







系列文章目录
文章目录
【nnUNetV2系列】一、nnUNetV2安装、训练和推理
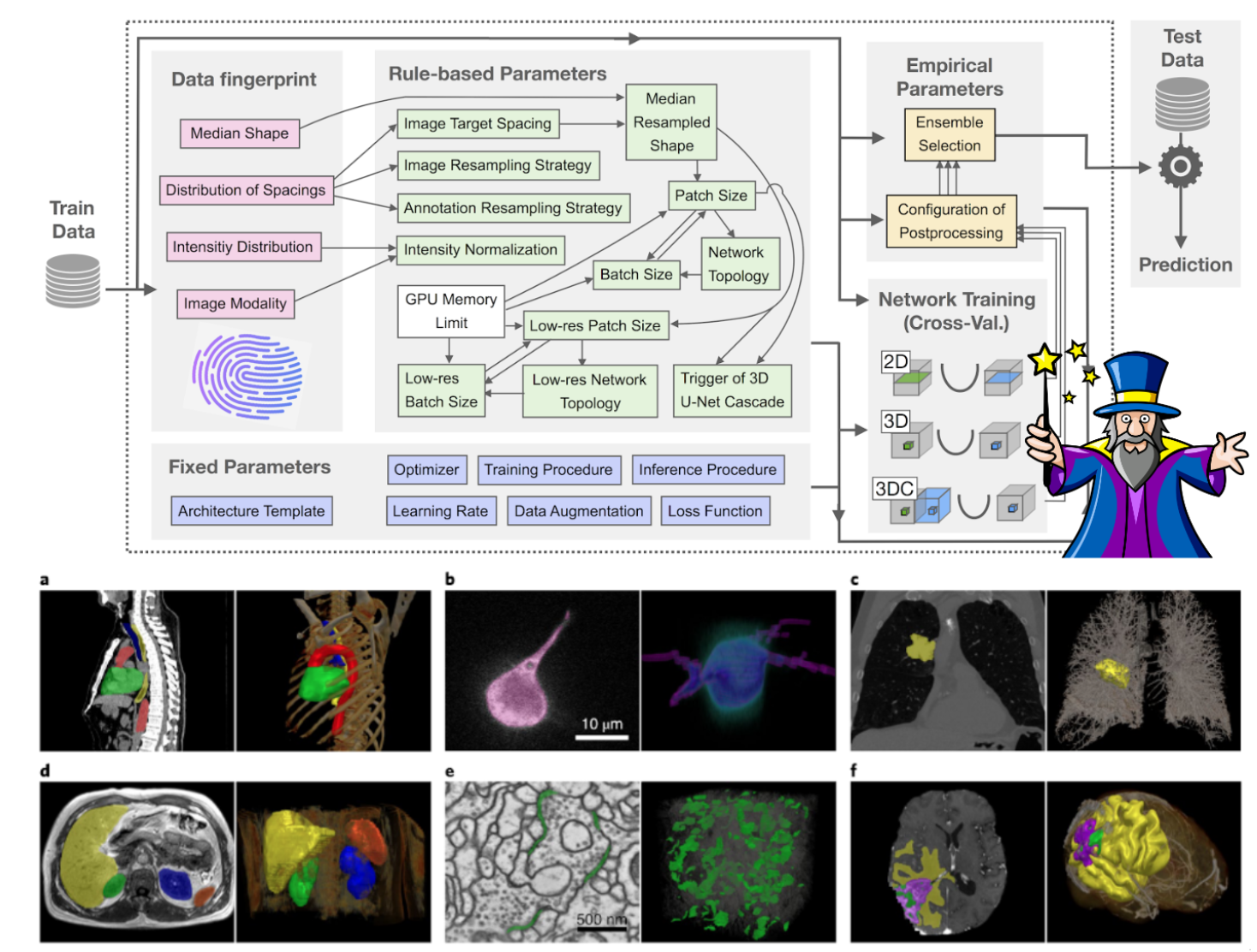
创建虚拟环境
这里推荐使用conda创建虚拟环境,conda可以方便地管理python环境和依赖包。若本地未安装conda,请先安装conda。 可参考conda安装教程。
conda create -n nnunet2 python=3.9
官方推荐使用python3.9或更新版本,版本过低可能会出现兼容性问题。推荐使用3.9以上版本。
安装nnUNetV2的依赖
1、进入虚拟环境
conda activate nnunet2
安装GPU版本的Pytorch,推荐使用GPU进行nnUNet的训练和推理,可以显著提高效率。先看看显卡驱动支持的最大CUDA版本,在命令行输入NVIDIA-smi,查看CUDA版本。若没有显卡驱动,请先安装显卡驱动。如下图,我的显卡驱动最高支持CUDA 12.2。
nvidia-smi
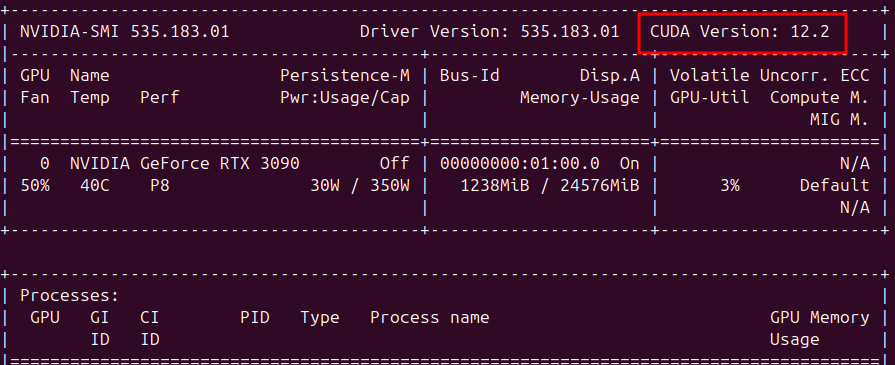
2、安装Pytorch
torch官方网站提供了不同版本的Pytorch,根据CUDA版本选择对应的Pytorch版本。我这里选择的是Pytorch 2.1.0,CUDA 12.1。若没有显卡驱动,请选择CPU版本的Pytorch。推荐使用pip安装,pip使用阿里源下载速度更快。
# conda
conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=12.1 -c pytorch -c nvidia
# pip
pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu121
安装nnUNetV2
安装nnUNetV2可以使用本地安装或者使用pip在线安装nnUNetV2,本地安装更合适需要对模型结构进行修改,使用nnUNetV2框架做二次开发的用户。若仅需要使用使用nnUNetV2当做分割实验的baseline,使用pip在线安装更方便。
1、本地安装
git clone https://github.com/MIC-DKFZ/nnUNet.git
cd nnUNet
pip install -e .
本地安装之后输入pip list命令,可以看到nnUNetV2已经成功通过本地安装。
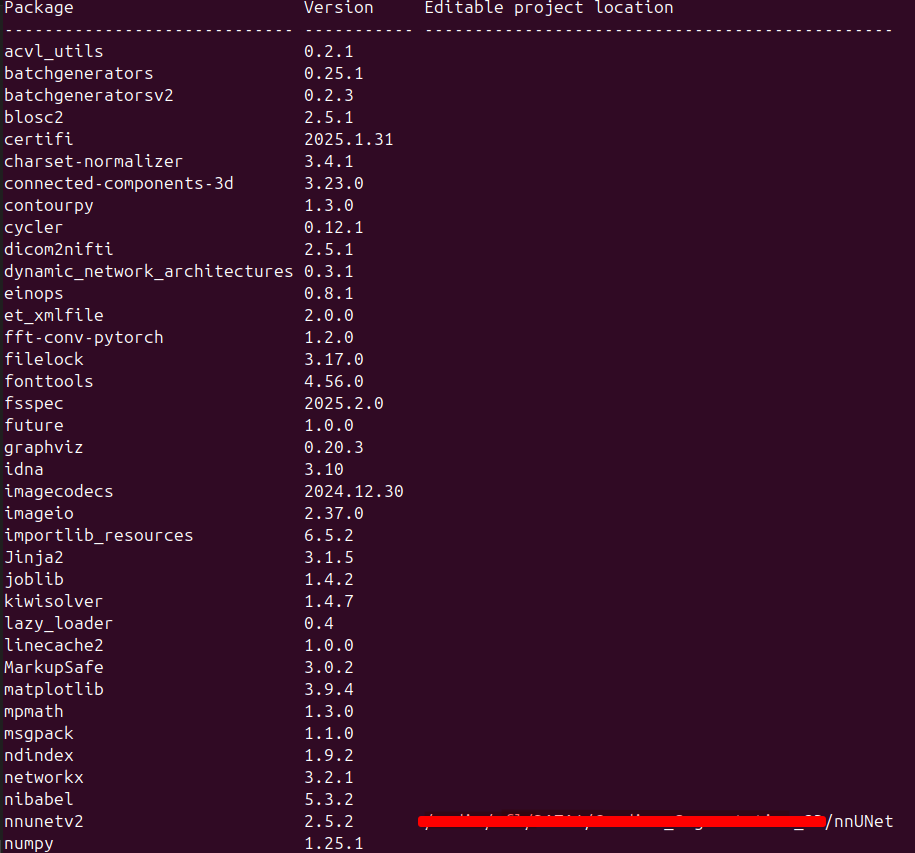
2、在线安装
pip install nnunet
设置环境变量
nnUNetV2是一个高度集成的自动化框架,需要设置一些环境变量来指定数据集的路径、模型保存路径等。有两种方式设置环境变量,一种是在命令行中临时设置,另一种是在bashrc文件中永久设置。推荐使用第二种方式,方便后续使用。
1、临时设置环境变量
export nnUNet_raw="/home/nnUNet/raw_data_base"
export nnUNet_preprocessed="/home/nnUNet/preprocessed"
export nnUNet_results="/home/nnUNet/results"
2、永久设置环境变量
echo "export nnUNet_raw=\"/home/nnUNet/raw_data_base\"" >> ~/.bashrc
echo "export nnUNet_preprocessed=\"/home/nnUNet/preprocessed\"" >> ~/.bashrc
echo "export nnUNet_results=\"/home/nnUNet/results\"" >> ~/.bashrc
source ~/.bashrc
或者打开~/.bashrc文件,在文件末尾添加以下内容,保存并退出。
export nnUNet_raw="/home/nnUNet/raw_data_base"
export nnUNet_preprocessed="/home/nnUNet/preprocessed"
export nnUNet_results="/home/nnUNet/results"
这里nnUNet_raw是原始数据集的路径,nnUNet_preprocessed是预处理后的数据集的路径,nnUNet_results是训练好的模型的路径。根据实际情况修改路径。
数据预处理
nnUNetV2框架对数据的预处理是自动化的,只需要将数据集按照指定格式放置在nnUNet_raw目录下,然后运行预处理脚本即可。nnUNetV2支持多种数据集,包括医学影像、遥感影像等。nnUNetV2的数据集格式如下:
nnUNet_raw
└───Taskxxx_Liver
├───imagesTr
├───imagesTs
├───labelsTr
└───labelsTs
xxx是任务编号,Liver是任务名称,imagesTr是训练集的图像,imagesTs是测试集的图像,labelsTr是训练集的标签,labelsTs是测试集的标签。nnUNetV2支持多种数据集格式,包括nii、nii.gz、dcm等。nnUNetV2的数据预处理脚本如下:
nnUNetv2_plan_and_preprocess -d xxx --verify_dataset_integrity
处理完成后的数据集会保存在nnUNet_preprocessed目录下,格式如下:
nnUNet_preprocessed
└───Taskxxx_Liver
├───gt_segmentations
├───nnUNetPlans_2d
├───nnUNetPlans_3d_fullres
├───nnUNetPlans_3d_lowres
├───dataset.json
├───dataset_fingerprint.json
├───nnUNetPlans.json
└───splits_final.json
预处理会默认将训练集按照五折交叉验证的方式划分到splits_final.json文件中,方便后续训练和评估。
训练模型
nnUNetV2训练模型的方式非常简单,只需要指定任务编号和训练策略即可。nnUNetV2支持多种训练策略,包括2d,3d_fullres,3d_lowres等。nnUNetV2的训练脚本如下:
nnUNetv2_train xxx 3d_fullres 0
其中xxx是任务编号,0是数据划分(五折划分的数据可以选择0,1,2,3,4),3d_fullres是训练策略名称。训练完成后,训练好的模型会保存在nnUNet_results目录下。
推理
推理可以使用nnUNetV2的predict脚本,指定任务编号和训练策略即可。推理脚本如下:
nnUNetv2_predict -i input_folder -o output_folder -d xxx -c config_name -f fold_num
其中input_folder是输入图像的路径,output_folder是输出结果的路径,xxx是任务编号,config_name是训练策略名称。推理完成后,输出结果会保存在output_folder目录下, fold_num是五折交叉验证中的编号。

















 4174
4174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









