







提出背景
改进了RNN的训练慢的缺点,利用self-attention机制实现并行计算。并且Transformer可以增加到非常深的深度,充分发掘DNN模型的特性,提升模型准确率。同时使用注意力机制更容易关注序列的全局特征,解决了RNN不善处理长距离依赖的问题
本质上是一个seq2seq的模型,因此可用于机器翻译,语音辨识,语音合成等问题
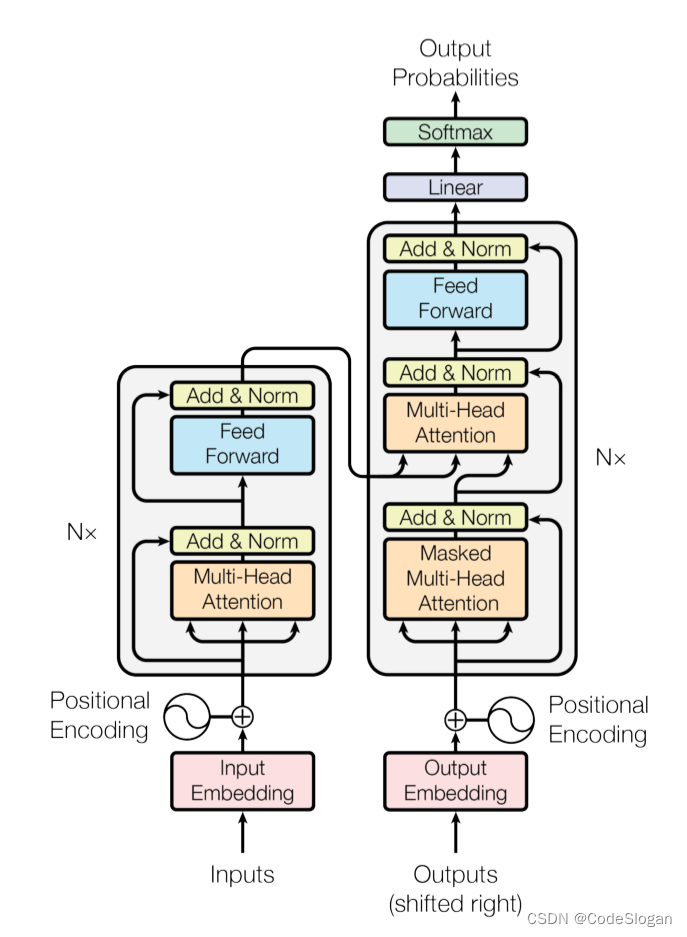
总体结构
整体结构由编码器与解码器组成,一个编码器中可有若干个编码层
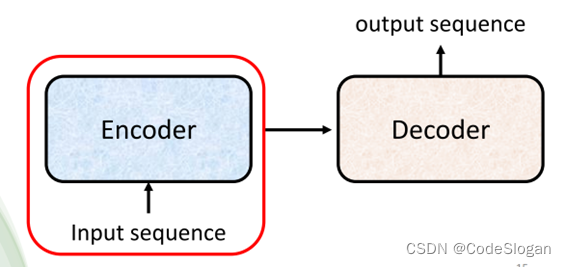
注意,Encoder中的参数各不相同
Encoder
编码器的作用在于,输入一个向量,输出一个等长的向量

要点:
- 使用多头注意力机制,关注全局输入向量的资讯
- 使用了残差及layer normalization,避免出现梯度消失问题
- 使用前向神经网络,每个位置的单词对应的前馈神经网络都完全一样
Self Attention
query,key,value全由输入向量自身计算得到的一种注意力机制。每一个输入向量分别对应了查询、键、值权重矩阵,用于生成查询、键、值向量,权重矩阵为训练参数

Decoder
输入有两部分
- 编码器最后一层的输出作为key和value
- 同时解码器自己的输入经过多头自注意力的计算作为query
输出为对应的结果序列
结构与编码器类似,唯一的不同在于Masked Multi-Head Attention使用了掩码机制,不再关注全局的资讯,而是只考虑了当前位置以及当前位置之前的信息,存在时序性
细节再探
-
Teacher forcing:将真实标签作为decoder的输入,依次预测结果,相当于把正确答案给解码器
-
掩码作用:考虑到Teacher forcing已经将正确答案输入到模型,因此在每次预测一个token时,需要将其及其之后的token先掩盖,保证训练任务和预测任务在执行自回归时,是同样的形式
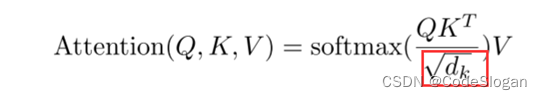
-
d
k
d_k
dk是query和key向量的维度
在计算注意力权重时除以 d k d_k dk,避免了随着 d k d_k dk的增大,即维度增大时,计算出的权重出现过大(softmax后的值非0即1)的情况,从而保留了数据原始的分布,可以使得梯度回传时更加平稳

- 使用layer normalize而非batch normalize:ln是针对一个样本内部做归一化;bn针对的是各个样本的特征做归一化,在文本长度变化较大时,这种归一化方式会造成均值方差抖动明显

- 多头self attention意在让根据词向量得出的query, key, value向量,进入不同的线性层(子空间),分别进行自注意力计算,捕捉全局丰富的语义信息,再将所有结果concat,拼接回原有的形状,最后再进入一个线性层得到结果
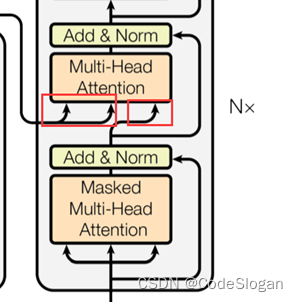
- 在decoder中计算自注意力时,query来自带有掩码的自注意力计算得出,而key和value来自encoder最后的输出,目的是让Decoder端的单词(token)给予Encoder端对应的单词(token)“更多的关注(attention weight)”

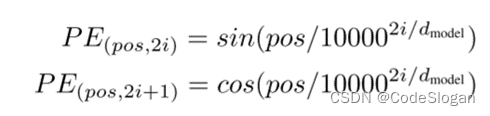
- 自注意力是基于全局信息进行计算,而忽略了时序信息(导致任意打乱句子中token的顺序,结果不变),位置编码PE解决了这一问题。PE的长度与embedding相同,使二者可以直接相加。
计算方式是根据token的文本中的位置,PE向量中偶数位使用sin计算,奇数位使用cos计算。由于三角函数公式不受序列长度的限制,也就是可以对比所遇到序列的更长的序列进行表示
源码阅读
主函数部分
确定了模型的输入部分,由两部分组成encoder的输入,decoder的输入
将token转换成id后以tensor形式传入模型

P代表填充码,S代表起始,E代表结束。对文本进行了id映射
模型参数初始化,选用交叉熵损失函数,Adam自适应学习率优化器
主模型定义
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder()
self.decoder = Decoder()
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False)
def forward(self, enc_inputs, dec_inputs):
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
dec_logits = self.projection(dec_outputs) # dec_logits : [batch_size x src_vocab_size x tgt_vocab_size]
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
由编码器,解码器及全连接层组成
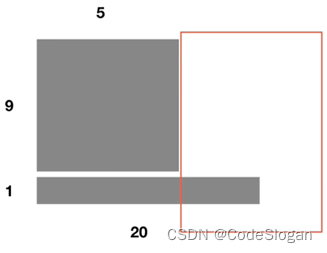
编码器输入 为1*5的张量,输出为1*5*512的张量(批量大小为1,文本长度为5,embedding向量维度为512),及注意力权重参数6*8*5*5
(6代表编码器中编码层的数量;8代表8头注意力,计算了8次,有8个子空间;5*5代表文本内部的相关性计算的结果)
解码器输入为编码器的输出及解码层输入文本
输出为注意力计算得出的结果(1*5*512),及解码器掩码自注意力权重参数及交互注意力权重参数
将解码器的输出作为全连接层的输入,通过全连接层将512维向量压缩成7维,对应翻译文本的长度(5*7)
编码器
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
# 词向量5*512
self.src_emb = nn.Embedding(src_vocab_size, d_model)
# 位置编码6*512
self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(src_len+1, d_model), freeze=True)
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
def forward(self, enc_inputs): # enc_inputs : [batch_size x source_len] [1*5]
enc_outputs = self.src_emb(enc_inputs) + self.pos_emb(torch.LongTensor([[1, 2, 3, 4, 0]]))
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs)
enc_self_attns = []
for layer in self.layers:
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns
定义词向量,位置向量,并将二者相加,传入编码层中迭代
位置向量由当前token所在文本中的位置计算得出
# n_position为文本长度,d_model为总向量维度
def get_sinusoid_encoding_table(n_position, d_model):
def cal_angle(position, hid_idx):
return position / np.power(10000, 2 * (hid_idx // 2) / d_model)
def get_posi_angle_vec(position):
return [cal_angle(position, hid_j) for hid_j in range(d_model)]
# 6*512
sinusoid_table = np.array([get_posi_angle_vec(pos_i) for pos_i in range(n_position)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
return torch.FloatTensor(sinusoid_table)
编码层
由多头自注意力层,以及前向神经网络组成
QKV均来自编码层输入的embedding
此时输入输出均为1*5*512
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, enc_inputs, enc_self_attn_mask):
# enc_input: torch.Size([1, 5, 512])
# enc_inputs to same Q,K,V
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask)
enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size x len_q x d_model]
# torch.Size([1, 5, 512])
return enc_outputs, attn
多头自注意力层
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads)
self.W_K = nn.Linear(d_model, d_k * n_heads)
self.W_V = nn.Linear(d_model, d_v * n_heads)
self.linear = nn.Linear(n_heads * d_v, d_model)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, Q, K, V, attn_mask):
# q: [batch_size x len_q x d_model], k: [batch_size x len_k x d_model], v: [batch_size x len_k x d_model]
# attn_mask: [1 x 5 x 5]
residual, batch_size = Q, Q.size(0)
# (B, S, D) -proj-> (B, S, D) -split-> (B, S, H, W) -trans-> (B, H, S, W)
# torch.Size([1, 8, 5, 64])
q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1, 2) # q_s: [batch_size x n_heads x len_q x d_k]
k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1, 2) # k_s: [batch_size x n_heads x len_k x d_k]
v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1, 2) # v_s: [batch_size x n_heads x len_k x d_v]
# 将mask从1*5*5复制为1*8*5*5
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size x n_heads x len_q x len_k]
# context: [batch_size x n_heads x len_q x d_v], attn: [batch_size x n_heads x len_q(=len_k) x len_k(=len_q)]
context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)
context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) # context: [batch_size x len_q x n_heads * d_v]
output = self.linear(context)
return self.layer_norm(output + residual), attn # output: [batch_size x len_q x d_model]
使用
W
Q
W_Q
WQ矩阵与Embedding相乘时,本质是将
W
Q
W_Q
WQ视为一个线性层,KV同理
多头计算的步骤是:先映射分头,再计算注意力权重
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
# padding负无穷
scores.masked_fill_(attn_mask, -1e9)
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
前馈神经网络层
在前向神经网络层中,使用一维卷积进行计算
原因在于当kernel_size=1,stride=1,padding=0时,与MLP的节点计算方式一样,变相实现了一个MLP
nn.Conv1d的输入数据格式只能以三维tensor[batch, channel, length]输入,与nn.Linear输入数据格式不同;
并且 nn.Conv1d的数据作用位置也不同,nn.Conv1d作用在第二个维度channel上,而nn.Linear作用于第三个维度
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, inputs):
residual = inputs # inputs : [batch_size, len_q, d_model]
# nn.Conv1d作用于第2个维度,因此要交换位置
output = nn.ReLU()(self.conv1(inputs.transpose(1, 2)))
output = self.conv2(output).transpose(1, 2)
return self.layer_norm(output + residual)
Masked
为解码层的自注意力加入掩码机制,使其无法查看当前及当前以后的序列
def get_attn_subsequent_mask(seq):
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
subsequent_mask = np.triu(np.ones(attn_shape), k=1)
subsequent_mask = torch.from_numpy(subsequent_mask).byte()
return subsequent_mask
解码器
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
# 7*512
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(tgt_len+1, d_model), freeze=True)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self, dec_inputs, enc_inputs, enc_outputs): # dec_inputs : [batch_size x target_len]
dec_outputs = self.tgt_emb(dec_inputs) + self.pos_emb(torch.LongTensor([[5, 1, 2, 3, 4]]))
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs)
dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs)
# 将掩码转换为bool类型
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0)
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs)
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers:
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs, dec_self_attns, dec_enc_attns
解码层
定义了两层注意力,分别为自注意力和交互注意力
其中自注意力为masked
交互注意力中,Q来自decoder,KV来自encoder
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
dec_outputs = self.pos_ffn(dec_outputs)
return dec_outputs, dec_self_attn, dec_enc_attn
















 1117
1117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











