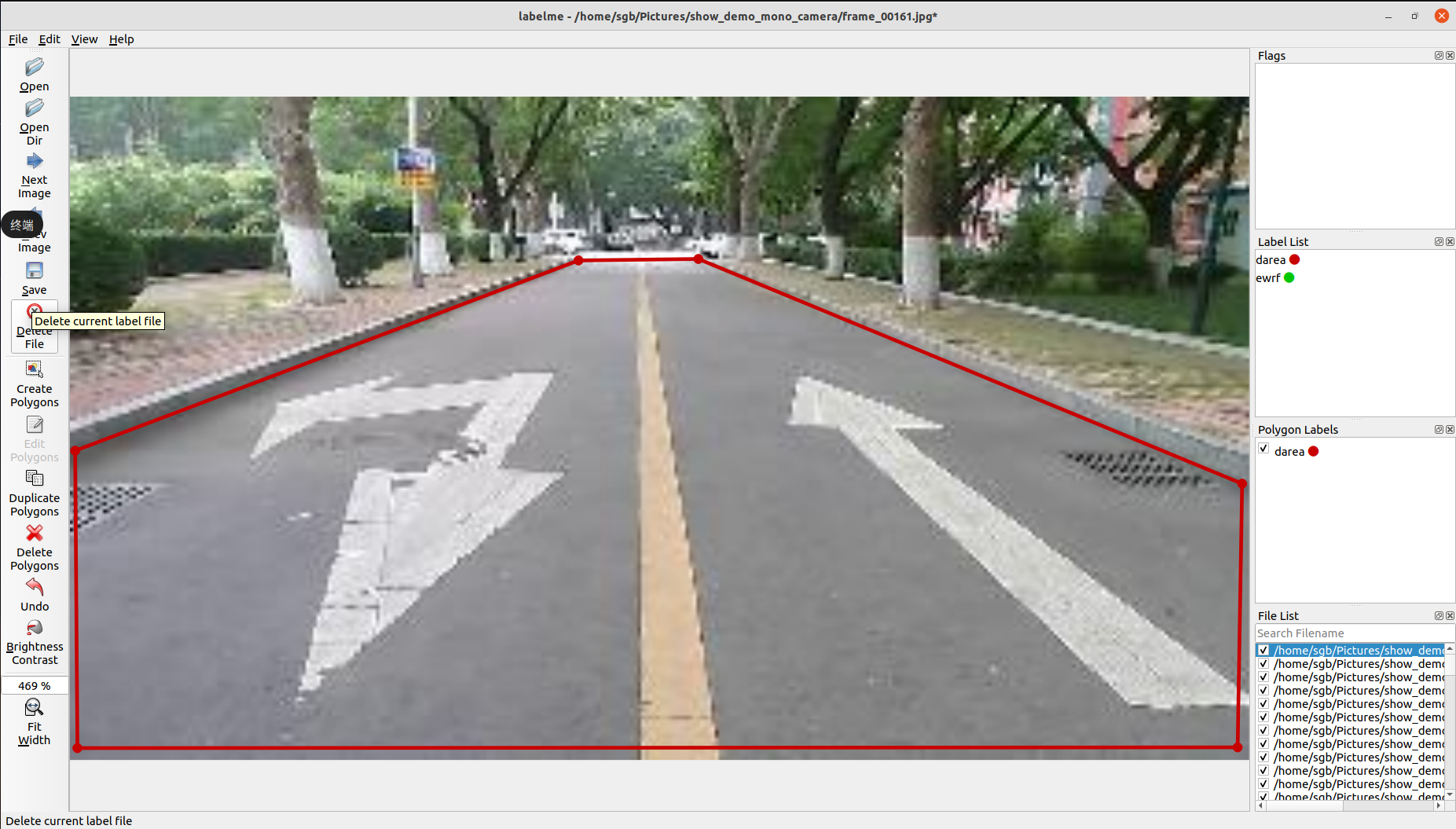
点击Open_Dir打开需要标注的数据集,这里分两类数据集,可行驶区域(darea),背景(background),标注如下图所示。
点击左侧create polygons,依次标定点,使其形成闭合区域,写明所标类别,这里背景可以选择不标注。
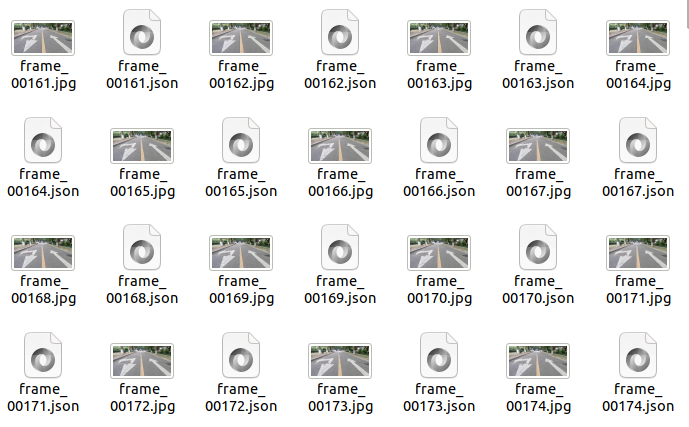
标定后保存,会自动生成一个.json的文件,这个.json文件和你的图片放在一起就好。
使用命令
git clone https://github.com/wkentaro/labelme.git
下载labelme支持文件。
但是需要注意的是,mmsegmentation同mmdetection一样,有一些固定的数据集格式。在目标检测中,最为常见的当属COCO和VOC两种格式了。
对于语义分割来说,我们这里按照VOC数据对标注好的数据进行转化。转化方式非常简单,只使用labelme即可。
读者可以在/labelme/examples/semantic_segmentation/下:制作一份labels.txt文件:__ignore__和_background_是要写在最前面的。然后后面依次写上你的类名即可。

运行指令:
python ./labelme2voc.py data_annotated data_dataset_voc --labels labels.txt
其中:
- data_annotated: 是用Labelme标注好的数据文件夹(图片与.json一一对应)。
- data_dataset_voc:是生成的VOC格式的数据集。
得到数据集如下:
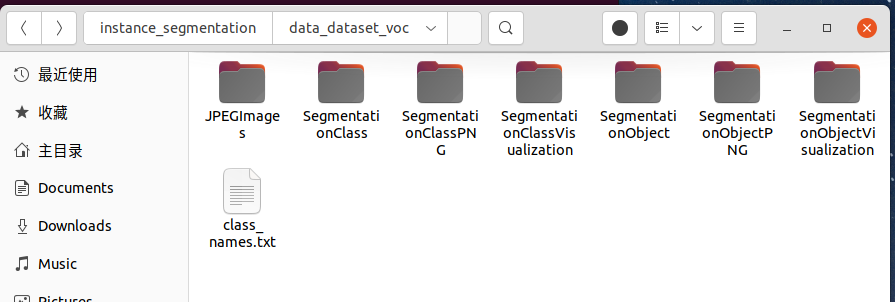
其中,JPEGImages是原始图片,SegmentationClass存储的是.npy格式的标注数据。SegmentationClassPNG是标注图片。SegmentationClassVisualization是原图与标注区域的mask格式。
就此数据集准备完毕。
三、环境搭建
1.环境搭建
这里建议使用anaconda安装对应环境
先使用conda创建一个独立的测试环境
conda create --name=mmsegmentation python=3.7.0
conda activate open-mmlab
接下来安装pytorch
首先使用命令查看当前环境的cuda版本:
nvcc -V

可以看到这里cuda版本为11.1,对照自己的cuda和pytorch版本,具体可参考:
https://pytorch.org/get-started/locally/
这里我们安装pytorch1.8.1,使用如下命令:
pip install torch==1.8.0+cu111 torchvision==0.9.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html
注意这里的cu111指cuda版本为11.1,读者需要替换为自己所需的版本
下面安装mmcv库,一定要注意对照自己的cuda和pytorch版本,具体可参考:
https://mmcv.readthedocs.io/en/latest/get_started/installation.html
pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.8.0/index.html
接下来下载mmsegmentation支持文件
pip install git+https://github.com/open-mmlab/mmsegmentation.git # install the master branch
通过以上命令安装mmsegmentation运行必要环境,此外,还需在mmsegmentation根目录下运行以下命令进行补充。
pip install -r requirements.txt
待安装完毕环境即搭建完成。
2.验证环境
为了验证 MMSegmentation 和它所需要的环境是否正确安装,我们可以使用样例 python 代码来初始化一个 segmentor 并推理一张 demo 图像。
from mmseg.apis import inference_segmentor, init_segmentor
import mmcv
config_file = 'configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py'
checkpoint_file = 'checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
# 从一个 config 配置文件和 checkpoint 文件里创建分割模型
model = init_segmentor(config_file, checkpoint_file, device='cuda:0')
# 测试一张样例图片并得到结果
img = 'test.jpg' # 或者 img = mmcv.imread(img), 这将只加载图像一次.
result = inference_segmentor(model, img)
# 在新的窗口里可视化结果
model.show_result(img, result, show=True)
# 或者保存图片文件的可视化结果
# 您可以改变 segmentation map 的不透明度(opacity),在(0, 1]之间。
model.show_result(img, result, out_file='result.jpg', opacity=0.5)
# 测试一个视频并得到分割结果
video = mmcv.VideoReader('video.mp4')
for frame in video:
result = inference_segmentor(model, frame)
model.show_result(frame, result, wait_time=1)
当您完成 MMSegmentation 的安装时,上述代码应该可以成功运行。
此外还可以使用demo脚本可视化单张图片,
python demo/image_demo.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} [--device ${DEVICE_NAME}] [--palette-thr ${PALETTE}]
样例:
python demo/image_demo.py demo/demo.jpg configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth --device cuda:0 --palette cityscapes
推理的 demo 文档可在此查询:demo/inference_demo.ipynb 。
四、配置文件编写与必要的设置
对于mmsegmentation来说,如果读者想快速使用的话。config文件几乎是你唯一需要改动的东西。mmseg的模型使用,训练配置,数据地址都是靠config指明的。
在mmseg的官网中,有关config的资料很清晰,但是细节并不到位。
config是有继承关系的,根文件就是_base_中的一个个文件。虽如此,但仍然不建议初次使用的读者使用官网提供的简略写法。
在mmsegmentation的configs下,存放了各式各样的模型的配置文件,这些配置文件大多数都是针对的大型开源数据集。我们需要改的不是网络结构,主要是你的数据集地址,你定义的类别数,以及必要的训练设置。
这里可以通过运行一遍train来让系统自动生成一个config文件,然后复制出来进行自己的更改,将tools中的train.py复制到mmsegmentation根目录下,并运行以下代码:
python train.py configs/deeplabv3/deeplabv3_r50-d8_512x512_20k_voc12aug.py
运行后报错正常,此时根目录下会生成work_dirs文件夹,并在其中生成我们所需的config文件:

将其拷贝出来,就可以基于此修改我们的配置文件了。
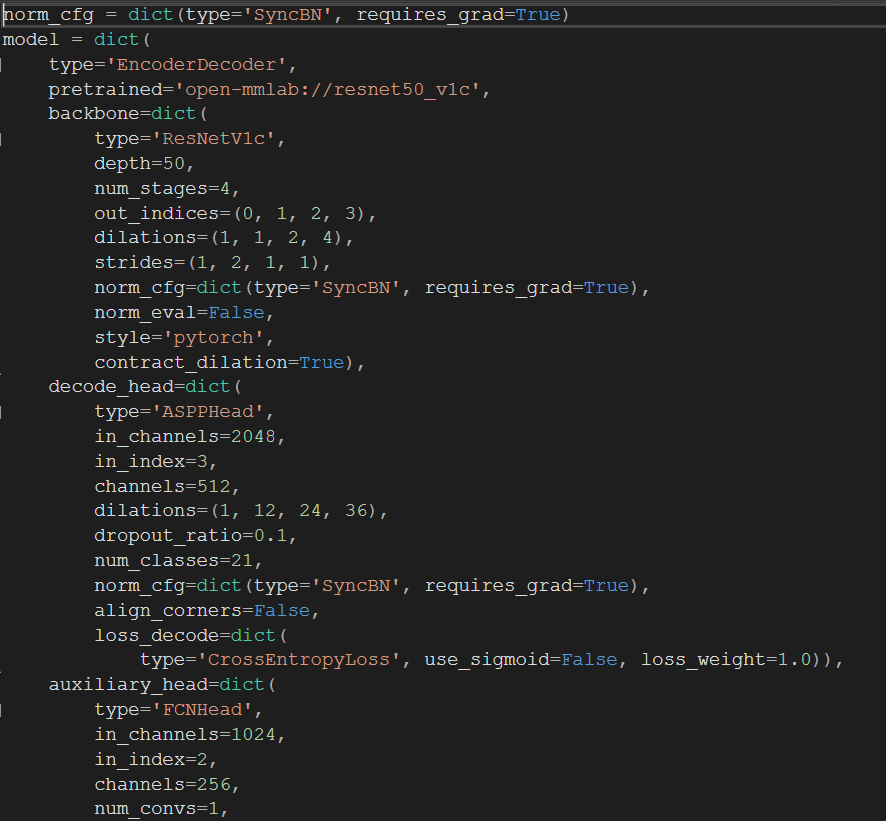
对于config文件,我们只需要关注数据集、类别、训练配置。
整个config文件大致可分为三个部分,即model , data 以及一些训练的配置。
1.数据集地址
我们首先修改训练数据的地址

在config文件的第43行,是我们的数据集要遵照的格式,因为在准备数据集阶段我们已经修改为VOC格式,因此这里不用修改。
第44行是我们数据集的文件目录,这里我将其放入根目录data文件下。

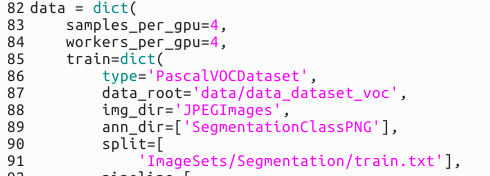
再往下,进入data字典下,我们改动第87行的数据地址。第88行的img_dir是指语义分割数据集的原始图片,我们存到了JPEGImages下;ann_dir存放的是标注文件,我们存放的地址是SegmentationCLassPNG。**注意,原始VOC还进行了数据增强,读者把带有Aug对应的地方删掉即可。**第90行的split对应的是指定哪些图片存放train.txt

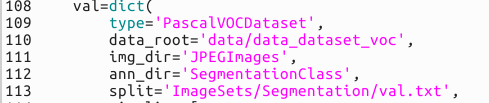
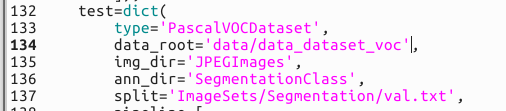
同理还需要test.txt 和val.txt,下面我们将制作这三个txt文本。
首先执行以下代码将全部数据图片的名称提取并保存在一个txt文件中
import os
path = "F:\Dataset\data_dataset_voc\JPEGImages"
filenames=os.listdir(os.getcwd())
for name in filenames:
filenames[filenames.index(name)]=name[:-4]
out=open('names.txt','w') #输出的txt文件名称
for name in filenames:
out.write(name+'\n')
out.close()
然后将txt中图片名称随机分为3类,即训练集、测试集和验证集:
import random
num_line = 0
def write_to_txt(file, start, end):
with open(file, 'w') as name:
for i in data[start:end]:
name.write(''.join(i) + "\n")
name.close()
if __name__ == '__main__':
data = []
with open('names.txt', 'r') as f:
for line in f:
data.append(list(line.strip('\n').split(',')))
num_line = num_line + 1
f.close()
print(num_line) #数据集总数
random.shuffle(data)
write_to_txt("train.txt",0,400) #这里需要自己根据自己数据集数量进行分配
write_to_txt("test.txt",400,450)
write_to_txt("val.txt",450,len(data) + 1)
最后修改好的数据集部分代码如下
train部分
val部分
test部分
2.类别配置
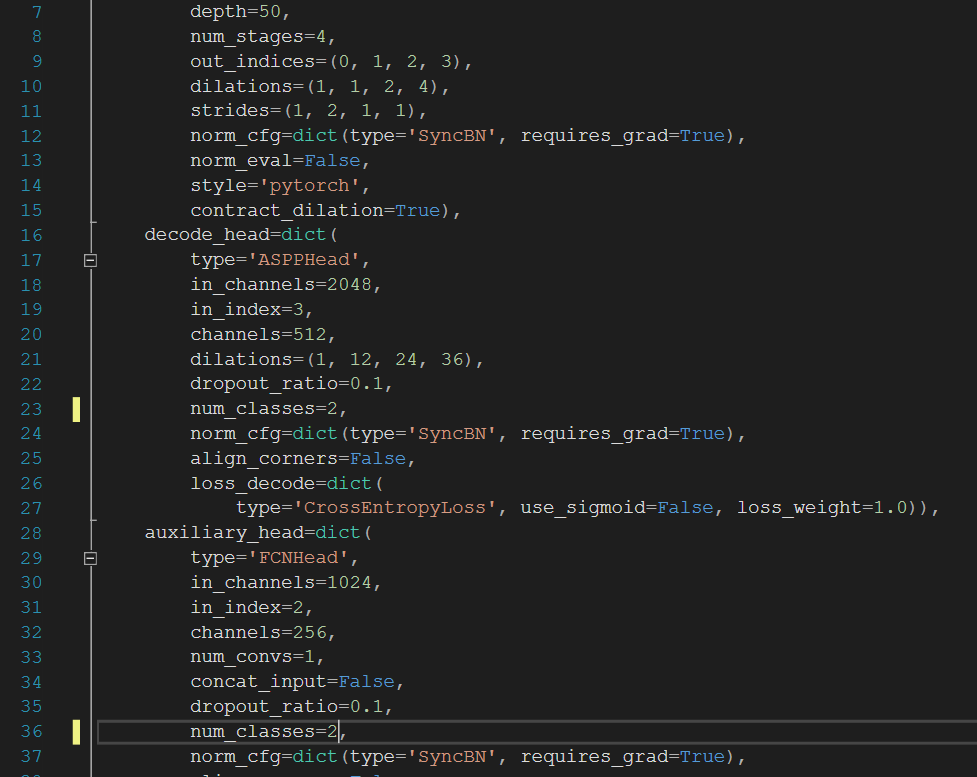
下面开始修改类别,先在配置文件中修改读者需要的类别数,标出的类别改成读者自己的,类别数等于n+1,也就是类别数量+背景。
我们只需要 行驶区域(darea),背景(background)这两类,所以我们的num_classes=2
这里需要修改两处,分别是第23行和第36行。
修改后,还需要修改一些底层配置。
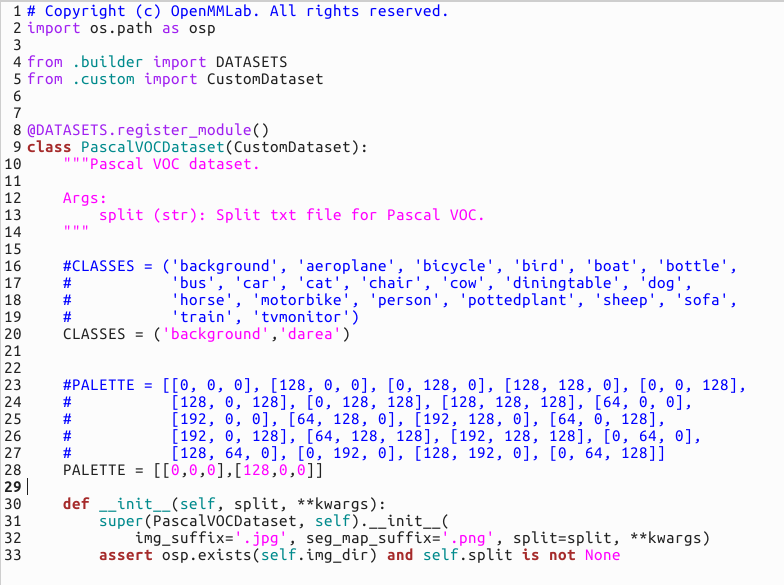
首先是在mmsegmentation/mmseg/datasets下,找到voc.py(因为我们的格式是VOC),做如下修改。
其中PALETTE你可以简单理解为颜色,background对应[0, 0, 0]就是黑色,依次类推。
然后在mmsegmentation/mmseg/core/evaluation下,找到class_names.py,做类似修改:

到这里类别部分就修改好了
3.修改必要的训练配置
这里要修改的地方不多,一般只简单改改训练迭代总数。下面的167行,读者的数据集不大的话,不需要迭代这么多次。

至此,我们的配置文件修改好了。然后我们给修改好的配置文件改个名字。
五、运行
我们再次运行之前的指令:
python tools/train.py segdemo.py
开始训练!!!
训练结束后,模型保存在work_dirs/deeplabv3_r50-d8_512x512_20k_voc12aug/下,
接下来就可以测试我们的模型效果了,在根目录下新建一个python文件,并输入以下代码:
from mmseg.apis import inference_segmentor , init_segmentor
import mmcv
config_file = 'segdemo.py'
checkpoints_file = 'work_dirs/deeplabv3_r50-d8_512x512_20k_voc12aug/latest.pth'
model = init_segmentor(config_file, checkpoints_file, device = 'cuda:0')
img = 'mytest.jpg'
result = inference_segmentor(model, img)
model.show_result(img,result,out_file='none_opacity_result.jpg',opacity=0.5)
保存为testdemo.py,在根目录下打开终端,输入命令:
python testdemo.py
运行后,将自动将结果保存在根目录下,文件名称为none_opacity_result.jpg,这里通过修改11行的out_file和opacity可以修改输出文件名称和输出效果透明度。
当opacity=0.1时,得到结果:

当opacity=0.5时,得到结果:

当opacity=1时,得到结果:

在获取到道路信息后,我们可以开始尝试为无人驾驶汽车指明前进的方向。在实际的工程中,我们采用了强化学习方法来获取无人驾驶汽车前进方向以避免道路两旁行人或障碍物的影响。在本次实例中,我们暂时使用图像处理的方式来初步获取方向信息。对于强化学习方法,感兴趣的读者可以自己尝试实现。
通过以下python程序来对图像进行简单的处理:
import matplotlib.image as mpimg
from pylab import *
img_plt = mpimg.imread('none_opacity_result.jpg')
point_x = [0]*320
point_y = [0]*320
left_flag=0
right_flag=0
left_val=0
right_val=0
i=0
for line in range(180):
for row in range(320):
#print(line,row,img_plt[line,row,0],left_flag,right_flag)
if img_plt[line,row,0] >= 100 and left_flag == 0:
left_flag = 1
left_val = row
if (img_plt[line,row,0] <=50 and left_flag == 1) or(row==319 and img_plt[line,row,0]>=128 and left_flag == 1):
left_flag = 0
right_val = row
right_flag = 1
if right_flag == 1 :
middle = (left_val+right_val)//2
#img_plt[line,middle,1] = 200
point_x[i]=middle
point_y[i]=line
i=i+1
right_flag=0
left_flag = 0
i=i-1
imshow(img_plt)
x = [0,0]
y = [0,0]
x[0] = point_x[0]
x[1]=point_x[i]
y[0]=point_y[0]
y[1]=point_y[i]
plot(x, y, 'r*')
plot(x[:2], y[:2])
show()
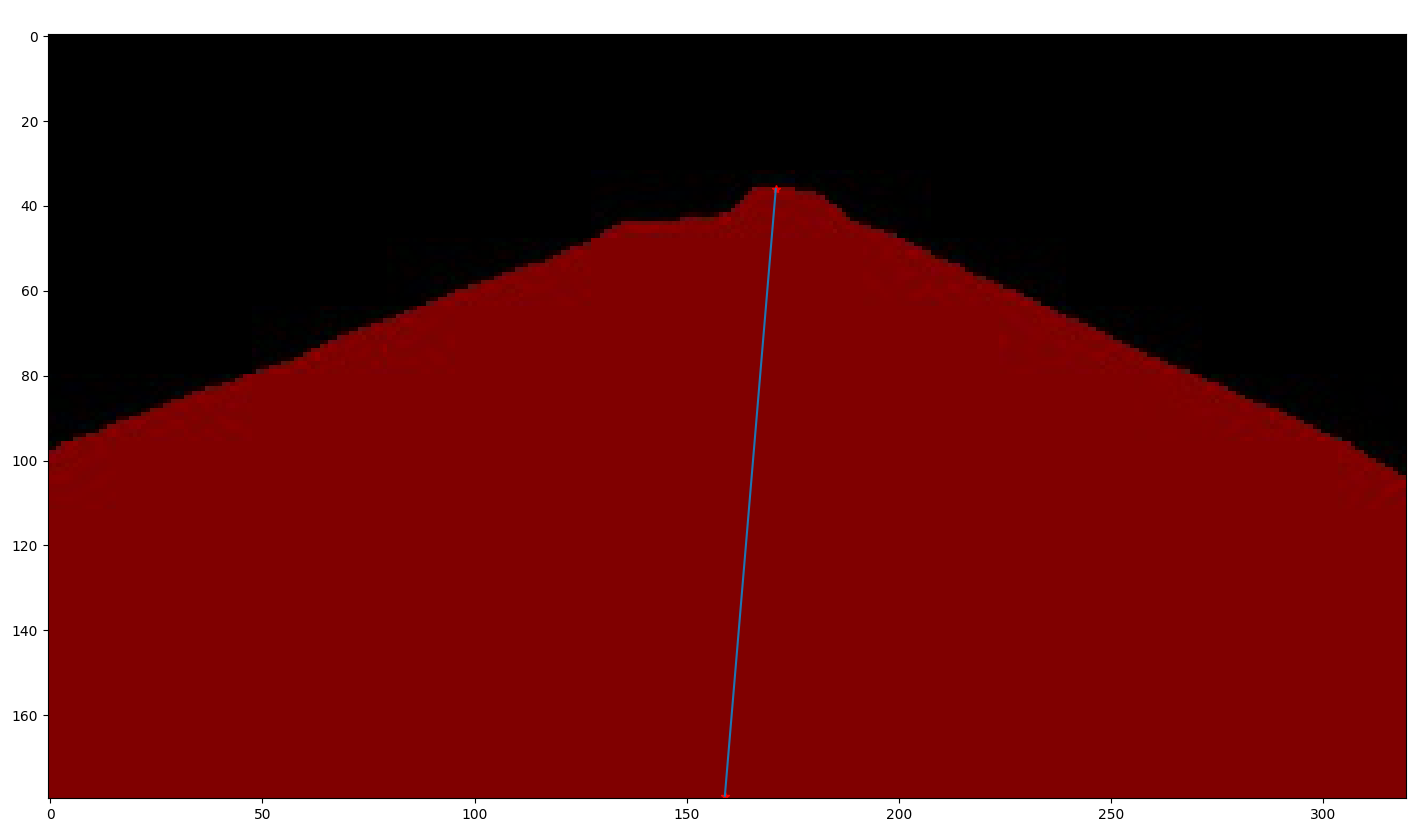
最后输出得到小车前进路径:

使用MMSegmentation进行语义分割
一、前言
本实例将通过使用语义分割,将道路在实际场景中分割出来,从而为无人驾驶小车提供道路信息和前进方向信息。
语义分割作为计算机视觉中一项基础任务,同时在自动驾驶/视频编辑等领域中有重要的应用,因此一直受到学术界和工业界的广泛关注。在近几年的会议中,语义分割的论文层出不穷,但是市面上一直缺乏一款能够相对公平比较各种方法的框架。为了方便研究员和工程师们,MMLab开源了一套基于 PyTorch 实现的标准统一的语义分割框架:MMSegmentation。
https://github.com/open-mmlab/mmsegmentation
在 MMSeg 下,其复现和比较了很多语义分割的算法,并对训练测试的超参进行了优化和统一,在精度,速度,稳定性等方面都超过目前开源的其他代码库。
MMSegmentation
MMSegmentation 保持了 MM 系列一贯的风格,拥有灵活的模块化设计和全面的高性能model zoo。目前支持18种算法,大部分算法都提供了多种 setting 以及在 Cityscapes,ADE20K,Pascal VOC 2012上的训练结果(目前应该是语义分割中最大的 模型库)。
- https://github.com/open-mmlab/mmsegmentation/blob/master/docs/dataset_prepare.md#nighttime-driving)
MMSeg 作为全新的语义分割框架,和其他的框架相比,它提供了更强更快的主流算法,统一超参的公平比较,附带丰富的配置文件和五花八门的 tricks,而且非常灵活易于拓展。
二、制作数据集
使用Labelme来标注自己的数据集:
https://github.com/wkentaro/labelme
https://blog.csdn.net/u014061630/article/details/88756644
1. Labelme介绍
Labelme 是一个图形界面的图像标注软件。用 Python 语言编写的,图形界面使用的是 Qt(PyQt)。
labelme作用:
- 对图像进行多边形,矩形,圆形,多段线,线段,点形式的标注(可用于目标检测,图像分割,等任务)。
- 对图像进行进行 flag 形式的标注(可用于图像分类 和 清理 任务)。
- 视频标注
- 生成 VOC 格式的数据集(for semantic / instance segmentation)
- 生成 COCO 格式的数据集(for instance segmentation)
2.Labelme安装
首先安装Anaconda:
https://www.cnblogs.com/dream-it-possible/p/14301540.html
然后运行以下命令:
##################
## for Python 2 ##
##################
conda create --name=labelme python=2.7
source activate labelme
# conda install -c conda-forge pyside2
conda install pyqt
pip install labelme
# 如果想安装最新版本,请使用下列命令安装:
# pip install git+https://github.com/wkentaro/labelme.git
##################
## for Python 3 ##
##################
conda create --name=labelme python=3.6
source activate labelme
# conda install -c conda-forge pyside2
# conda install pyqt
pip install pyqt5 # pyqt5 can be installed via pip on python3
pip install labelme
使用labelme命令打开标注界面
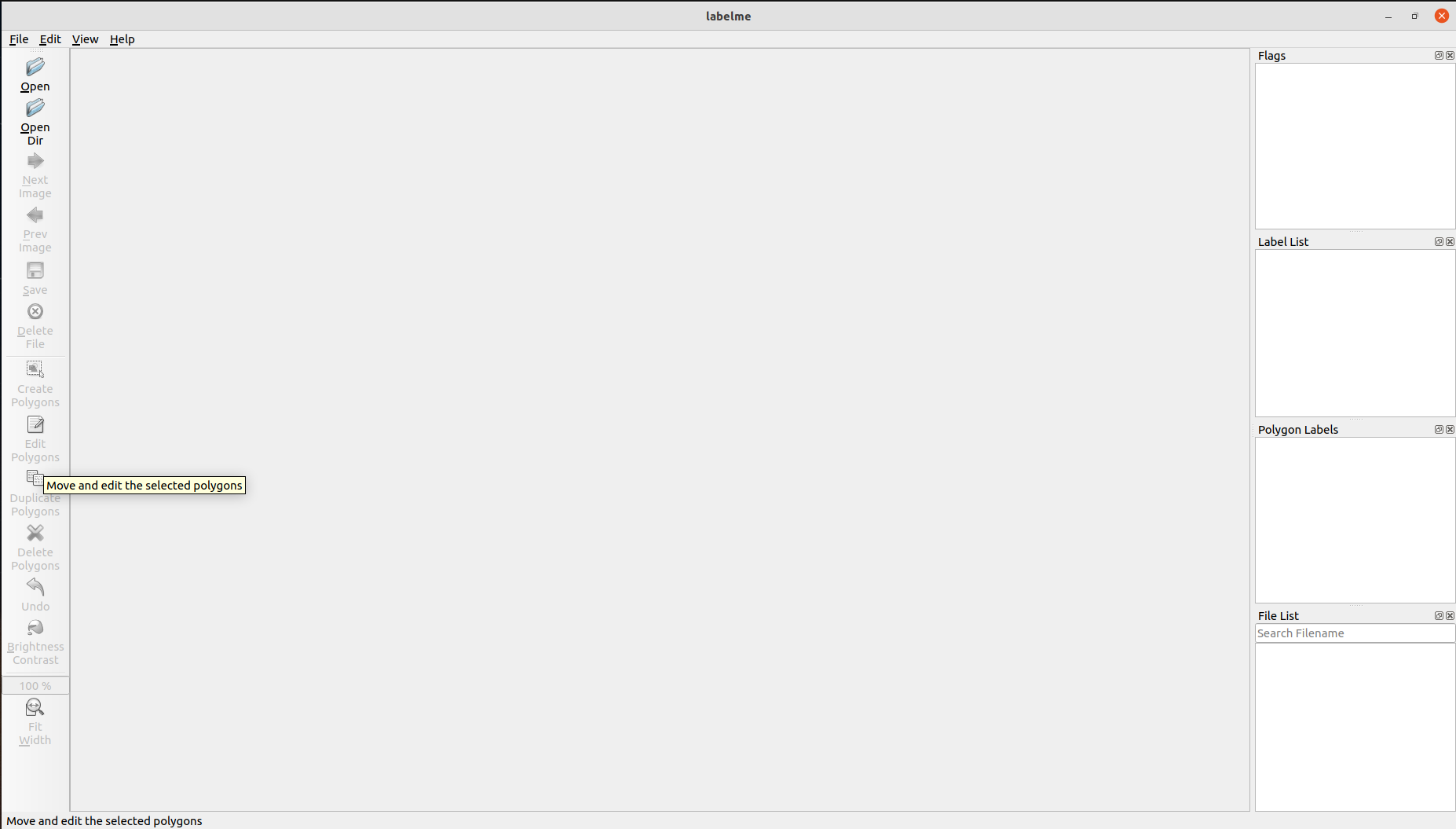
点击Open_Dir打开需要标注的数据集,这里分两类数据集,可行驶区域(darea),背景(background),标注如下图所示。
点击左侧create polygons,依次标定点,使其形成闭合区域,写明所标类别,这里背景可以选择不标注。
标定后保存,会自动生成一个.json的文件,这个.json文件和你的图片放在一起就好。
使用命令
git clone https://github.com/wkentaro/labelme.git
下载labelme支持文件。
但是需要注意的是,mmsegmentation同mmdetection一样,有一些固定的数据集格式。在目标检测中,最为常见的当属COCO和VOC两种格式了。
对于语义分割来说,我们这里按照VOC数据对标注好的数据进行转化。转化方式非常简单,只使用labelme即可。
读者可以在/labelme/examples/semantic_segmentation/下:制作一份labels.txt文件:__ignore__和_background_是要写在最前面的。然后后面依次写上你的类名即可。

运行指令:
python ./labelme2voc.py data_annotated data_dataset_voc --labels labels.txt
其中:
- data_annotated: 是用Labelme标注好的数据文件夹(图片与.json一一对应)。
- data_dataset_voc:是生成的VOC格式的数据集。
得到数据集如下:
其中,JPEGImages是原始图片,SegmentationClass存储的是.npy格式的标注数据。SegmentationClassPNG是标注图片。SegmentationClassVisualization是原图与标注区域的mask格式。
就此数据集准备完毕。
三、环境搭建
1.环境搭建
这里建议使用anaconda安装对应环境
先使用conda创建一个独立的测试环境
conda create --name=mmsegmentation python=3.7.0
conda activate open-mmlab
接下来安装pytorch
首先使用命令查看当前环境的cuda版本:
nvcc -V

可以看到这里cuda版本为11.1,对照自己的cuda和pytorch版本,具体可参考:
https://pytorch.org/get-started/locally/
这里我们安装pytorch1.8.1,使用如下命令:
pip install torch==1.8.0+cu111 torchvision==0.9.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html
注意这里的cu111指cuda版本为11.1,读者需要替换为自己所需的版本
下面安装mmcv库,一定要注意对照自己的cuda和pytorch版本,具体可参考:
https://mmcv.readthedocs.io/en/latest/get_started/installation.html
pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.8.0/index.html
接下来下载mmsegmentation支持文件
pip install git+https://github.com/open-mmlab/mmsegmentation.git # install the master branch
通过以上命令安装mmsegmentation运行必要环境,此外,还需在mmsegmentation根目录下运行以下命令进行补充。
pip install -r requirements.txt
待安装完毕环境即搭建完成。
2.验证环境
为了验证 MMSegmentation 和它所需要的环境是否正确安装,我们可以使用样例 python 代码来初始化一个 segmentor 并推理一张 demo 图像。
from mmseg.apis import inference_segmentor, init_segmentor
import mmcv
config_file = 'configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py'
checkpoint_file = 'checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
# 从一个 config 配置文件和 checkpoint 文件里创建分割模型
model = init_segmentor(config_file, checkpoint_file, device='cuda:0')
# 测试一张样例图片并得到结果
img = 'test.jpg' # 或者 img = mmcv.imread(img), 这将只加载图像一次.
result = inference_segmentor(model, img)
# 在新的窗口里可视化结果
model.show_result(img, result, show=True)
# 或者保存图片文件的可视化结果
# 您可以改变 segmentation map 的不透明度(opacity),在(0, 1]之间。
model.show_result(img, result, out_file='result.jpg', opacity=0.5)
# 测试一个视频并得到分割结果
video = mmcv.VideoReader('video.mp4')
for frame in video:
result = inference_segmentor(model, frame)
model.show_result(frame, result, wait_time=1)
当您完成 MMSegmentation 的安装时,上述代码应该可以成功运行。
此外还可以使用demo脚本可视化单张图片,
python demo/image_demo.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} [--device ${DEVICE_NAME}] [--palette-thr ${PALETTE}]
样例:
python demo/image_demo.py demo/demo.jpg configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth --device cuda:0 --palette cityscapes
推理的 demo 文档可在此查询:demo/inference_demo.ipynb 。
四、配置文件编写与必要的设置
对于mmsegmentation来说,如果读者想快速使用的话。config文件几乎是你唯一需要改动的东西。mmseg的模型使用,训练配置,数据地址都是靠config指明的。
在mmseg的官网中,有关config的资料很清晰,但是细节并不到位。
config是有继承关系的,根文件就是_base_中的一个个文件。虽如此,但仍然不建议初次使用的读者使用官网提供的简略写法。
在mmsegmentation的configs下,存放了各式各样的模型的配置文件,这些配置文件大多数都是针对的大型开源数据集。我们需要改的不是网络结构,主要是你的数据集地址,你定义的类别数,以及必要的训练设置。
这里可以通过运行一遍train来让系统自动生成一个config文件,然后复制出来进行自己的更改,将tools中的train.py复制到mmsegmentation根目录下,并运行以下代码:
python train.py configs/deeplabv3/deeplabv3_r50-d8_512x512_20k_voc12aug.py
运行后报错正常,此时根目录下会生成work_dirs文件夹,并在其中生成我们所需的config文件:

将其拷贝出来,就可以基于此修改我们的配置文件了。
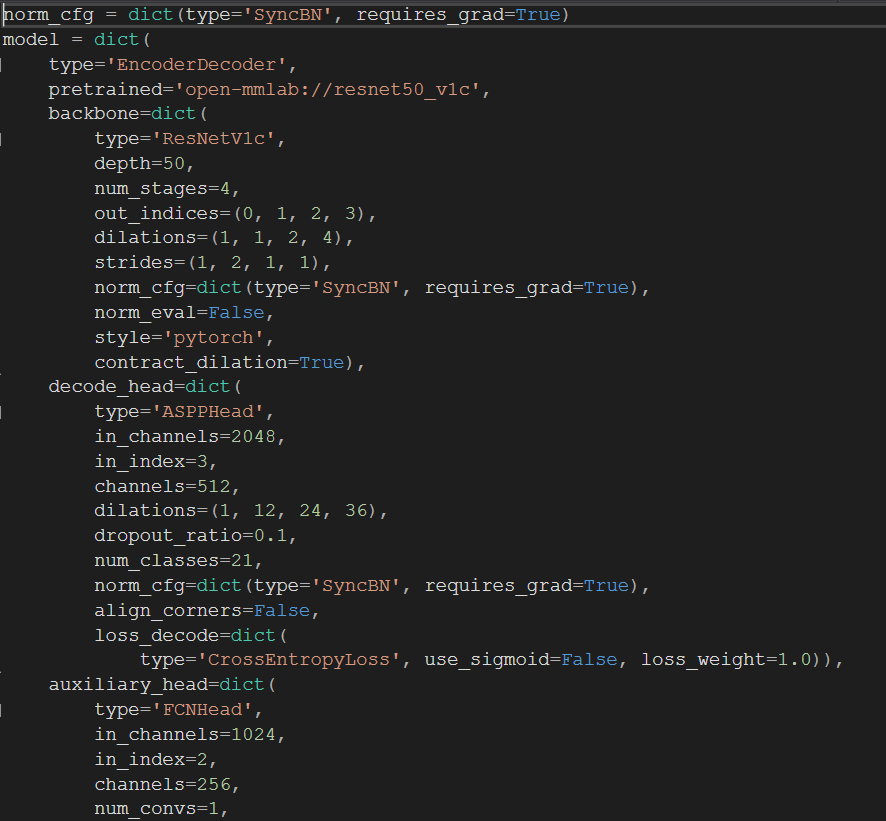
对于config文件,我们只需要关注数据集、类别、训练配置。
整个config文件大致可分为三个部分,即model , data 以及一些训练的配置。
1.数据集地址
我们首先修改训练数据的地址

在config文件的第43行,是我们的数据集要遵照的格式,因为在准备数据集阶段我们已经修改为VOC格式,因此这里不用修改。
第44行是我们数据集的文件目录,这里我将其放入根目录data文件下。
再往下,进入data字典下,我们改动第87行的数据地址。第88行的img_dir是指语义分割数据集的原始图片,我们存到了JPEGImages下;ann_dir存放的是标注文件,我们存放的地址是SegmentationCLassPNG。**注意,原始VOC还进行了数据增强,读者把带有Aug对应的地方删掉即可。**第90行的split对应的是指定哪些图片存放train.txt

同理还需要test.txt 和val.txt,下面我们将制作这三个txt文本。
首先执行以下代码将全部数据图片的名称提取并保存在一个txt文件中
import os
path = "F:\Dataset\data_dataset_voc\JPEGImages"
filenames=os.listdir(os.getcwd())
for name in filenames:
filenames[filenames.index(name)]=name[:-4]
out=open('names.txt','w') #输出的txt文件名称
for name in filenames:
out.write(name+'\n')
out.close()
然后将txt中图片名称随机分为3类,即训练集、测试集和验证集:
import random
num_line = 0
def write_to_txt(file, start, end):
with open(file, 'w') as name:
for i in data[start:end]:
name.write(''.join(i) + "\n")
name.close()
if __name__ == '__main__':
data = []
with open('names.txt', 'r') as f:
for line in f:
data.append(list(line.strip('\n').split(',')))
num_line = num_line + 1
f.close()
print(num_line) #数据集总数
random.shuffle(data)
write_to_txt("train.txt",0,400) #这里需要自己根据自己数据集数量进行分配
write_to_txt("test.txt",400,450)
write_to_txt("val.txt",450,len(data) + 1)
最后修改好的数据集部分代码如下
train部分
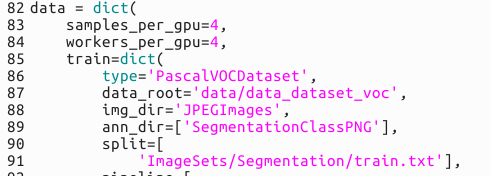
val部分
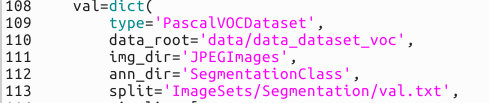
test部分
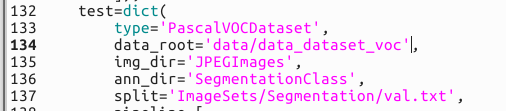
2.类别配置
下面开始修改类别,先在配置文件中修改读者需要的类别数,标出的类别改成读者自己的,类别数等于n+1,也就是类别数量+背景。
我们只需要 行驶区域(darea),背景(background)这两类,所以我们的num_classes=2
这里需要修改两处,分别是第23行和第36行。
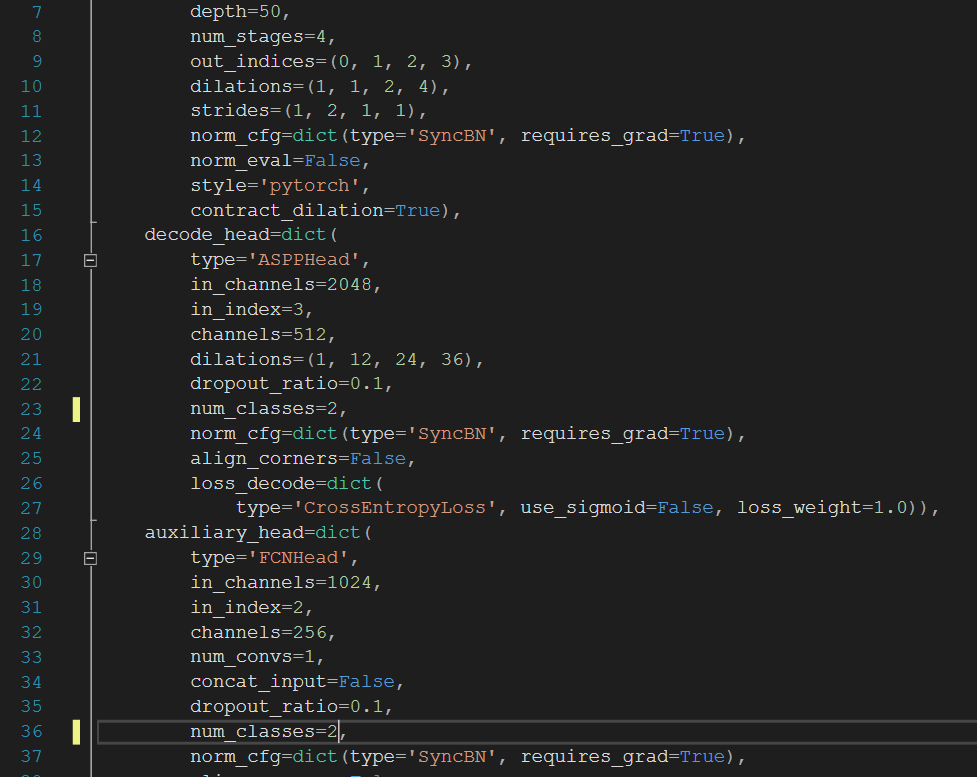
修改后,还需要修改一些底层配置。
首先是在mmsegmentation/mmseg/datasets下,找到voc.py(因为我们的格式是VOC),做如下修改。
其中PALETTE你可以简单理解为颜色,background对应[0, 0, 0]就是黑色,依次类推。
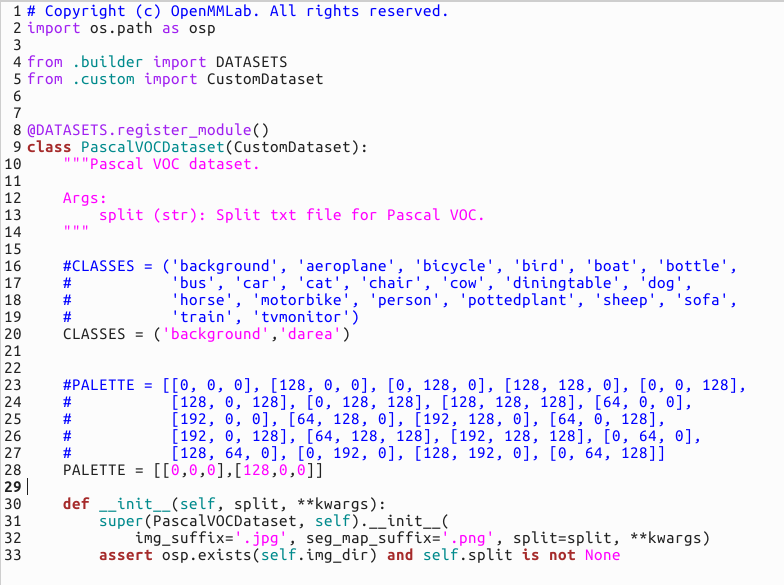
然后在mmsegmentation/mmseg/core/evaluation下,找到class_names.py,做类似修改:

到这里类别部分就修改好了
3.修改必要的训练配置
这里要修改的地方不多,一般只简单改改训练迭代总数。下面的167行,读者的数据集不大的话,不需要迭代这么多次。

至此,我们的配置文件修改好了。然后我们给修改好的配置文件改个名字。
五、运行
我们再次运行之前的指令:
python tools/train.py segdemo.py
开始训练!!!
训练结束后,模型保存在work_dirs/deeplabv3_r50-d8_512x512_20k_voc12aug/下,
接下来就可以测试我们的模型效果了,在根目录下新建一个python文件,并输入以下代码:
from mmseg.apis import inference_segmentor , init_segmentor
import mmcv
config_file = 'segdemo.py'
checkpoints_file = 'work_dirs/deeplabv3_r50-d8_512x512_20k_voc12aug/latest.pth'
model = init_segmentor(config_file, checkpoints_file, device = 'cuda:0')
img = 'mytest.jpg'
result = inference_segmentor(model, img)
model.show_result(img,result,out_file='none_opacity_result.jpg',opacity=0.5)
保存为testdemo.py,在根目录下打开终端,输入命令:
python testdemo.py
运行后,将自动将结果保存在根目录下,文件名称为none_opacity_result.jpg,这里通过修改11行的out_file和opacity可以修改输出文件名称和输出效果透明度。
当opacity=0.1时,得到结果:
当opacity=0.5时,得到结果:
当opacity=1时,得到结果:
在获取到道路信息后,我们可以开始尝试为无人驾驶汽车指明前进的方向。在实际的工程中,我们采用了强化学习方法来获取无人驾驶汽车前进方向以避免道路两旁行人或障碍物的影响。在本次实例中,我们暂时使用图像处理的方式来初步获取方向信息。对于强化学习方法,感兴趣的读者可以自己尝试实现。
通过以下python程序来对图像进行简单的处理:
import matplotlib.image as mpimg
from pylab import *
img_plt = mpimg.imread('none_opacity_result.jpg')
point_x = [0]*320
point_y = [0]*320
left_flag=0
right_flag=0
left_val=0
right_val=0
i=0
for line in range(180):
for row in range(320):
#print(line,row,img_plt[line,row,0],left_flag,right_flag)
if img_plt[line,row,0] >= 100 and left_flag == 0:
left_flag = 1
left_val = row
if (img_plt[line,row,0] <=50 and left_flag == 1) or(row==319 and img_plt[line,row,0]>=128 and left_flag == 1):
left_flag = 0
right_val = row
right_flag = 1
if right_flag == 1 :
middle = (left_val+right_val)//2
#img_plt[line,middle,1] = 200
point_x[i]=middle
point_y[i]=line
i=i+1
right_flag=0
left_flag = 0
i=i-1
imshow(img_plt)
x = [0,0]
y = [0,0]
x[0] = point_x[0]
x[1]=point_x[i]
y[0]=point_y[0]
y[1]=point_y[i]
plot(x, y, 'r*')
plot(x[:2], y[:2])
show()
最后输出得到小车前进路径:















 2053
2053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









