






HADOOP集群搭建
安装lrzsz
[root@hdp01 hadoop]# yum -y install lrzsz
上传文件到hdp01:
首先在/home新建文件夹
[root@hdp01 home]# mkdir -p /home/hadoop/apps
将windows中的两个文件传到linux虚拟机中。
- rz
- 或者选中,拖拽到linux
ps(sz:将linux中的文件传到windows中。)
1集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起
-
HDFS集群: 负责海量数据的存储,集群中的角色主要有 NameNode / DataNode
-
YARN集群: 负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
-
(mapreduce是一个应用程序开发包)
-
服务器准备
- 本案例使用虚拟机服务器来搭建HADOOP集群,所用软件及版本: Vmware 11.0、Centos 6.5 、 64bit
-
网络环境准备
- 采用NAT方式联网 网关地址:192.168.72…2
- 3个服务器节点IP地址:192.168.72.101、192.168.72.120、192.168.72.130
- 子网掩码:255.255.255.0
-
服务器系统设置
- 设置主机名
- hdp01 hdp02 hdp03
- 配置内网域名映射: 192.168.91.107 hdp01
192.168.91.108 hdp02 192.168.91.109 hdp03
配置host文件
[root@hdp01 hadoop]# vi /etc/hosts `:
添加 192.168.72.101 hdp01 192.168.91.120 hdp02 192.168.91.130 hdp03 -
配置ssh免密登陆
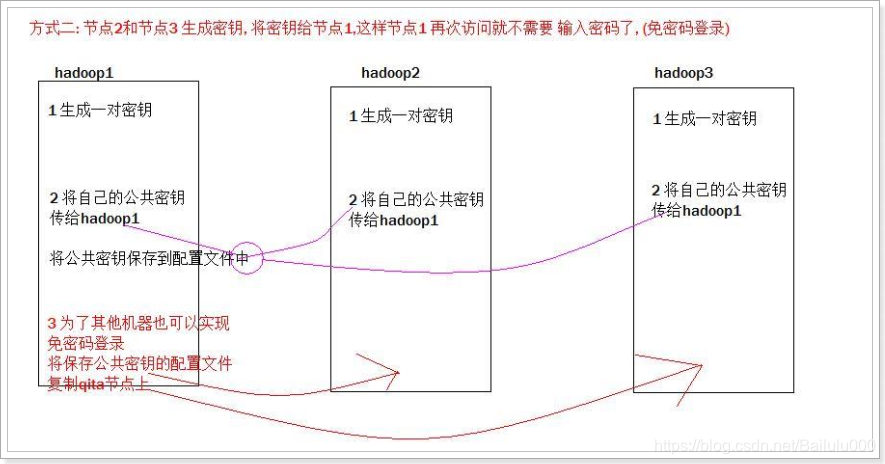
第一步:ssh-keygen -t rsa在hadoop1和hadoop2和hadoop3上面都要执行,产生公钥和私钥
第二步:ssh-copy-id hadoop1将公钥拷贝到hadoop1上面去第三步:
scp authorized_keys hadoop2: P W D s c p a u t h o r i z e d k e y s h a d o o p 3 : PWD scp authorized_keys hadoop3: PWDscpauthorizedkeyshadoop3:PWD
tip: 第三步需要在/root/.ssh/目录下. -
防火墙
-
重启防火墙
service iptables restart -
关闭防火墙服务
service iptables stop -
禁止防火墙关机自启动
chkconfig iptables off -
查看自启动状态
chkconfig iptables --list -
查看防火墙
service iptables status
-
-
Jdk环境安装
解压jdk
[root@hdp01apps]#tar -zxvf jdk-8u181-linux-x64.tar.gz
配置环境变量
[root@hdp01 jdk1.8.0_181]# vi /etc/profile
export JAVA_HOME=/home/hadoop/apps/jdk1.8.0_181 export
PATH= J A V A H O M E / b i n : JAVA_HOME/bin: JAVAHOME/bin:PATH
保存退出(Esc :wq)
[root@hdp01 jdk1.8.0_181]# vi /etc/profile
查看java是否存在
[root@hdp01 jdk1.8.0_181]# java -version
- 上传HADOOP安装包
Hadoop的安装包我们之前已经上传
解压安装包
[root@hdp01 apps]# tar -zxvf hadoop-2.8.0.tar.gz
修改配置文件
[root@hdp01 hadoop]# vi /etc/profile
添加一下内容:
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.8.0 export
PATH= P A T H : PATH: PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
[root@hdp01 hadoop]# source /etc/profile
[root@hdp01 hadoop]# hadoop version
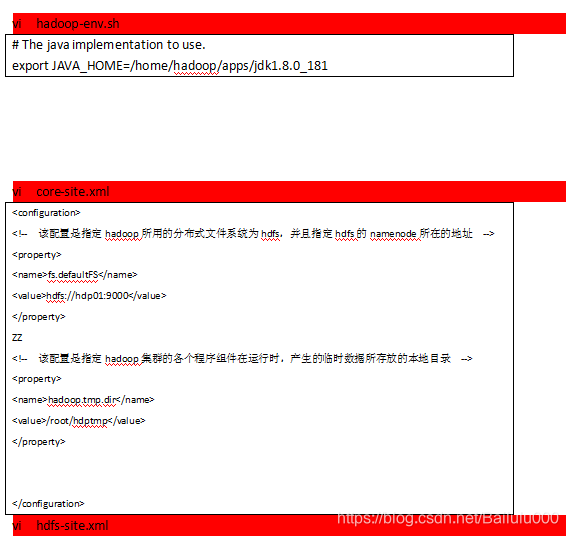
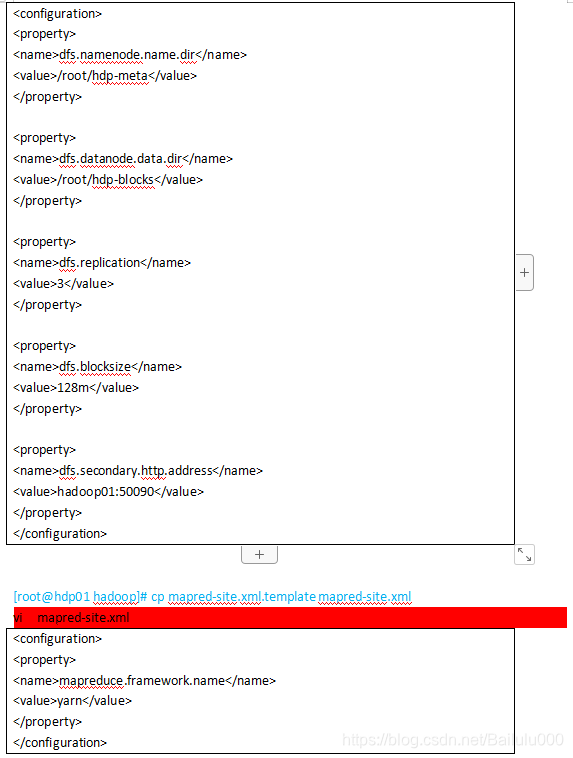
修改配置文件 /home/hadoop/apps/hadoop-2.8.0/etc/hadoop/
最简化配置如下:
[root@hdp01 hadoop]# cd /home/hadoop/apps/hadoop-2.8.0/etc/hadoop
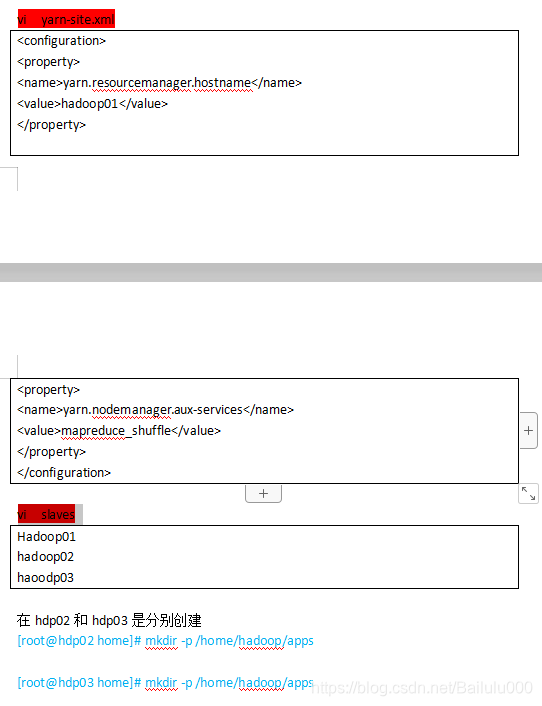
在hdp02和hdp03是分别创建
[root@hdp02 home]# mkdir -p /home/hadoop/apps
[root@hdp03 home]# mkdir -p /home/hadoop/apps
在hdp01上,经之前安装好jdk、/etc/profile 、 /etc/hosts
文件分别发送到hsp02和hdp03上
[root@hdp01 hadoop]# scp -r /home/hadoop/apps/jdk1.8.0_181/ hdp02:/home/hadoop/apps/
[root@hdp01 hadoop]# scp -r /home/hadoop/apps/jdk1.8.0_181/ hadp03:/home/hadoop/apps/
[root@hdp01 hadoop]# scp -r /home/hadoop/apps/hadoop-2.8.0 hdp02:/home/hadoop/apps/
[root@hdp01 hadoop]# scp -r /home/hadoop/apps/hadoop-2.8.0 hdp03:/home/hadoop/apps/
[root@hdp01 hadoop]# scp -r /etc/hosts hadoop02:/etc
[root@hdp01 hadoop]# scp -r /etc/hosts hadoop03:/etc
[root@hdp01 hadoop]# scp -r /etc/profile hadoop02:/etc/profile
[root@hdp01 hadoop]# scp -r /etc/profile hadoop03:/etc/profile
分别在hdp02、hdp03上执行以下命令
[root@hdp02 hadoop]# source /etc/profile
[root@hdp02 hadoop]# java -version
[root@hdp02 hadoop]# hadoop version
-
启动集群
在hdp01上执行
初始化HDFS[root@hdp01 hadoop]# hadoop namenode -format注:格式化hadoop,本质上是将namenode的元数据目录清空,恢复成初始状态
自动化脚本启动:
[root@hdp01 hadoop-2.8.0]# start-all.sh查看hadoop启动的线程:
在hdp01[root@hdp01 hadoop-2.8.0]# jps在hdp02
[root@hdp02 hadoop-2.8.0]# jps在hdp03
[root@hdp03 hadoop-2.8.0]# jpsnamenode在浏览器的界面
本文中had01,had02,had03都表示Hadoop01、Hadoop02、Hadoop03

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









