








前言:淋过雨,才会想为别人撑伞,本次hw相比前面几次hw难度大很多,并且在网络上无法提交获得test的得分,所以就以解释代码为主,但解释代码也很困难,我看了好几天才把整个代码看懂,接下来将会详细解释代码,也会解释网络架构,并提供要彻底搞懂本次作业所需要学习的部分。
首先简要介绍一下本次作业的整体框架:
一、数据预处理
1.下载解压数据 2.处理符号空格等 3.分割训练集验证集 4.分词化单元 5.二进制化数据集
二、加载数据
1.生成TranslationTask 2.用task加载数据 3.定义数据批迭代器
三、模型架构(使用fairseq库)
1.RNNencoder 2.AttentionLayer 3.RNNdecoder 4.seq2seq 5.定义model_build函数
四、损失函数和优化器定义
1.Loss func-标签平滑交叉熵 2.optimizer- NoamOpt
五、定义训练步骤
就是正常正向传播再反向传播更新参数,但是其中用了scaler来进行梯度计算和参数更新(nlp问题容易出现梯度爆炸和梯度消失等问题,使用scaler来处理精度问题)
六、定义推理预测以及验证
1.inference函数 2.定义valid
七、模型训练
略

准备:
需要先提前下载好数据,我做的时候是通过网上整理好的资料获得的数据集,也可以通过wget,这个的话要自己操作一下。
我的作业是从这个视频的链接下载的
(强推)李宏毅2021/2022春机器学习课程_哔哩哔哩_bilibili
注意一下,我在做这个作业的时候,得到的fairseq库是有问题的,需要更换别的版本的库,可以在bash里面输入下面的进行下载,其中xxxx需要改为自己的端口号。git国内不能用,记得魔法上网。
set https_proxy=http://127.0.0.1:xxxx
set http_proxy=http://127.0.0.1:xxxx
pip install git+https://github.com/One-sixth/fairseq.git建议在本地的jupyter中跑的时候加上一下代码,调试时显示的信息就是中文
!chcp 65001
!echo 中文接下来略过导入库和设置随机种子的代码部分,到数据下载的部分
data_dir = './DATA/rawdata'
dataset_name = 'ted2020'
urls = (
'"https://onedrive.live.com/download?cid=3E549F3B24B238B4&resid=3E549F3B24B238B4%214989&authkey=AGgQ-DaR8eFSl1A"',
'"https://onedrive.live.com/download?cid=3E549F3B24B238B4&resid=3E549F3B24B238B4%214987&authkey=AA4qP_azsicwZZM"',
# # If the above links die, use the following instead.
# "https://www.csie.ntu.edu.tw/~r09922057/ML2021-hw5/ted2020.tgz",
# "https://www.csie.ntu.edu.tw/~r09922057/ML2021-hw5/test.tgz",
# # If the above links die, use the following instead.
# "https://mega.nz/#!vEcTCISJ!3Rw0eHTZWPpdHBTbQEqBDikDEdFPr7fI8WxaXK9yZ9U",
# "https://mega.nz/#!zNcnGIoJ!oPJX9AvVVs11jc0SaK6vxP_lFUNTkEcK2WbxJpvjU5Y",
)
file_names = (
'ted2020.tgz', # train & dev
'test.tgz', # test
)
prefix = Path(data_dir).absolute() / dataset_name
prefix.mkdir(parents=True, exist_ok=True)
for u, f in zip(urls, file_names):
path = prefix/f
if not path.exists():
if 'mega' in u:
!megadl {u} --path {path}
else:
!wget {u} -O {path}
if path.suffix == ".tgz":
!tar -xvf {path} -C {prefix}
elif path.suffix == ".zip":
!unzip -o {path} -d {prefix}
!mv {prefix/'raw.en'} {prefix/'train_dev.raw.en'}
!mv {prefix/'raw.zh'} {prefix/'train_dev.raw.zh'}
!mv {prefix/'test.en'} {prefix/'test.raw.en'}
!mv {prefix/'test.zh'} {prefix/'test.raw.zh'}这里就是下载数据,并把数据文件重命名,最后四行mv是linux下的操作命令,我们可以自己手动更改或者用操作命令行更改
src_lang = 'en'
tgt_lang = 'zh'
data_prefix = f'{prefix}/train_dev.raw'
test_prefix = f'{prefix}/test.raw'
!head {data_prefix+'.'+src_lang} -n 5
!head {data_prefix+'.'+tgt_lang} -n 5这里是显示train_dev.raw和test.raw文件的前五个sequence,最后两行head是linux下的操作命令,我们可以改为分别用来显示全文,windows没有head显示文件前五行的操作,只能显示全文,最好分开显示,这一步是有助于你理解数据内部格式,和数据是做什么的,后面你也会继续用该操作来显示数据格式
!type E:\Li_Hung_Yi_ml\HW5_2021\DATA\rawdata\ted2020\train_dev.raw.en
!type E:\Li_Hung_Yi_ml\HW5_2021\DATA\rawdata\ted2020\test.raw.zh接下来是对字符做标点符号处理即clean_s函数和clean_corpus函数
其中,strQ2B函数是全角转半角操作,用的utf-8格式字符12288指全角空格转32半角空格,然后减去65248是指英文字符全角转半角
clean_s函数有两个参数,s和lang,s是sequence,lang是language,即en和zh,使用re对sequence进行符号操作,可能最困惑的是sub这个函数里面的几个参数,例如r"\([^()]*\)",这个是python中的正则表达式,将会用""空字符替换掉括号内的内容。详细的看下面解释:
这段代码是使用Python中的正则表达式模块`re`来执行字符串替换操作。具体来说,它使用了`re.sub()`函数,该函数用于在字符串中查找匹配某个正则表达式模式的部分,并将其替换为指定的内容。
让我们来解释代码中的各个部分:
1. `re.sub()`是`re`模块中的一个函数,用于执行正则表达式的替换操作。
2. `r"\([^()]*\)"`是一个正则表达式模式。让我们分解它:
- `\(` 匹配一个左括号 `(`。
- `[^()]*` 匹配零个或多个不包含左括号和右括号的字符。这个部分用于匹配括号中的任何文本。
- `\)` 匹配一个右括号 `)`。
所以整个模式可以匹配任何形式的括号及其内部文本,例如 `(text)`。
3. `""`是替换字符串,表示将匹配到的内容替换为空字符串,即删除匹配到的部分。
所以,这段代码的作用是从字符串`s`中删除所有括号及其内部的文本,即删除所有形如 `(text)` 的内容。
clean_corpus是调用clean_s对文件的en版本和zh版本所有seq进行处理,并改名为xx.clean.xx,其中的ratio,max_len,min_len等参数是对处理进行限制
import re
def strQ2B(ustring):
"""Full width -> half width"""
# reference:https://ithelp.ithome.com.tw/articles/10233122
ss = []
for s in ustring:
rstring = ""
for uchar in s:
inside_code = ord(uchar)
if inside_code == 12288: # Full width space: direct conversion
inside_code = 32
elif (inside_code >= 65281 and inside_code <= 65374): # Full width chars (except space) conversion
inside_code -= 65248
rstring += chr(inside_code)
ss.append(rstring)
return ''.join(ss)
def clean_s(s, lang):
if lang == 'en':
s = re.sub(r"\([^()]*\)", "", s) # remove ([text])
s = s.replace('-', '') # remove '-'
s = re.sub('([.,;!?()\"])', r' \1 ', s) # keep punctuation
elif lang == 'zh':
s = strQ2B(s) # Q2B
s = re.sub(r"\([^()]*\)", "", s) # remove ([text])
s = s.replace(' ', '')
s = s.replace('—', '')
s = s.replace('“', '"')
s = s.replace('”', '"')
s = s.replace('_', '')
s = re.sub('([。,;!?()\"~「」])', r' \1 ', s) # keep punctuation
s = ' '.join(s.strip().split())
return s
def len_s(s, lang):
if lang == 'zh':
return len(s)
return len(s.split())
def clean_corpus(prefix, l1, l2, ratio=9, max_len=1000, min_len=1):
if Path(f'{prefix}.clean.{l1}').exists() and Path(f'{prefix}.clean.{l2}').exists():
print(f'{prefix}.clean.{l1} & {l2} exists. skipping clean.')
return
with open(f'{prefix}.{l1}', 'r') as l1_in_f:
with open(f'{prefix}.{l2}', 'r') as l2_in_f:
with open(f'{prefix}.clean.{l1}', 'w') as l1_out_f:
with open(f'{prefix}.clean.{l2}', 'w') as l2_out_f:
for s1 in l1_in_f:
s1 = s1.strip()
s2 = l2_in_f.readline().strip()
s1 = clean_s(s1, l1)
s2 = clean_s(s2, l2)
s1_len = len_s(s1, l1)
s2_len = len_s(s2, l2)
if min_len > 0: # remove short sentence
if s1_len < min_len or s2_len < min_len:
continue
if max_len > 0: # remove long sentence
if s1_len > max_len or s2_len > max_len:
continue
if ratio > 0: # remove by ratio of length
if s1_len/s2_len > ratio or s2_len/s1_len > ratio:
continue
print(s1, file=l1_out_f)
print(s2, file=l2_out_f)接下来一个部分是对数据进行划分,把train_dev.raw.clean.en和train_dev.raw.clean.zh划分为train data和valid data
利用shuffle来对index进行打乱,然后根据train_ratio和打乱后的index来分配原文件内的sequence进入新的train和valid文件,最终生成了四个新文件如下图
if (prefix/f'train.clean.{src_lang}').exists() \
and (prefix/f'train.clean.{tgt_lang}').exists() \
and (prefix/f'valid.clean.{src_lang}').exists() \
and (prefix/f'valid.clean.{tgt_lang}').exists():
print(f'train/valid splits exists. skipping split.')
else:
line_num = sum(1 for line in open(f'{data_prefix}.clean.{src_lang}'))
labels = list(range(line_num))
random.shuffle(labels)
for lang in [src_lang, tgt_lang]:
train_f = open(os.path.join(data_dir, dataset_name, f'train.clean.{lang}'), 'w')
valid_f = open(os.path.join(data_dir, dataset_name, f'valid.clean.{lang}'), 'w')
count = 0
for line in open(f'{data_prefix}.clean.{lang}', 'r'):
if labels[count]/line_num < train_ratio:
train_f.write(line)
else:
valid_f.write(line)
count += 1
train_f.close()
valid_f.close()接下来是进行分词化,把一个单词变成分词形式,用spm库中的SentencePieceTrainer架构train这四个文件中出现的中文和英文词汇,最后train出一个spm模型和一个spm分词字典库
import sentencepiece as spm
vocab_size = 8000
if (prefix/f'spm{vocab_size}.model').exists():
print(f'{prefix}/spm{vocab_size}.model exists. skipping spm_train.')
else:
spm.SentencePieceTrainer.train(
input=','.join([f'{prefix}/train.clean.{src_lang}',
f'{prefix}/valid.clean.{src_lang}',
f'{prefix}/train.clean.{tgt_lang}',
f'{prefix}/valid.clean.{tgt_lang}']),
model_prefix=prefix/f'spm{vocab_size}',
vocab_size=vocab_size,
character_coverage=1,
model_type='unigram', # 'bpe' works as well
input_sentence_size=1e6,
shuffle_input_sentence=True,
normalization_rule_name='nmt_nfkc_cf',
)下面的代码是用train好的spm8000.model来对train,valid,test文件进行分词化,然后output放在新的文件里面即最后的out_f,tok为spm_model对每个sequence的输出,用print到file的操作来实现写入文件
spm_model = spm.SentencePieceProcessor(model_file=str(prefix/f'spm{vocab_size}.model'))
in_tag = {
'train': 'train.clean',
'valid': 'valid.clean',
'test': 'test.raw.clean',
}
for split in ['train', 'valid', 'test']:
for lang in [src_lang, tgt_lang]:
out_path = prefix/f'{split}.{lang}'
if out_path.exists():
print(f"{out_path} exists. skipping spm_encode.")
else:
with open(prefix/f'{split}.{lang}', 'w') as out_f:
with open(prefix/f'{in_tag[split]}.{lang}', 'r') as in_f:
for line in in_f:
line = line.strip()
tok = spm_model.encode(line, out_type=str)
print(' '.join(tok), file=out_f)下面的代码是利用fairseq库中的函数对文件内的内容进行二值化,并生成两个词汇表(en和zh的),但是由于用了joined-dictionary这个参数,en和zh共享词汇表
binpath = Path('./DATA/data-bin', dataset_name)
if binpath.exists():
print(binpath, "exists, will not overwrite!")
else:
!python -m fairseq_cli.preprocess \
--source-lang {src_lang}\
--target-lang {tgt_lang}\
--trainpref {prefix/'train'}\
--validpref {prefix/'valid'}\
--testpref {prefix/'test'}\
--destdir {binpath}\
--joined-dictionary\
--workers 2我们看一下词汇表的内容,例如_,是分词,875945是出现的频次,而每个分词的index则是比如说‘s’是6,‘的’是8,为什么要加3呢?因为其中<unk>,<s>,<\s>,<pad>四个特殊空白字符在前面作为前四个。
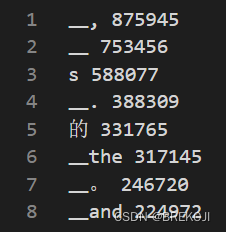
接下来创建TranslationTask,利用task加载数据,可能会有疑问说为什么没有传入数据文件的绝对路径,但是就能加载数据呢?因为前面进行二值化的时候用的是fairseq库的函数,处理生成的文件会有固定格式的文件名,如test.en-zh.en.bin,test.en-zh.en.idx,task的load_dataset函数会根据split,自动加上‘en-zh’和后缀,那为什么是en-zh呢,因为在task创建的时候,进行了配置,source_lang和target_lang这边定义了en和-zh,配置的一个参数train_subset是指训练的时候用split为train加载的数据训练,具体的想了解这个工作的原理可以看库文件里函数的代码,required_seq_len_multiple是指产生的seq的长度需要为该倍数,比如原seq长度为11,要为8的倍数,就会加上<s>或<\s>或<pad>,总共5个
from fairseq.tasks.translation import TranslationConfig, TranslationTask
## setup task
task_cfg = TranslationConfig(
data=config.datadir,
source_lang=config.source_lang,
target_lang=config.target_lang,
train_subset="train",
required_seq_len_multiple=8,
dataset_impl="mmap",
upsample_primary=1,
)
task = TranslationTask.setup_task(task_cfg)logger.info("loading data for epoch 1")
task.load_dataset(split="train", epoch=1, combine=True) # combine if you have back-translation data.
task.load_dataset(split="valid", epoch=1)下面这段代码是向你展示task的数据集案例
sample = task.dataset("valid")[1]
pprint.pprint(sample)
pprint.pprint(
"Source: " + \
task.source_dictionary.string(
sample['source'],
config.post_process,
)
)
pprint.pprint(
"Target: " + \
task.target_dictionary.string(
sample['target'],
config.post_process,
)
)输出如下,pprint是用漂亮的格式进行输出,尽可能保存了数据原有的格式,然后其中举个例子29对应着‘在’,而在字典中,‘在’的对应行数是26,这也应证了我前面说的,你不妨自己试一下,把target的tensor里面的第一个元素分别改为0,1,2,3会出现什么情况
{'id': 1,
'source': tensor([ 18, 15, 6, 2154, 64, 19, 75, 5, 334, 14, 340, 1346,
1627, 7, 2]),
'target': tensor([ 149, 675, 29, 269, 41, 161, 1088, 646, 592, 366, 3105, 2345,
1374, 208, 2])}
"Source: that's exactly what i do optical mind control ."
'Target: 這實在就是我所做的--光學操控思想'下面是定义数据批迭代器函数,并向你展示迭代器的用法,首先创建一个多轮数据批迭代器集合,然后用next_epoch_itr来得到不同训练轮数的数据批迭代器,然后利用next,来获得该迭代器中的不同批数据,load_dataset_iterator中的max_tokens参数是指每个sequence中的最大标签数,小于大于该标签数的就舍弃
def load_data_iterator(task, split, epoch=1, max_tokens=4000, num_workers=1, cached=True):
batch_iterator = task.get_batch_iterator(
dataset=task.dataset(split),
max_tokens=max_tokens,
max_sentences=None,
max_positions=utils.resolve_max_positions(
task.max_positions(),
max_tokens,
),
ignore_invalid_inputs=True,
seed=seed,
num_workers=num_workers,
epoch=epoch,
disable_iterator_cache=not cached,
# Set this to False to speed up. However, if set to False, changing max_tokens beyond
# first call of this method has no effect.
)
return batch_iterator
demo_epoch_obj = load_data_iterator(task, "valid", epoch=1, max_tokens=20, num_workers=1, cached=False)
demo_iter = demo_epoch_obj.next_epoch_itr(shuffle=True)
sample = next(demo_iter)
sample以上就是数据预处理和准备部分,接下来是更重要的模型架构
了解RNNencoder模型架构,你需要有的知识是,word_embedding,word2vec,RNN,GRU,LSTM,encoder
下面是视频链接,如果不能魔法上网,可以去b站找对应资料
ML Lecture 14: Unsupervised Learning - Word Embedding - YouTube
ML Lecture 21-1: Recurrent Neural Network (Part I) - YouTube
【機器學習2021】Transformer (上) - YouTube
【機器學習2021】Transformer (下) - YouTube
我直接开始讲下面代码的forward部分,并解释前面的定义部分,
x = self.embed_tokens(src_tokens)这个是会把source_tokens输入embedding layer当中,假如source_tokens是(312,18)这样的dimension的,你可以认为312是batch_size,18是这个batch_size的sequence_len,假如word2vec的vec_dimension是256,然后输出会是(312,18,256),就是把sequence中的每个word都变为一个256维的vector来代表这个word,具体这个embedding_layer长什么样,要看传入的embed_tokens这个参数给的是什么样的layer,稍微讲解一下embedding_layer(可以跳过),词嵌入是有好几种方法,有根据上下文频率来确定词与词之间的相似度进而确定词嵌入matrix的,也有根据预测来确定词嵌入matrix的,这里面有glove,cbow,skip-gram等方法,可以深入了解
x = self.embed_tokens(src_tokens)接下来,定义h0,x.new_zeros这个的意思是,使用x一样数据类型,一样device的设置来生成一个随机初始化的参数矩阵,后面的参数是该参数矩阵的size,为什么要乘2,因为GRU定义的时候bidirectional这里定义为True,双向的门控单元,然后下一句的意思是用h0初始化GRU的hidden_dim weight,然后得到一个新的输出,和hidden_layer的weight,
h0 = x.new_zeros(2 * self.num_layers, bsz, self.hidden_dim)
x, final_hiddens = self.rnn(x, h0)下面这个是用来做什么的呢?是得到source_token的pad,然后使其为true,以便后续处理方便
encoder_padding_mask = src_tokens.eq(self.padding_idx).t()最终RNNencoder的输出是(bsz,256,1024)维,256是vec的dim,1024是hidden_layer*2
class RNNEncoder(FairseqEncoder):
def __init__(self, args, dictionary, embed_tokens):
super().__init__(dictionary)
self.embed_tokens = embed_tokens
self.embed_dim = args.encoder_embed_dim
self.hidden_dim = args.encoder_ffn_embed_dim
self.num_layers = args.encoder_layers
self.dropout_in_module = nn.Dropout(args.dropout)
self.rnn = nn.GRU(
self.embed_dim,
self.hidden_dim,
self.num_layers,
dropout=args.dropout,
batch_first=False,
bidirectional=True
)
self.dropout_out_module = nn.Dropout(args.dropout)
self.padding_idx = dictionary.pad()
def combine_bidir(self, outs, bsz: int):
out = outs.view(self.num_layers, 2, bsz, -1).transpose(1, 2).contiguous()
return out.view(self.num_layers, bsz, -1)
def forward(self, src_tokens, **unused):
bsz, seqlen = src_tokens.size()
# get embeddings
x = self.embed_tokens(src_tokens)
x = self.dropout_in_module(x)
# B x T x C -> T x B x C
x = x.transpose(0, 1)
# pass thru bidirectional RNN
h0 = x.new_zeros(2 * self.num_layers, bsz, self.hidden_dim)
x, final_hiddens = self.rnn(x, h0)
outputs = self.dropout_out_module(x)
# outputs = [sequence len, batch size, hid dim * directions]
# hidden = [num_layers * directions, batch size , hid dim]
# Since Encoder is bidirectional, we need to concatenate the hidden states of two directions
final_hiddens = self.combine_bidir(final_hiddens, bsz)
# hidden = [num_layers x batch x num_directions*hidden]
encoder_padding_mask = src_tokens.eq(self.padding_idx).t()
#print(encoder_padding_mask)
#print(encoder_padding_mask.size())
return tuple(
(
outputs, # seq_len x batch x hidden
final_hiddens, # num_layers x batch x num_directions*hidden
encoder_padding_mask, # seq_len x batch
)
)
def reorder_encoder_out(self, encoder_out, new_order):
# This is used by fairseq's beam search. How and why is not particularly important here.
return tuple(
(
encoder_out[0].index_select(1, new_order),
encoder_out[1].index_select(1, new_order),
encoder_out[2].index_select(1, new_order),
)
)下一个是AttentionLayer,该层是decoder中的一个层,我们直接讲forward,inputs参数是decoder经过其中的embedding层然后得到的输出,这当中,inputs是key,encoder_outputs是query和value,output_embed_dim是value,要经过一个input_proj是把inputs升维,以和query相乘即bmm,然后用encoder_padding_mask对attn中的pad位为负无穷,接着对最后一个维度做softmax,再与v相乘,再增加输入的位置信息,再通过一个线性层得到输出
class AttentionLayer(nn.Module):
def __init__(self, input_embed_dim, source_embed_dim, output_embed_dim, bias=False):
super().__init__()
self.input_proj = nn.Linear(input_embed_dim, source_embed_dim, bias=bias)
self.output_proj = nn.Linear(
input_embed_dim + source_embed_dim, output_embed_dim, bias=bias
)
def forward(self, inputs, encoder_outputs, encoder_padding_mask):
# inputs: T, B, dim
# encoder_outputs: S x B x dim
# padding mask: S x B
# convert all to batch first
inputs = inputs.transpose(1,0) # B, T, dim
encoder_outputs = encoder_outputs.transpose(1,0) # B, S, dim
encoder_padding_mask = encoder_padding_mask.transpose(1,0) # B, S
# project to the dimensionality of encoder_outputs
x = self.input_proj(inputs)
# compute attention
# (B, T, dim) x (B, dim, S) = (B, T, S)
attn_scores = torch.bmm(x, encoder_outputs.transpose(1,2))
# cancel the attention at positions corresponding to padding
if encoder_padding_mask is not None:
# leveraging broadcast B, S -> (B, 1, S)
encoder_padding_mask = encoder_padding_mask.unsqueeze(1)
attn_scores = (
attn_scores.float()
.masked_fill_(encoder_padding_mask, float("-inf"))
.type_as(attn_scores)
) # FP16 support: cast to float and back
# softmax on the dimension corresponding to source sequence
attn_scores = F.softmax(attn_scores, dim=-1)
# shape (B, T, S) x (B, S, dim) = (B, T, dim) weighted sum
x = torch.bmm(attn_scores, encoder_outputs)
# (B, T, dim)
x = torch.cat((x, inputs), dim=-1)
x = torch.tanh(self.output_proj(x)) # concat + linear + tanh
# restore shape (B, T, dim) -> (T, B, dim)
return x.transpose(1,0), attn_scores这个相对来说是最复杂的,但也没有那么复杂,关键看forward,其中,如encoder的forward,最后的out是打包成一个tuple的,对于incremental_state暂时不需要管,这个是在代码运行过程中库函数产生的参数,在valid的时候会调用之前训练好的weight,总体的流程就是输入一个embedding层,然后做attention输入GRU,然后将输出通过线性层转化为8000维的输出
class RNNDecoder(FairseqIncrementalDecoder):
def __init__(self, args, dictionary, embed_tokens):
super().__init__(dictionary)
self.embed_tokens = embed_tokens
assert args.decoder_layers == args.encoder_layers, f"""seq2seq rnn requires that encoder
and decoder have same layers of rnn. got: {args.encoder_layers, args.decoder_layers}"""
assert args.decoder_ffn_embed_dim == args.encoder_ffn_embed_dim*2, f"""seq2seq-rnn requires
that decoder hidden to be 2*encoder hidden dim. got: {args.decoder_ffn_embed_dim, args.encoder_ffn_embed_dim*2}"""
self.embed_dim = args.decoder_embed_dim
self.hidden_dim = args.decoder_ffn_embed_dim
self.num_layers = args.decoder_layers
self.dropout_in_module = nn.Dropout(args.dropout)
self.rnn = nn.GRU(
self.embed_dim,
self.hidden_dim,
self.num_layers,
dropout=args.dropout,
batch_first=False,
bidirectional=False
)
self.attention = AttentionLayer(
self.embed_dim, self.hidden_dim, self.embed_dim, bias=False
)
# self.attention = None
self.dropout_out_module = nn.Dropout(args.dropout)
if self.hidden_dim != self.embed_dim:
self.project_out_dim = nn.Linear(self.hidden_dim, self.embed_dim)
else:
self.project_out_dim = None
#8000
#print(self.embed_tokens.weight.shape[0])
#256
#print(self.embed_tokens.weight.shape[1])
if args.share_decoder_input_output_embed:
self.output_projection = nn.Linear(
self.embed_tokens.weight.shape[1],
self.embed_tokens.weight.shape[0],
bias=False,
)
self.output_projection.weight = self.embed_tokens.weight
else:
self.output_projection = nn.Linear(
self.output_embed_dim, len(dictionary), bias=False
)
nn.init.normal_(
self.output_projection.weight, mean=0, std=self.output_embed_dim ** -0.5
)
def forward(self, prev_output_tokens, encoder_out, incremental_state=None, **unused):
# extract the outputs from encoder
encoder_outputs, encoder_hiddens, encoder_padding_mask = encoder_out
# outputs: seq_len x batch x num_directions*hidden
# encoder_hiddens: num_layers x batch x num_directions*encoder_hidden
# padding_mask: seq_len x batch
#if incremental_state is None:
# print('incremental_state is None')
#else:
# print(incremental_state)
if incremental_state is not None and len(incremental_state) > 0:
# if the information from last timestep is retained, we can continue from there instead of starting from bos
#print(prev_output_tokens.size())
prev_output_tokens = prev_output_tokens[:, -1:]
#print(prev_output_tokens.size())
cache_state = self.get_incremental_state(incremental_state, "cached_state")
prev_hiddens = cache_state["prev_hiddens"]
else:
# incremental state does not exist, either this is training time, or the first timestep of test time
# prepare for seq2seq: pass the encoder_hidden to the decoder hidden states
# print('incremental_state is None')
prev_hiddens = encoder_hiddens
#print(prev_output_tokens)
bsz, seqlen = prev_output_tokens.size()
# embed tokens
#print("self.embed_tokens.weight",self.embed_tokens.weight.size())
x = self.embed_tokens(prev_output_tokens)
x = self.dropout_in_module(x)
# B x T x C -> T x B x C B-batchsize T-sequencelength(timestep) C-embedfeatures
x = x.transpose(0, 1)
# decoder-to-encoder attention
if self.attention is not None:
x, attn = self.attention(x, encoder_outputs, encoder_padding_mask)
# pass thru unidirectional RNN
x, final_hiddens = self.rnn(x, prev_hiddens)
# outputs = [sequence len, batch size, hid dim]
# hidden = [num_layers * directions, batch size , hid dim]
x = self.dropout_out_module(x)
# project to embedding size (if hidden differs from embed size, and share_embedding is True,
# we need to do an extra projection)
if self.project_out_dim != None:
x = self.project_out_dim(x)
# project to vocab size
x = self.output_projection(x)
# T x B x C -> B x T x C
x = x.transpose(1, 0)
# if incremental, record the hidden states of current timestep, which will be restored in the next timestep
cache_state = {
"prev_hiddens": final_hiddens,
}
self.set_incremental_state(incremental_state, "cached_state", cache_state)
return x, None
def reorder_incremental_state(
self,
incremental_state,
new_order,
):
# This is used by fairseq's beam search. How and why is not particularly important here.
cache_state = self.get_incremental_state(incremental_state, "cached_state")
prev_hiddens = cache_state["prev_hiddens"]
prev_hiddens = [p.index_select(0, new_order) for p in prev_hiddens]
cache_state = {
"prev_hiddens": torch.stack(prev_hiddens),
}
self.set_incremental_state(incremental_state, "cached_state", cache_state)
return后面的seq2seq就是将encoder和decoder组合在一起
后面的一些都比较简单就直接略过,接下来是标签平滑交叉熵和NoamOpt,前者是在计算时考虑总体的标签,而不是单纯地让为0的prediction得到的结果为零,考虑了全体prediction,而NoamOpt就是在刚开始的时候快速提高lambda学习率,快速收敛,然后再退火,动态缩小学习率,使得准确收敛,后面就是做valid,和save,predict这些,都较为简单,其中有一个我自学了一下的,是scaler,这个东西是能够动态缩放梯度的,能够使得梯度计算更快捷,可以防止梯度爆炸,和梯度消失,做梯度剪枝,然后在做step更新模型参数时,会用unscale来重置缩放
with autocast():
#pprint.pprint(sample["net_input"])
net_output = model.forward(**sample["net_input"])
#print(net_output[0].size())
#print(net_output[0])
lprobs = F.log_softmax(net_output[0], -1)
#print("lprobs",lprobs.size())
#print("target",target.size())
loss = criterion(lprobs.view(-1, lprobs.size(-1)), target.view(-1))
# logging
# Here,the loss is the tensor type,so use the item() func to extract the loss num.
accum_loss += loss.item()
# back-prop
scaler.scale(loss).backward()
scaler.unscale_(optimizer)
optimizer.multiply_grads(1 / (sample_size or 1.0)) # (sample_size or 1.0) handles the case of a zero gradient
gnorm = nn.utils.clip_grad_norm_(model.parameters(), config.clip_norm) # grad norm clipping prevents gradient exploding补充,做strong_line的时候,只需要把RNN的encoder和decoder注释掉,然后加上TransformerEncoder和TransformerDecoder即可,然后更改一下config,把savedir里的文件名改为transformer。
然后要注意一下,你做这个作业的时候可能会出现和我类似的问题,就是可能最后test的prediction很离谱,这个时候可能是spm_model做字典预测的时候出问题了,我好像是自己不小心把test的文件名改了,把已经被分词化的文件改为了未做分词化的test文件,这个时候你查一下binarize做preprocess的log就能发现,假如说发现在对test做binarize的时候出现很多的unk,那就可能是这个问题,然后,本次作业不是有个做back_translation吗,这个的话,就是为了增大en的数据集。
结语:本次作业是我第一次深切的感受到nlp,上一个作业就做的比较快,主要是调参,对conformer也只是看了论文,没有更深层的感受,但是这次作业的预处理,对embedding,rnn等的学习,我觉得对能力提升帮助十分大















 1074
1074











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









