







目录
2.用户长序列模型 Long-term User Interest
2.GSU General Search Unit 通用搜索单元
3.ESU Exact Search Unit 精确搜索单元
六.在线服务的实现 IMPLEMENTATION FOR ONLINE SERVING
1.在线服务的挑战 Challenges of Online Serving with Lifelong User Behavior Data
2.基于搜索的在线服务系统兴趣模型 Search-based Interest Model for Online Serving System
4.模型比较 Results on Public Datasets
6.工业数据集结果 Results on Industrial Dataset
一.引言
SIM 在 DIN、DIEN 的基础上,引入用户更长周期更多的行为信息,便于模型更好的理解用户的多样性兴趣,同时引入的用户长期兴趣也避免了以往模型用户兴趣受短期兴趣主导的现象。下面对论文做简要回顾。
二.摘要 Abstract
丰富的用户行为数据已经被证实在推荐系统与在线广告应用中对点击率预估任务具有巨大价值,业界和学术界都很关注该话题并提出不同的方法对用户长序列行为数据建模。先前阿里巴巴提出 MIMN 记忆网络模型,通过学习算法和服务系统的协同设计,使得 MIMN 成为第一个可以将用户行为序列长度扩展到 1000 的数据建模的工业解决方案。然而,随着用户序列的进一步增加,例如增加 10 倍甚至更多时,MIMN 无法精确捕获给定的候选项的用户兴趣。该挑战广泛存在于先前提出的建模方法中。
论文引入一种新的建模范式解决该问题,且将其命名为基于搜索的兴趣模型 (SIM)。SIM通过两个级联搜索单元提取用户兴趣:
• 通用搜索单元 (General search Unit, GSU)
从原始的任意长顺序行为数据中进行通用搜索,结合候选项的查询信息,得到与候选项相关的子用户行为序列 (Sub user behavior Sequence, SBS);
• 精确搜索单元 (Exact Search Unit, ESU)
模拟候选项目与 SBS 之间的精确关系。
GSU 和 ESU 这种级联搜索范例使 SIM 能够在可伸缩性和准确性方面更好地为终身顺序行为数据建模,这也是论文的主要成果所在:
自2019年以来,SIM 已部署在阿里巴巴的展示广告系统中并服务于主流量,带来了 7.1% 的点击率和 4.4% 的 RPM 提升,其中序列最大长度可达 54000。
三.介绍 INTRODUCTION
1.用户序列长度与建模
点击率 (CTR) 预测模型在推荐系统和在线广告等工业应用中起着至关重要的作用,这一点我们在 DIN 论文概述一文中也做了公式的分析。用户历史行为的快速增长使得用户兴趣建模侧重于学习用户兴趣的意图表示,例如 YoutubeDNN、MIMN、DIN、DIEN 等,由于在线计算与存储负担的限制,这些方法只能对长度在数百的用户序列行为上建模,在一定程度上影响了用户兴趣的表征。
电子商务网站淘宝内 23% 的用户在最近 5 个月内点击超过 1000 个产品,因此如何构造一个可行的对长序列用户建模的方法也一直受到业界与学术界关注。
2.MIMN 记忆网络
借鉴自然语言处理领域的思想,提出用记忆网络对长序列用户行为数据进行建模,并取得了一定的突破。阿里巴巴提出的 MIMN 就是一个典型的作品,它通过学习算法和服务系统的协同设计实现了序列建模。MIMN 是第一个可以对长度扩展到1000的连续用户行为数据进行建模的工业解决方案。具体来说,MIMN 是将一个用户的不同兴趣逐渐嵌入到一个固定大小的内存矩阵中,该矩阵将根据每个新行为进行更新。这样,用户建模的计算就与点击率预测解耦了。对于在线服务,延迟将不是问题,存储成本取决于内存矩阵的大小,这比原始行为序列要小得多。
然而,基于内存网络的方法对任意长序列数据建模仍然是一个挑战。实际上,我们发现当用户行为序列的长度进一步增加,例如增加到 10000 或更多时,MIMN 不能精确地捕捉给定特定候选项目的用户兴趣。这是因为将所有用户历史行为编码到固定大小的内存矩阵中会导致大量噪声包含在内存单元中。
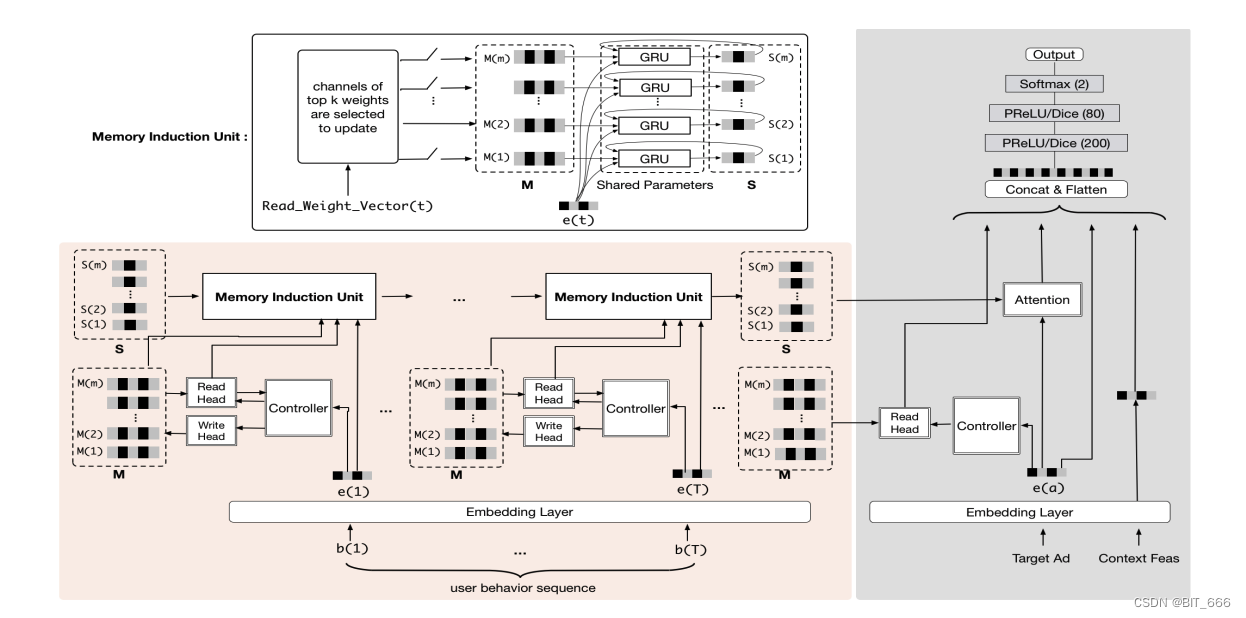
上图为 MIMN 模型的网络架构,其主要由两部分组成:
• 左侧子网络
该网络专注于具有顺序行为特征的用户兴趣建模
• 右侧子网络
右侧子网络遵循传统的 Embedding 和 MLP 范式,以左子网络和其他特征的输出作为输入。
MIMN 的贡献主要位于左侧子网络中,该子网络由 NTM 模型驱动,包含两个重要的内存架构:
- 具有存储器读取和存储器写入的标准操作的基本 NTM 存储器单元。
- 具有多通道 GRU 的存储器诱导单元,用于基于先前学习的 NTM 存储器来捕获高阶信息。
3.长序列用户信息提取
DIN 的思想是面对不同的候选 Item,一个用户的兴趣是多种多样的,这时候需要获取每个历史 Good 与当前 Item 的关联信息即激活权重,从而从行为中搜索到有效信息。但是,面对前面所提到的长序列用户行为数据,DIN 的搜索公式所耗费的计算量和存储量是无法接受的,这需要一种更有效的方法来从长顺序的用户行为数据中提取知识。
SIM 沿用了 DIN 的思想,只捕获与特定候选项目相关的用户兴趣,但无需像 DIN 一样进行大量的计算,其通过两个级联搜索单元实现。其中 GSU 通用搜索单元负责从长序列中得到与候选集 Item 相关的子用户行为序列 SBS。论文中表示 SBS 的长度可以减少到数百,从而过滤掉原始长序列行为中大部门噪声信息,例如用户兴趣建模与表征。ESU 精确搜索单元则模拟候选项目与 SBS 之间的精确关系。由于 GSU 将原始可能高达万记的长序列缩短为百记的 SBS,所以在 ESU 精确搜索时可以很容易的应用 DIN 或者 DIEN。
与 MIMN 类似,本文的主要贡献也在于模型示意图的左侧:
- 级联两阶段设计使得 SIM 在长序列行为建模时拥有更好的可扩展性与准确性
- SIM 能够应用于大规模工业系统,并带来明显的点击率与 RPM 提升,RPM 即千次展示收入
- SIM 将用户长序列建模的长度提高到 54000,是 MIMN 的 54 倍
四.近期工作 RELATED WORD
1.用户兴趣模型 User Interest Model
Wide&Deep、DeepCross、Deepintent 基于深度学习在 CTR 预测任务中取得很大成功。在早期,大多数模型主要使用深度神经网络来捕获不同 Filed 之间的相互作用即特征交叉与特征组合,以便工程师摆脱枯燥的特征工程工作。最近也新提出一系列 User Interest Model,其利用 CNN、RNN、Transformer 等不同网络架构从用户历史行为中学习用户潜在兴趣表示。DIN 引入了 Attention 机制,DIEN 引入了时间信息用来描述用户兴趣的转移概率,MIND 引入胶囊网络与动态路由学习用户兴趣的多向量表示代替前面方法的单用户向量。
2.用户长序列模型 Long-term User Interest
考虑用户历史行为长序列可以显著提高 CTR 模型性能,但是这会极大的增加在线服务系统的延迟和存储负担,同时也会引入更多噪声与脏数据。《Lifelong Sequential Modeling with Personalized Memorization for User Response Prediction》提出了分层周期记忆网络,实现框架不再基于Memory Network 框架,而是使用了多层 GRU,用于终身序列建模,为每个用户构建个性化序列模式。《Adaptive user modeling with long and short-term preferences for personalized recommendation》选择一个基于注意力的框架来结合用户的长期和短期偏好。《Practice on Long Sequential User Behavior Modeling for Click-through Rate Prediction》提出了一种基于内存的MIMN架构,将用户的长期兴趣嵌入到固定大小的内存网络中,以解决用户行为数据的大量存储问题。并设计了一个UIC模块,增量记录新用户的行为,以应对延迟限制。但 MIMN 放弃了记忆网络中 Target Item 的信息,而这些信息对用户兴趣建模非常重要。
五.SIM 搜索兴趣网络
基于 Attention 的 CTR 模型例如 DIN、DIEN 设计了复杂的模型结构,通过从用户行为序列软搜索有效知识建模从而捕获用户对不同候选 Item 的兴趣,但现实系统中只能处理短期行为序列,通常长度为 150。另一方面,用户的长期行为数据是有价值,将用户的长期行为序列也引入建模已经被证实对 CTR 有正向作用。为了解决二者的矛盾,论文提出了新的建模范式,即基于搜索的兴趣模型-SIM。SIM 遵循两段式搜索策略,有效处理长用户序列。
1.整体流程 Overall Workflow
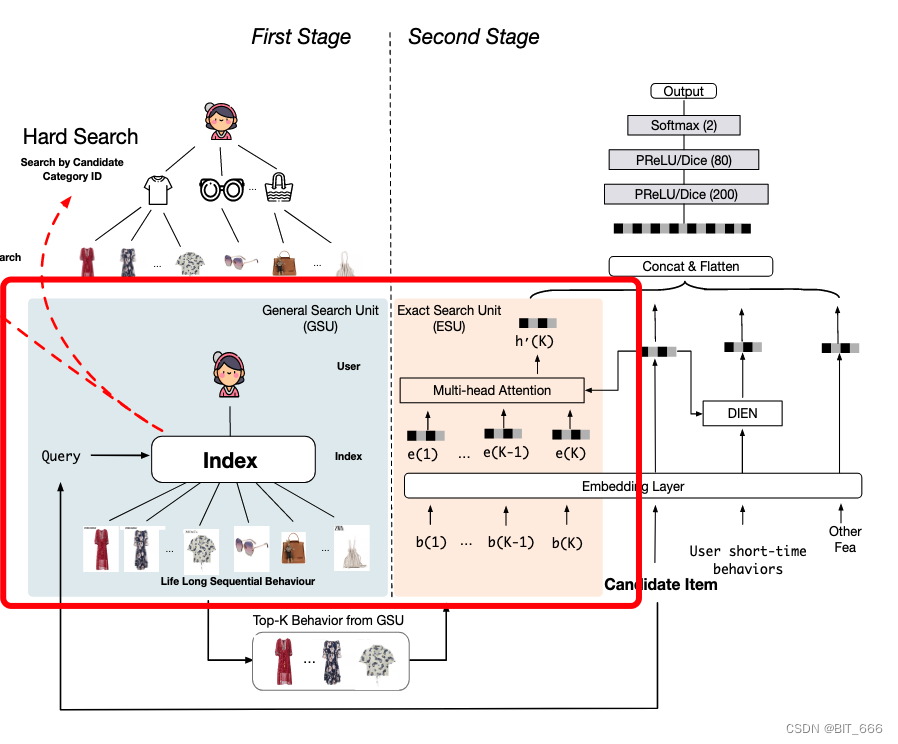
SIM 遵循两阶段搜索策略,有两个响应的单元:一般搜索单元 GSU 与精确搜索单元 ESU。
• 第一阶段
利用通用搜索单元 GSU 从具有亚线性时间复杂度的原始长期行为序列中寻找 top-K 相关子行为序列 SBS。这里的 K 通常比行为序列的原始长度短得多。在时间和计算资源的限制下,能够搜索到相关的行为,是一种高效的搜索方法。GSU 采用一种通用但有效的策略来截断原始顺序行为的长度,以满足时间和计算资源的严格限制。同时,长期用户行为序列中存在的大量噪声可能会破坏用户兴趣建模,这些噪声可以在第一阶段被搜索策略过滤掉。
• 第二阶段
引入精确搜索单元 ESU,将过滤后的次顺序用户行为作为输入,进一步捕获精确的用户兴趣。由于长期行为的长度已减少到数百个,因此可以应用具有复杂结构的复杂模型,如 DIN 和 DIEN。
Tips:
请注意,尽管分别介绍了这两个阶段,但实际上它们是一起训练的。
2.GSU General Search Unit 通用搜索单元
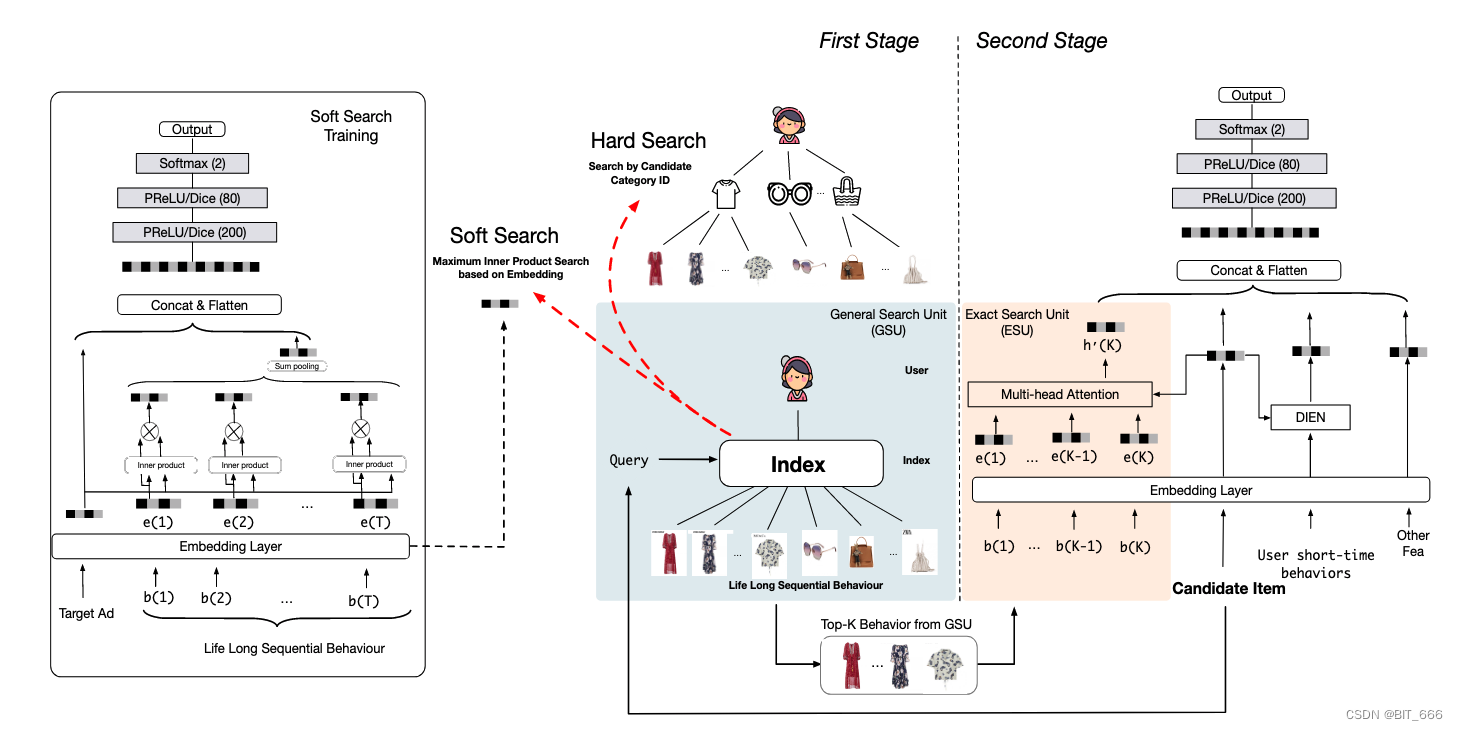
给定一个候选 Item,只有一部分用户行为是有价值的。挑选出相关的用户行为有助于用户兴趣建模,然而,使用整个用户行为序列直接建模用户兴趣会带来巨大的资源占用和响应延迟,这在实际应用中通常是不可接受的。为此提出了一种通用搜索单元,以减少用户兴趣建模中用户行为的输入数量。这里介绍两种通用的搜索单元:硬搜索 Hard Search 与 软搜索 Soft Search。给定用户行为列表 B = [b1、b2、...、bT],i 代表第几个用户行为,T 代表用户行为长度。GSU 计算每个行为与候选 Item 的相关分数 Ri,选择分数 Ri 的 Top-K 相关行为子序列 SBS。硬搜索与软搜索公式如下:
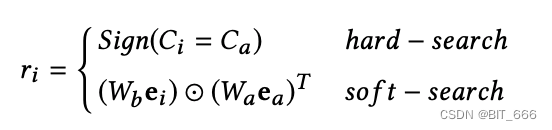
• 硬搜索 Hard Search
硬搜索模型是非参数的。只有与候选项目属于同一类别 cate 的行为才会被选择并聚合为子行为序列,以发送到精确的搜索单元。其中 Ca 和 Ci 表示目标项目的类别和对应的第 i 个行为 bi。硬搜索很简单,但它非常适合在线服务。这里可以理解为针对每个用户 uid 构造一个 KKV 的数据结构,K-uid K-cate V-goods,只需要根据 uid 和候选集 Item 对应 cate 就可以从 KKV 数据结构中拿到用户历史行为中对应的 V。
• 软搜索 Soft Search
在软搜索模型中,bt 首先被编码为 one-hot 向量,然后嵌入到低维向量中 se = [e1、e2、...、eT]:
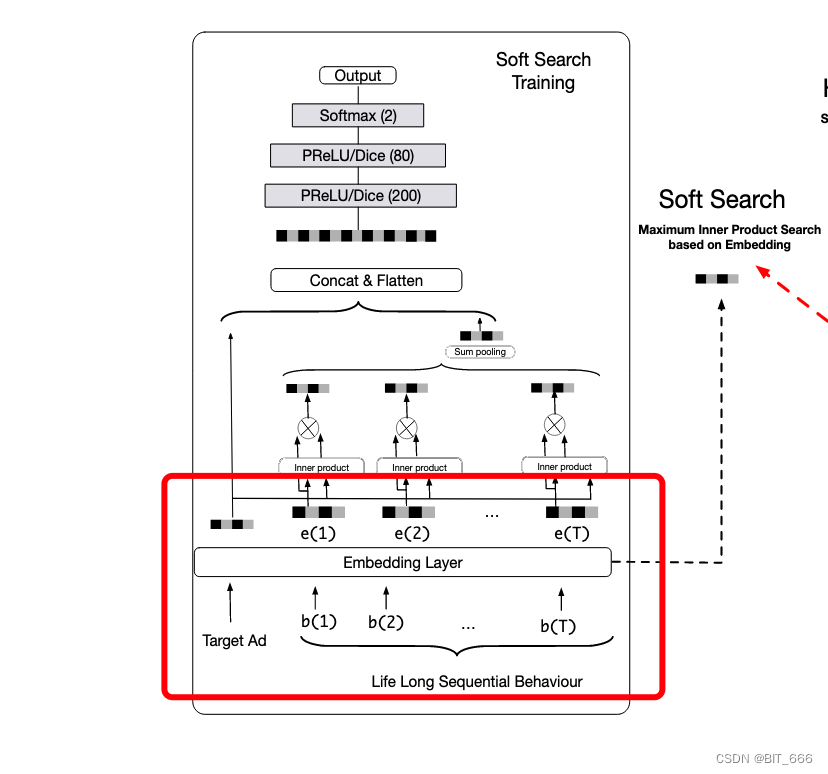
Wb 和 Wa 为权重参数。ea 和 ei 分别表示目标项目的嵌入向量和第 i 个行为 bi。为了进一步加快万长度用户行为 Top-K 搜索速度,基于嵌入向量 E,采用亚线性时间最大内积搜索方法 ALSH,搜索与目标项相关的 Top-K 行为。通过训练有素的嵌入和最大内积搜索 MIPS 方法,可以将上万个以上的用户行为减少到数百个。
需要注意的是,长期数据和短期数据的分布是不同的。因此,在软搜索模型中直接使用从短期用户兴趣建模中学到的参数可能会误导长期用户兴趣建模。所以模型中长期行为侧的 Soft Search 对应的 Embedding Layer 与短期行为侧的 DIN / DIEN 的 Embedding Layer 不是同一个。
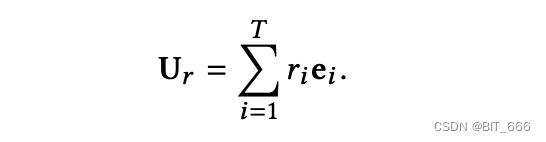
论文在基于长期行为数据的辅助 CTR 预测任务下对软搜索模型的参数进行训练,行为表示 Ur 由 ri和 ei 相乘得到,然后将行为表示 Ur 和目标向量 ea 连接起来,作为后续 MLP 多层感知的输入。最后基于 Embedding Layer 与内积公式,取分数最高的 Top-K 作为后续模型子集。
Tips:
如果用户行为增长到一定程度,则不可能直接将整个用户行为馈送到模型中。在这种情况下,可以从长序列用户行为中随机抽取子序列集,这些子序列集仍然遵循原始用户行为的相同分布。读者猜想这种情况主要发生在一些极端异常的样本上,例如某些过度活跃用户或异常用户。
3.ESU Exact Search Unit 精确搜索单元
在第一个搜索阶段,Top-K 相关子用户行为序列 B* w.r.t. 从长期用户行为中选择目标项目。为了从相关行为中进一步建模用户兴趣,我们引入了精确搜索单元,这是一个以 B* 为输入的基于注意力的模型。
考虑到这些被选择的用户行为跨越了很长一段时间,因此用户行为的贡献是不同的,我们涉及到每个行为的序列时间属性。其中时间间隔 D = [∆1、∆2、…、∆K] 表示目标项目与选定的 K个用户行为之间的时间距离信息。B* 和 D 被编码为嵌入E* = [e*1、e*2、…、e*K] 和 Et = [et1、et2、…、etK]。E*j 和 Etj 被连接起来作为用户行为的最终表示,表示为 zj = concat(e*j, etj)。
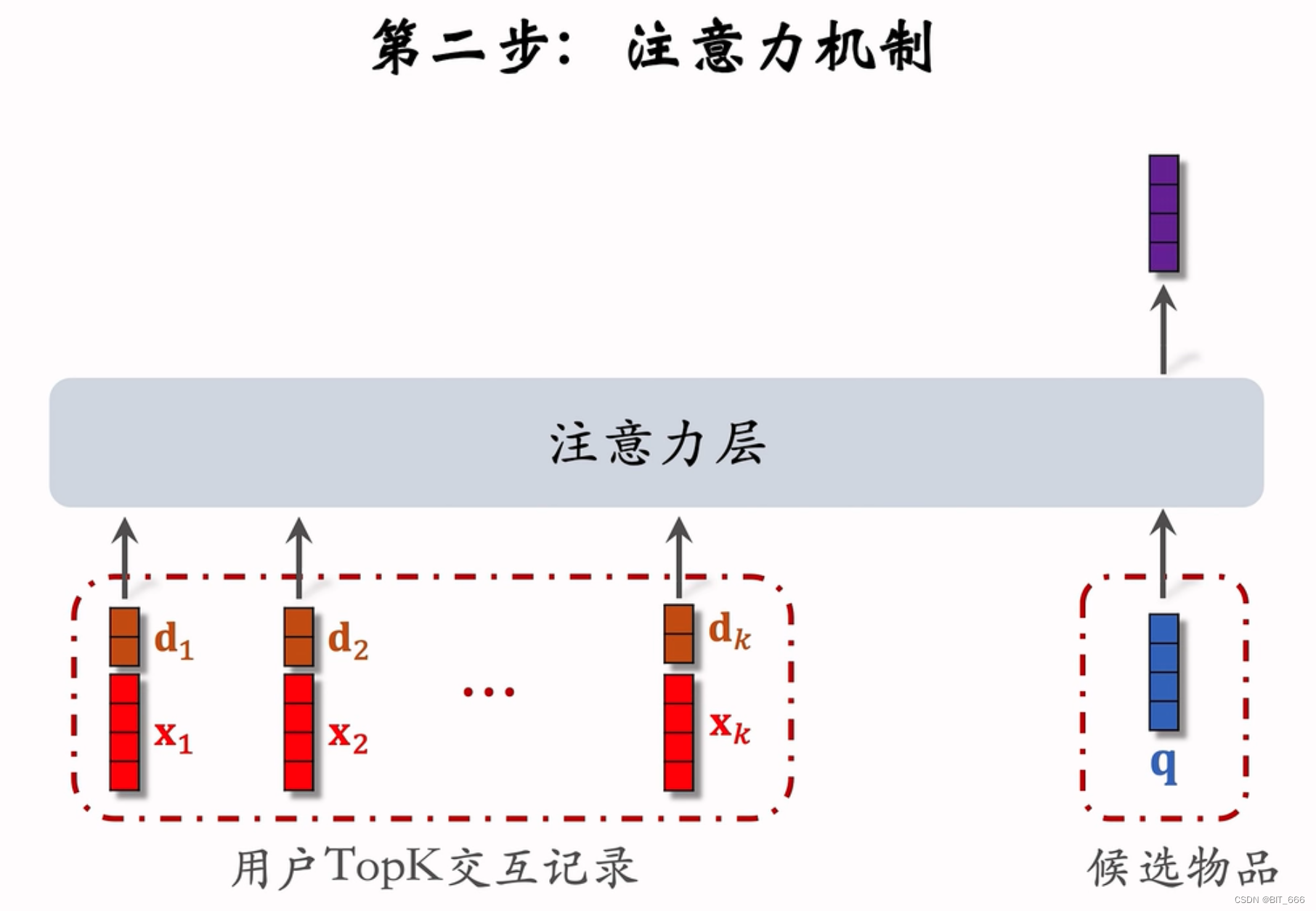
这里相当于在 DIN 的注意力层的 Input 处扩充了用户的行为序列向量,原始用户 good 维度为 K、时间信息维度为 T、则将二者 Concat 为 K+T 的向量送入注意力层,候选 Item q 的向量依然为 K 维。
论文中利用 Multi-Head Attention 来捕捉不同的用户兴趣:
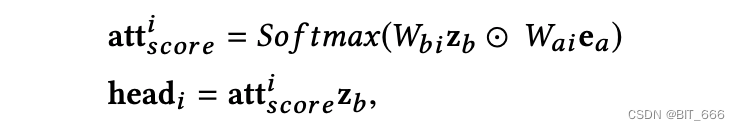
其中 att 是第 i 个注意力得分,head 是多头注意中的第 i 个注意力得分。Wbi 和 Wai 是权重的第 i 个参数。最终用户长期不同的兴趣被表示为:
![]()
然后将其输入 MLP 进行 CTR 预测。最后,在交叉熵损失函数下同时训练一般搜索单元和精确搜索单元。其中 α 和 β 是控制损失权值的超参数。在我们的实验中,如果 GSU 使用软搜索模型,α 和 β 都被设置为1,如果使用硬搜索模型,其 GSU 是非参数的,只需构建 KKV 数据库即可,此时 α 设为 0。
![]()
六.在线服务的实现 IMPLEMENTATION FOR ONLINE SERVING
下面介绍 SIM 在阿里巴巴在线系统的实践经验。
1.在线服务的挑战 Challenges of Online Serving with Lifelong User Behavior Data
工业推荐或广告系统需要在一秒钟内处理大量的流量请求,这需要 CTR 模型实时响应。通常服务延迟应该小于30毫秒。
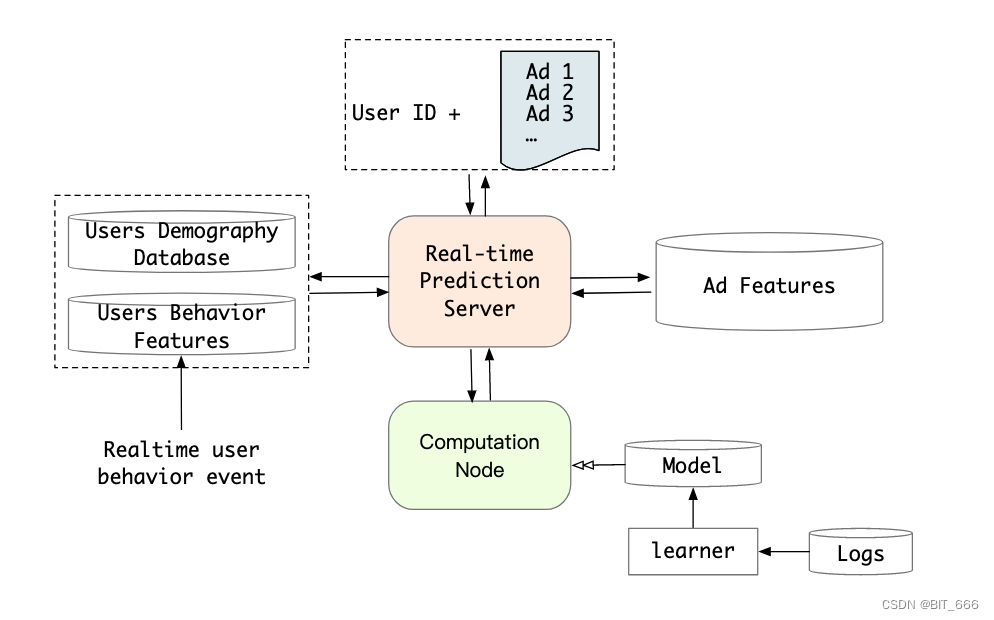
上图为 RTP 系统,其在阿里在线显示广告系统中用于 CTR 任务的实时预测。它由两个关键部分组成:计算节点 Computation Node 和预测服务器 Real-time Prediction Server。长序列用户行为数据会对 RTP 在线系统带来巨大的存储压力和延迟。考虑到终身用户行为,构建一个长期服务于实时工业系统的用户兴趣模型更加困难,且流量随用户行为序列长度的增加呈线性增长。此外,阿里巴巴的系统在流量高峰时每秒服务超过 100 万用户。因此长期用户行为模型部署到在线系统是一个巨大的挑战。
Tips:
Users Demography 用户统计学特征与 Users Behavior 用户行为特征以及 Ad Feature 候选广告特征会参与到实时预测系统中。
2.基于搜索的在线服务系统兴趣模型 Search-based Interest Model for Online Serving System
前面提出了两种通用搜索单元,软搜索模型和硬搜索模型。无论是软搜索模型还是硬搜索模型,我们都对行业数据进行了广泛的线下实验,这些数据来自阿里巴巴的在线展示广告系统。我们观察到软搜索模型生成的 Top-K 行为与硬搜索模型的结果非常相似。换句话说,大多数软搜索的 top-K 行为通常属于目标项目的类别。这是我们场景中数据的一个特征即 cate。在电子商务网站中,属于同一类别的商品在大多数情况下都是相似的。考虑到这一点,尽管软搜索模型在离线实验中表现略好于硬搜索模型,但在权衡性能收益和资源消耗后,我们选择硬搜索模型在我们的广告系统中部署SIM。
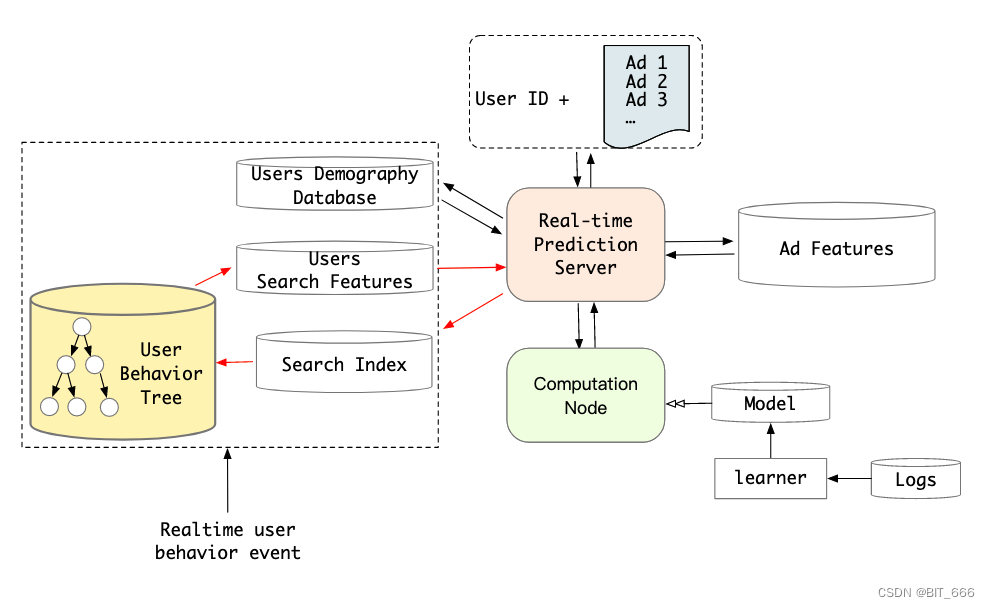
对于硬搜索模型,包含所有长顺序行为数据的索引是一个关键组成部分。我们观察到行为可以根据它们所属的类别自然地实现。因此,我们为每个用户构建一个两级结构化索引,我们将其命名为用户行为树 UBT,如下图所示。简而言之,UBT 遵循 key - key - value 数据结构:第一个键是用户id,第二个键是类别 id,最后一个值是属于每个类别的特定行为项。
UBT 作为分布式系统实现,其大小可达 22 TB,并且足够灵活,可以提供高吞吐量查询。然后,我们将目标商品的类别作为我们的硬搜索查询。在通用搜索单元之后,用户行为的长度可以从一万多个减少到一百个。从而释放在线系统中终身行为的存储压力。
下图为基于 UBT 的 SIM 模型 CTR 预测系统。新系统加入了一个硬搜索模块,从长序列行为数据中寻找目标项目的有效行为。用户行为树索引以离线方式提前建立,为在线服务节省了大部分的延迟成本。
Tips:
一般搜索单元 GSU 的用户行为树索引可以离线预构建。这样,在线系统中一般搜索单元的响应时间可以非常短,与 GSU 的计算相比可以忽略。此外,其他用户特征可以并行计算。
七.实验 EXPERIMENTS
本节中详细介绍了 SIM 的实验,包括数据集,实验设置,模型比较和一些相应的分析。
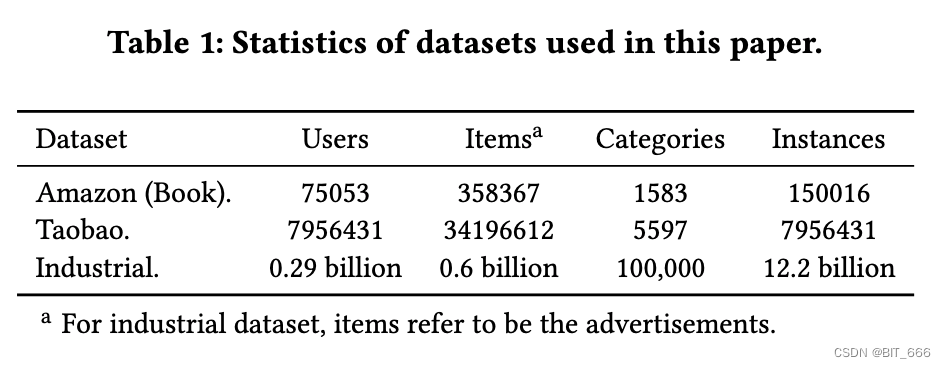
1.数据集 Datasets
模型比较采用了两个公共数据集和一个来自阿里巴巴在线展示广告系统的行业数据集。下表显示了所有数据集的统计信息:
• Amazon Dataset
该数据集来自于 Amazon 的产品评论和元数据组成。我们使用 Amazon 数据集的 Books 子集,它包含 75053 个用户、358367 个项目和 1583 个类别。对于该数据集,我们将评论视为一种交互行为,并按时间对来自同一用户的评论进行排序。Amazon 图书数据集的最大行为序列长度为 100。我们将最近的 10 个用户行为分为短期用户序列特征,将最近的 90 个用户行为分为长期用户序列特征。这些预处理方法在相关工作中得到了广泛的应用。
• Taobao Dataset
淘宝数据集是来自淘宝推荐系统的用户行为的集合。该数据集包含多种用户行为,包括点击、购买等。它包含了大约 800 万用户的用户行为序列。我们获取每个用户的点击行为,并根据时间对其进行排序,试图构建行为序列。淘宝数据集的最大行为序列长度为 500。我们将最近的 100 个用户行为划分为短期用户序列特征,将最近的 400 个用户行为划分为长期用户序列特征。数据集将于近期发布。
• Industrial Dataset
工业数据集收集自阿里巴巴的在线展示广告系统。样本由印象日志构建,以 "点击" 或 "不点击" 作为标签。训练集由过去 49 天的样本和第二天的测试集组成,这是工业建模的经典设置。在该数据集中,每天样本中的用户行为特征包含前 180 天的历史行为序列作为长期行为特征,前 14 天的历史行为序列作为短期行为特征。超过 30% 的样本包含长度超过 10000 的顺序行为数据。行为序列的最大长度达到 54000,是 MIMN 的 54 倍。
2.竞争者 Competitors
我们将 SIM 与主流点击率预测模型进行如下比较。
• DIN
DIN 是用户行为建模的早期工作,提出对用户行为 W.R.T. 与候选集进行软搜索。与其他长期用户兴趣模型相比,DIN只将短期用户行为作为输入。
• Avg-Pooling Long DIN
为了比较模型在长期用户兴趣上的性能,我们对长期行为应用了平均池化操作,并将长期嵌入与其他特征嵌入连接起来。
• MIMN
它巧妙地设计了模型架构,以捕捉用户的长期兴趣,实现了最先进的性能。
• SIM (hard)
第一阶段采用硬搜索,不进行时间嵌入。
• SIM (soft)
第一阶段采用软搜索,在 ESU 中没有时间嵌入。
• SIM (hard/soft)
带有 Timeinfo 的 SIM (硬/软) 是带有时间嵌入的第一阶段 硬/软 搜索的 SIM。
3.实验设置 experiment setup
对于所有模型,我们都使用亚当求解法。我们应用学习率从 0.001 开始的指数衰减。全连接网络 FCN 的层数设置为 200 × 80 × 2。嵌入维数设置为 4。并将广泛使用的 AUC 作为模型性能度量指标。
4.模型比较 Results on Public Datasets
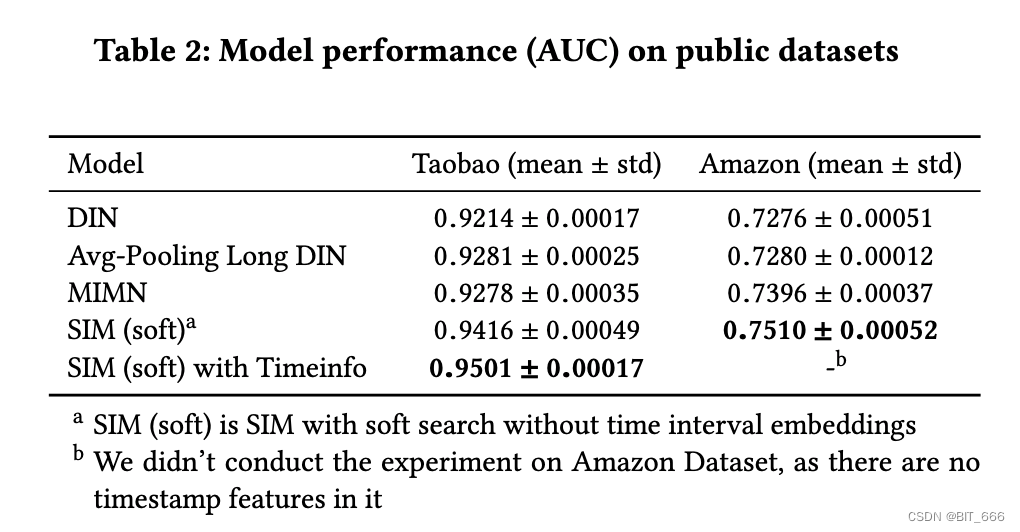
上表给出了所有比较模型的结果。与 DIN 相比,其他考虑长期用户行为特征的模型表现要好得多。结果表明,长期用户行为有助于 CTR 预测任务。与 MIMN 相比,SIM 实现了显著的改进,因为 MIMN 将所有未经过滤的用户历史行为编码到固定长度的记忆中,这使得难以捕获各种长期兴趣。SIM 使用两阶段搜索策略从海量的历史顺序行为中搜索相关行为,并对不同目标项目的不同长期兴趣变化进行建模。实验结果表明,SIM 的性能优于所有其他长期兴趣模型,有力地证明了所提出的两阶段搜索策略对于长期用户兴趣建模是有用的。此外,加入时间嵌入可以实现进一步的改进。
5.消融实验 Ablation Study
本实验主要验证两阶段搜索的有效性。如上所述,提出的搜索兴趣模型使用两阶段搜索策略。第一阶段遵循一般搜索策略,过滤掉与目标项目相关的历史行为。第二阶段对第一阶段的行为进行基于注意力的精确搜索,准确捕捉用户对目标物品的多种长期兴趣。在本节中,我们将通过应用于长期历史行为的不同操作的实验来评估所提出的两阶段搜索架构的有效性。
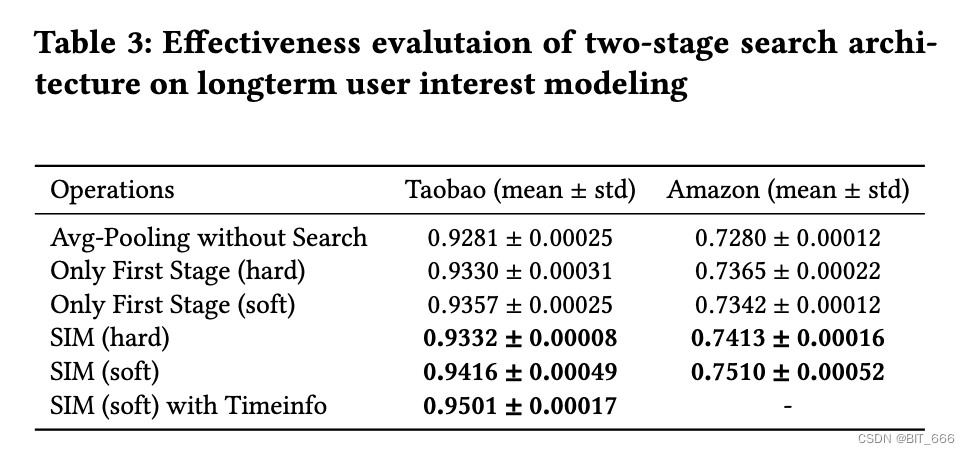
如 Table 3 所示,没有搜索的平均池化 (Avg-Pooling without Search) 与平均池化 (Avg-Pooling Long DIN) 一样,只是简单地使用平均池化来集成长期的行为嵌入,没有任何过滤器。Only First Stage (hard) 是在第一阶段对长期历史行为进行硬搜索,并通过平均池化将过滤后的嵌入整合到一个固定大小的向量上作为 MLP 的输入。除了在第一阶段应用参数软搜索而不是硬搜索之外,Only First Stage (软) 几乎与 Only First Stage (硬) 相同。在第三个实验中,我们基于预训练的嵌入向量离线计算目标商品与长期用户行为之间的内部产品相似度得分。软搜索是根据相似度评分选择前 50 个相关行为进行的。最后三个实验是提出的两阶段搜索结构的搜索模型。
如 Table 3 所示,与简单平均池化嵌入相比,所有采用滤波策略的方法都极大地提高了模型性能。这表明在原始的长期行为序列中确实存在大量的噪声,这可能会破坏长期的用户兴趣学习。与单阶段搜索模型相比。基于两阶段搜索策略的搜索模型在第二阶段引入了基于注意力的搜索,从而取得了进一步的进展。这表明,精确建模用户对目标项目的不同长期兴趣有助于 CTR 预测任务。经过第一阶段搜索后,过滤后的行为序列通常比原始序列短得多,所以 Attention 操作不会给联机服务 RTP 系统带来太大的负担。
其次模型在引入 Time Embedding 后得到进一步改进,说明不同时期用户行为的贡献是不同的。
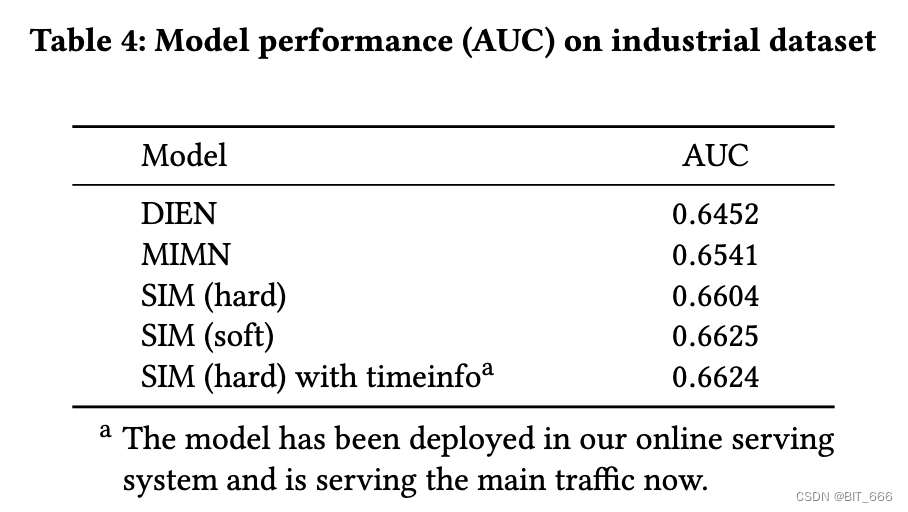
6.工业数据集结果 Results on Industrial Dataset

我们进一步对来自阿里巴巴在线展示广告系统的数据集进行实验。Table 4 显示了结果。与第一阶段的硬搜索相比,软搜索的性能更好。同时,我们注意到在第一阶段,两种搜索策略之间只有轻微的差距。在第一阶段使用软搜索会消耗更多的计算和存储资源。因为联机服务中会使用最近邻搜索方法,而硬搜索只需要从离线构建的二级索引表中进行搜索。因此,硬搜索是更有效和系统友好的。此外,对于两种不同的搜索策略,我们对来自工业数据集中的 100 多万个样本和 10 万具有长期历史行为的用户进行了统计。结果表明,硬搜索策略保留的用户行为可以覆盖软搜索策略保留的用户行为的 75%。最后,在效率和性能权衡的第一阶段,我们选择了更简单的硬搜索策略。SIM 对 MIMN 的改进,AUC 增益为 0.008,这对我们的业务意义重大。
• Online A/B Testing
自 2019 年以来,我们已经将提出的解决方案部署在阿里巴巴的展示广告系统中。从 2020-01-07到 2020-02-07,我们进行了严格的在线 A/B 测试实验来验证所提出的 SIM 模型。与我们上一个产品模型 MIMN 相比,SIM 在阿里巴巴展示广告场景中获得了巨大的收益,如 Table 5 所示。目前,SIM 已上线,每天服务主要场景流量,业务收入增长显著。
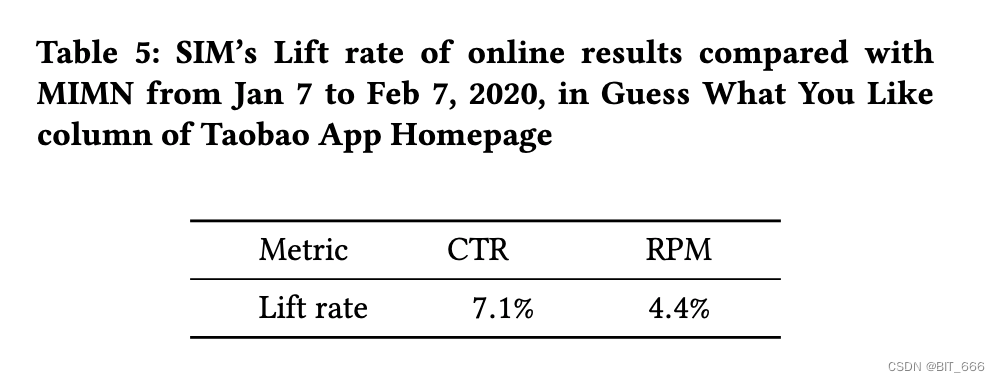
上表数据为 2020年1月7日至2月7日,淘宝 App 首页 "猜你喜欢什么" 栏目中,SIM 与 MIMN 的在线结果提升率对比。
• Rethinking Search Model
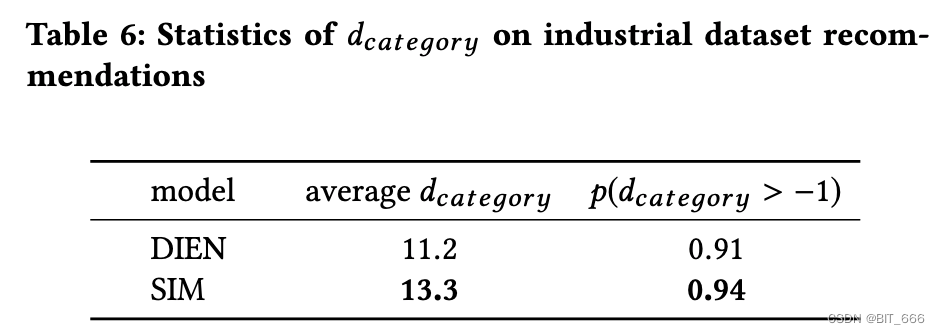
重新思考搜索模型。我们在用户长期兴趣建模方面做了大量的工作,所提出的 SIM 在离线和在线评估方面都有很好的表现。但是,精确的长期兴趣建模会使 SIM 表现得更好吗? SIM 是否更倾向于推荐与人们长期兴趣相关的项目? 为了回答这两个问题,我们提出了另一个问题评价指标:"Days till Last Same Category Behavior" 即 d-category 。点击样本的时间被定义为用户过去在与点击样本相同类别的物品上的行为到点击事件发生之间的天数。例如,用户 U1 点击了类别为 C1的物品 I1,用户 U1 在 5 天前点击了与 I1 类别相同的物品 I2,这就是用户 U1 过去在 C1 上的行为。如果将点击事件记为 S1,则样本 S1的 "Days till Last Same Category Behavior" 为5,即 d-category = 5,如果用户 U1 从未在类别 C1 上有过行为,则将 d-category 设为 −1。对于特定的模型,可以使用 d-category 来评估模型对长期或短期利益的选择偏好。
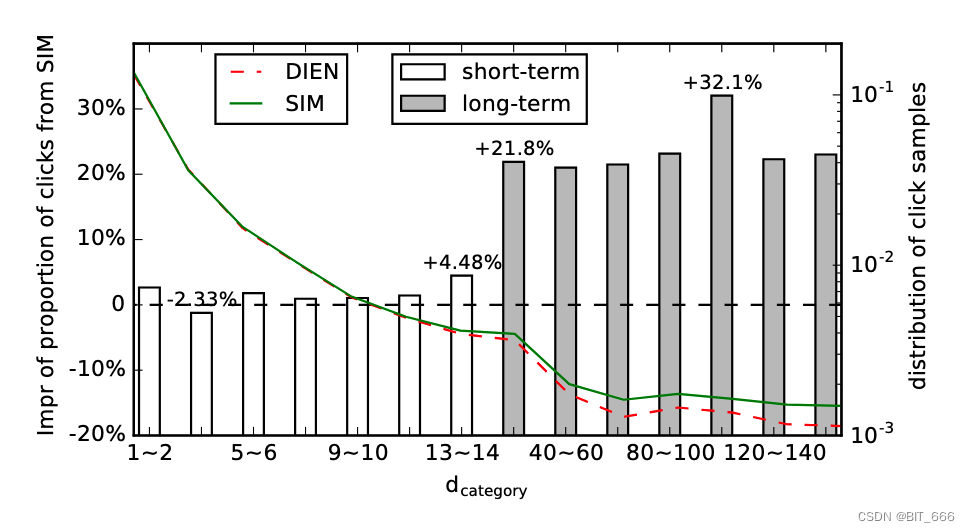
上图来自 DIEN 和 SIM 的点击样本分布,这些方框显示了来自 SIM 的点击比例 impr 的提升。从绿线与方框可以看到与 DIEN 相比,SIM 在用户长期行为与兴趣的发掘上更胜一筹。d-category 代表 "Days till Last Same Category Behavior",意为距离上一次相同行为标签的天数,该指标越大说明用户的长期兴趣更久远或是对当前兴趣发生行为的时间更久远。除此之外,这里认为 "≤14天" 内发生的行为为短期兴趣,">14天" 发生的行为为长期兴趣。
此外,我们对工业数据集上 d-category 的平均值和用户对目标项目具有历史类别行为的概率 (p(d-category > -1)) 进行静态计算,如 Table 6 所示。在工业数据集上的统计结果证明,SIM 的改进确实是由于更好的长期兴趣建模,与 DIEN 相比,SIM 更倾向于推荐与人们长期行为相关的项目。
• Practical Experience For Deployment
实际部署经验。在这里,我们将介绍在在线服务系统中实现 SIM 的实践实验。阿里巴巴的高流量是众所周知的,在流量高峰时每秒为 100 多万用户提供服务。此外,对于每个用户,RTP 系统需要计算数百个候选项目的预测点击率。我们对整个用户行为数据离线构建两阶段索引,每天更新。第一个阶段是用户 id。在第二阶段,根据用户与之交互的类别对用户的终身行为数据进行索引。虽然候选项目的数量有数百个,但这些项目的类别数量通常不到 20 个。同时,每个类别的 GSU 子行为序列长度被截断 200 (原始长度通常小于150)。这样,来自用户的每个请求的流量是有限的和可接受的。此外,我们还利用深度核融合优化了 ESU 中多头注意力的计算。
我们的实时点击率预测系统在使用 DIEN、MIMN 和 SIM 时的延迟时间性能如 Figure-5 所示。值得注意的是,MIMN 可以处理的用户行为的最大长度是 1000,所显示的性能是基于截断的行为数据。虽然 SIM 中的用户行为长度不会被截断,并且可以扩展到 54000,将最大长度推高到 54x。与使用截断用户行为的 MIMN 服务相比,使用超过 10,000 个行为的 SIM 服务只增加了 5ms 的延迟。
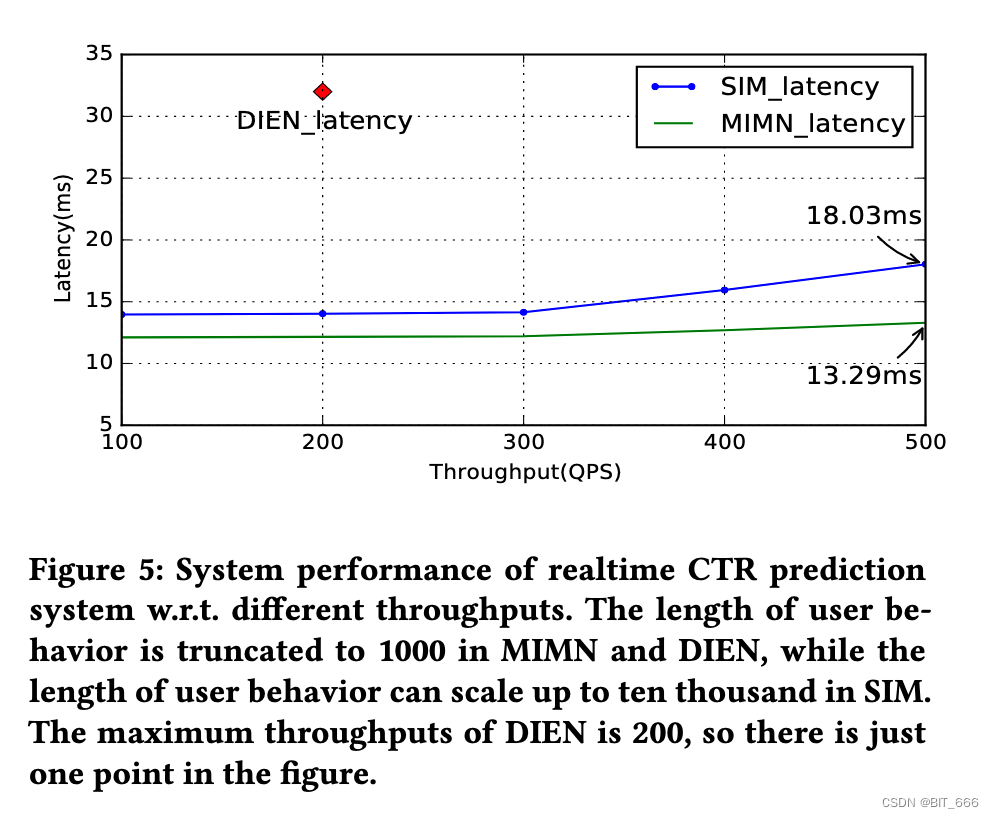
实时 CTR 预测系统在不同吞吐量下的系统性能。在 MIMN 和 DIEN 中,用户行为长度被截断为1000,而在 SIM 中,用户行为长度可以扩展到 10000。DIEN 的最大吞吐量是 200,所以图中只有一个点。
八.总结
在本文中,我们的重点是在实际工业中挖掘超过一万的顺序用户行为数据。提出了基于搜索的兴趣模型,以捕获用户对目标项目的长期兴趣。在第一阶段,我们提出了一个通用搜索单元,将数万个行为减少到数百个。在第二阶段,精确搜索单元利用数百个相关行为来模拟精确的用户兴趣。我们在阿里巴巴的展示广告系统中实现了 SIM。SIM 带来了显著的业务改善,并服务于主要流量。
与以往的方法相比,SIM 引入了更多的用户行为数据,实验结果表明,SIM 更关注用户的长期兴趣。但搜索单元在所有用户中仍然使用相同的公式和参数。在未来,我们将尝试建立特定于用户的模型,从个人意识的角度组织每个用户的终身行为数据。通过这种方式,每个用户都将拥有他们自己的模型,该模型将继续对用户不断变化的兴趣进行建模。
• 结论
- 长序列即长期兴趣由于短序列即短期兴趣
- Attention 注意力机制由于简单的 Sum Pooling
- Soft Search 略优于 Hard Search,具体使用需结合机器成本、时间成本
- 引入 Good 的 Time Info 是有效的
不论是以业务为导向的想法还是以用户为目标的建模,不论理论还是工程实践,读完之后感觉收获满满,还需继续努力学习呀!
• 参考
Life-long兴趣建模视角CTR预估模型:Search-based Interest Model
更多推荐算法相关深度学习:深度学习导读专栏



















 1349
1349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











