






 本文介绍了如何使用Python的pandas库处理数据,包括计算成绩的平均数(均值)、中位数,以及使用matplotlib绘制成绩的直方图来展示数据分布。还讨论了正态分布、偏态和离散趋势的概念,如方差、标准差和四分位数的应用。最后,涉及数据分类和pandas的category类型及其在数据预处理中的应用。
本文介绍了如何使用Python的pandas库处理数据,包括计算成绩的平均数(均值)、中位数,以及使用matplotlib绘制成绩的直方图来展示数据分布。还讨论了正态分布、偏态和离散趋势的概念,如方差、标准差和四分位数的应用。最后,涉及数据分类和pandas的category类型及其在数据预处理中的应用。
集中趋势
集中趋势,又被称为“数据的中心位置”。
它能够代表性的描绘总体数据的某一特征。通常用平均数来反映数据的集中趋势。
数值平均数,才是我们过往说的平均数,它更专业的名字,叫做“均值”。
位置平均数,指的是“中位数。
例如要获取成绩单里成绩的均值和中位数
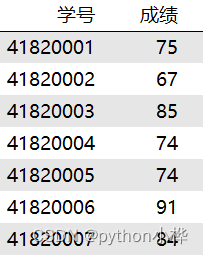
import pandas as pd
data = pd.read_csv(r"C:\Users\17585\Desktop\成绩单.csv")
# 使用mean()函数,获取成绩单的均值
mean = data["成绩"].mean()
# 使用median()函数,获取成绩的中位数
median = data["成绩"].median()
# 分别输出均值和中位数
print(mean)
print(median)
绘制直方图
直方图,是一种常用来展示数值数据分布的图表。
直方图和柱状图的区别:
1.直方图体现的是数据在各个区间的分布情况。而柱状图体现的是各个数据的变化趋势。
2.直方图x轴只能是数值型数据,而柱状图可以是类别型数据。
3.直方图是连续的图形分布,y轴是这一段区间内数量的总和。而柱状图是单一的柱形,y轴是这一个值对应的数量。
绘制直方图时,可以用plt.hist函数:
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv(r"C:\Users\17585\Desktop\成绩单.csv")
# 使用mean()函数,获取成绩单的均值
mean = data["成绩"].mean()
# 使用median()函数,获取成绩的中位数
median = data["成绩"].median()
# 分别输出均值和中位数
print(mean)
print(median)
# 绘制直方图,bins可以用来设置区间的数量
plt.hist(data["成绩"],bins=100)
plt.show()
正态与偏态
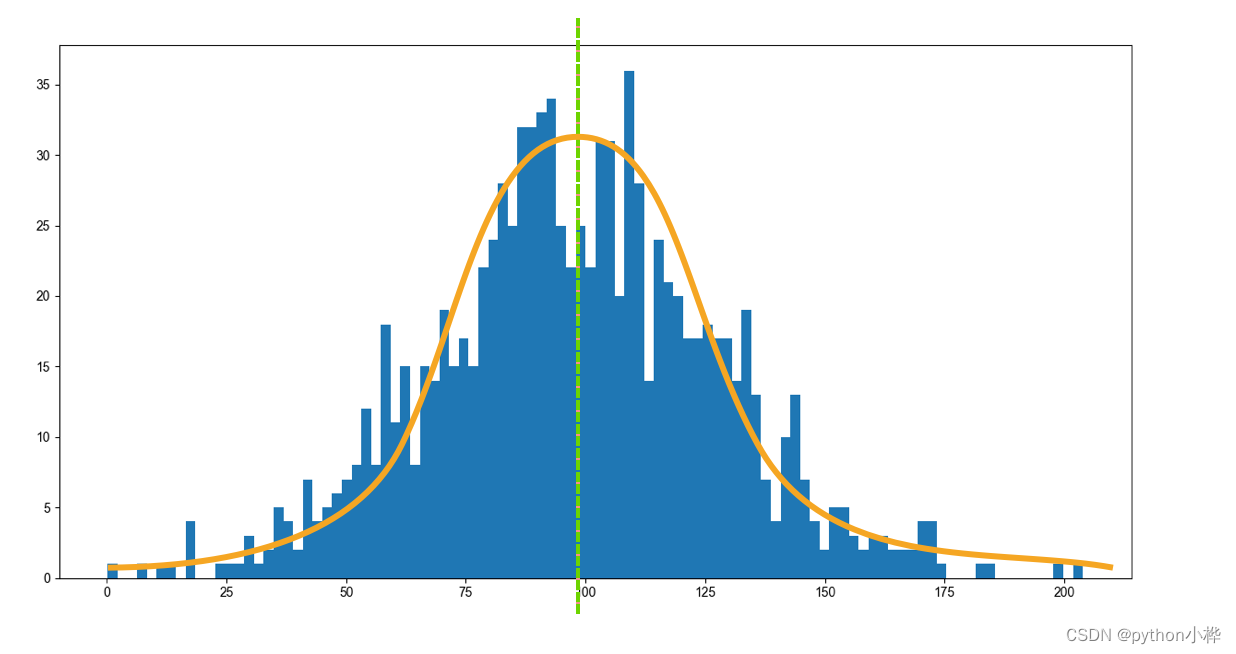
正态分布,是日常生活中最为常见的一种分布状态。
它的特点是数据的分布相对均匀,并且符合统计学集中的规律。
直方图左右对称,数据的均值、中位数都相等。
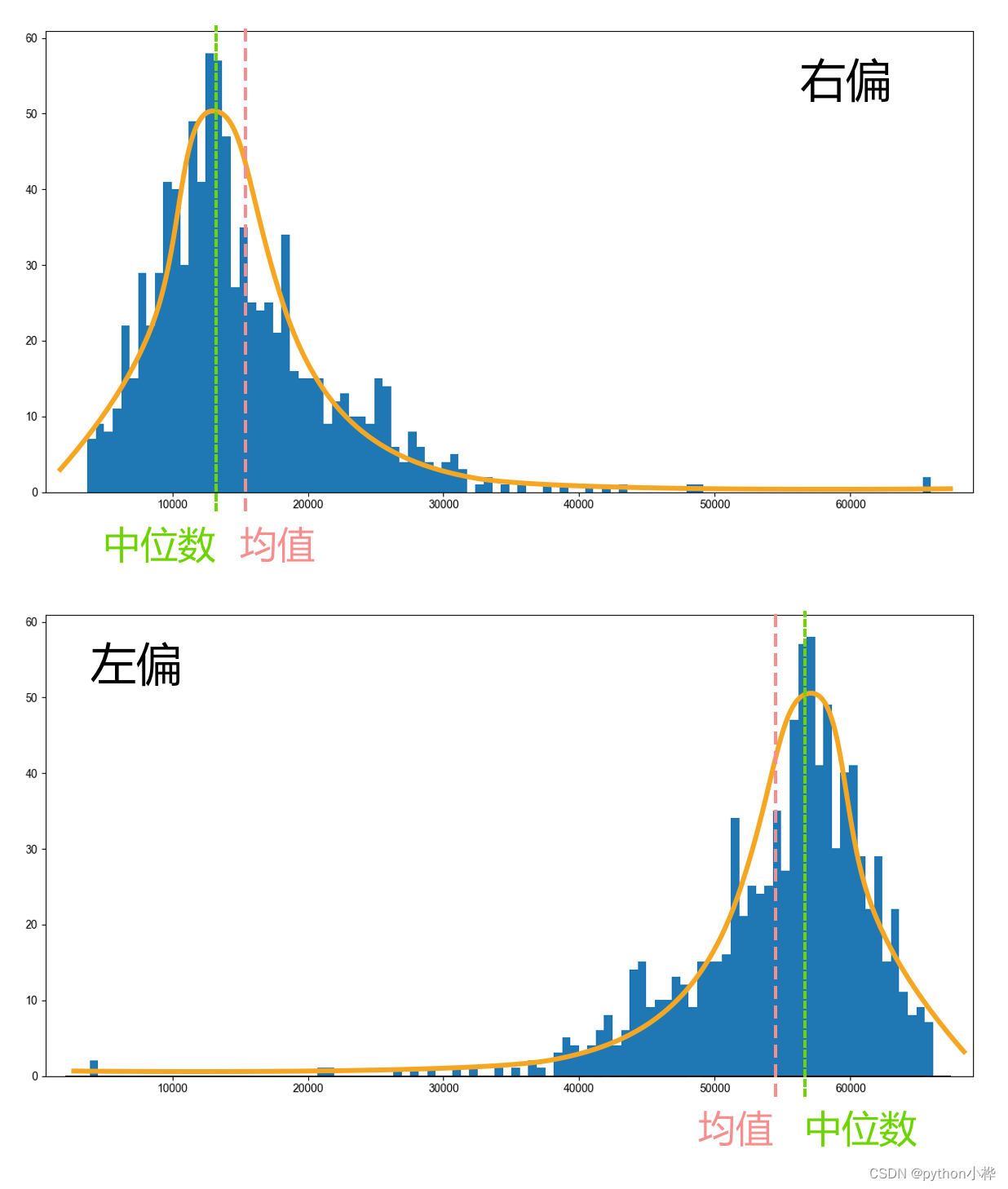
而偏态,就是指数据的分布状态,并不是完全对称的。由于一些极端大、极端小的数据影响,使得数据分布会出现向左偏或者向右偏。
偏态直接反映在中位数和均值的大小上。
右偏态:中位数<均值,均值被极端大的数据影响;
左偏态:均值<中位数,均值被极端小的数据影响。
离散趋势
离散趋势,能够代表性的描绘每个数据,偏离中心值的特征。
通常用方差,标准差和四分位数来反映数据的离散趋势。
方差:
描绘的是一组数据中,每个值偏离均值的状态。
方差的统计学意义可以看作是,每一个数据,和均值之间的距离的平方的均值。
import pandas as pd
data = pd.read_csv(r"C:\Users\17585\Desktop\成绩单.csv")
#计算方差
var = data["成绩"].var()
# 计算标准差
std = data["成绩"].std()
# 分别输出方差和标准差
print(var)
print(std)
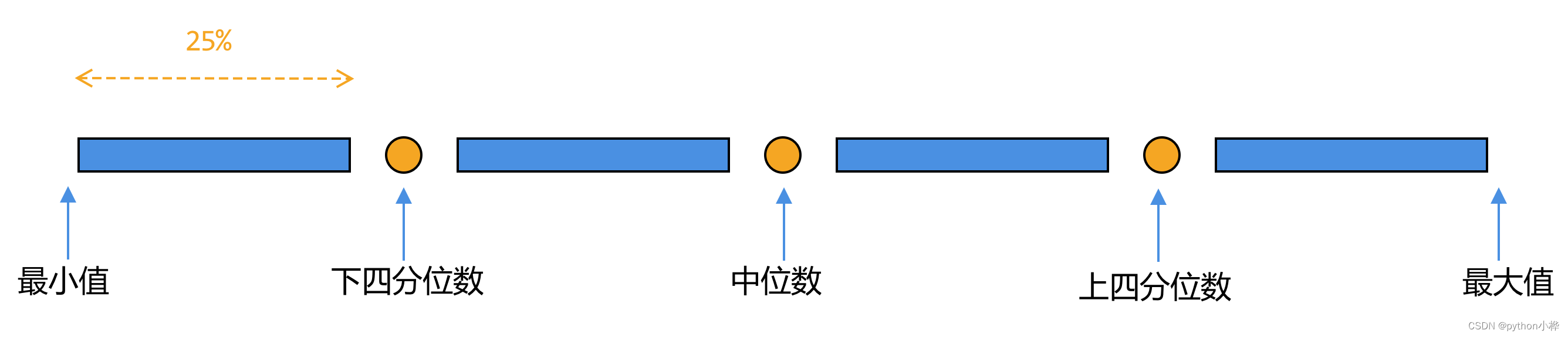
四分位数:
如果有一串数据,将这些数据从小到大排列,然后按照数据的数量进行四等分。每个部分各占25%的数据。
此时会产生3个分割点,这三个分割点,就叫四分位数。
和中位数描述的是“数据的中间位置,也就是二等分位置”一样,四分位数描述是“四等分位置”。
第一个四分位数,也就是25%的位置,叫做“下四分位数”。
第二个四分位数,也就是50%的位置,也就是“中位数”。
第三个四分位数,也就是75%的位置,叫做“上四分位”。
在pandas中,用describe()描述四分位数:
import pandas as pd
data = pd.read_csv(r"C:\Users\17585\Desktop\成绩单.csv")
# 使用describe()描述这一列的数据,并将其输出
result = data["成绩"].describe()
print(result)
#输出结果:
count 52.000000
mean 79.250000
std 8.077747
min 64.000000
25% 74.000000
50% 79.000000
75% 85.000000
max 92.000000
Name: 成绩, dtype: float64
count——数据数量
mean——均值
std——标准差
min——最小值
25%——下四分位数
50%——中位数
75%——上四分位数
max——最大值
数据分类
参数填写转换的类型,数据类型有:
- float (浮点型)
- int (整型)
- bool (布尔型)
- datetime64[ns] (日期时间)
- timedelta[ns] (时间差)
- category (有限长度的文本值列表)
- object (文本)
category:
一种不常见的类型——分类数据。
简单来说,就是一种取值为有限的,或者说是固定数量的可能值
这段代码的作用是统计"所在区域"列的频数分布。
import pandas as pd
data = pd.read_csv(r"C:\Users\17585\Desktop\成绩单.csv")
# 将成绩强制转化为分类型
data["成绩"] = data["成绩"].astype("category")
print(data["成绩"].value_counts)















 1013
1013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









