






NumPy
NumPy(Numerical Python的缩写)是一个开源的Python科学计算模块,其中包含了许多实用的数学函数,用来处理数值型数据。
属性
有很多属性可以描述N维数组,最常用的两个属性分别是数据类型和维度。
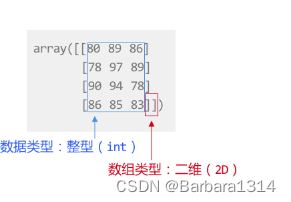
NumPy数组的数据类型指的是数组中存储的元素类型,可以是:整型(int)、浮点型(float)、布尔型(bool)等。
需要注意的是,NumPy数组中的所有元素类型必须是一致的。
维度
一维空间:一根直线,在这样的空间里,只能前进或者后退,所以只有长度的概念。
二维空间:一个平面,在这个平面上,除了前进后退,还可以向左或者向右,所以有长度和宽度的概念
三维空间:一个立方体,在这个空间里,除了前进后退,向左向右外,还可以向上或者向下移动,所以有长度,宽度和高度的概念。
NumPy数组的维度和我们平常说的维度非常相似,接触最多的通常是一维(1D)和二维(2D)数组,可以通过中括号[ ]的层数来确定。
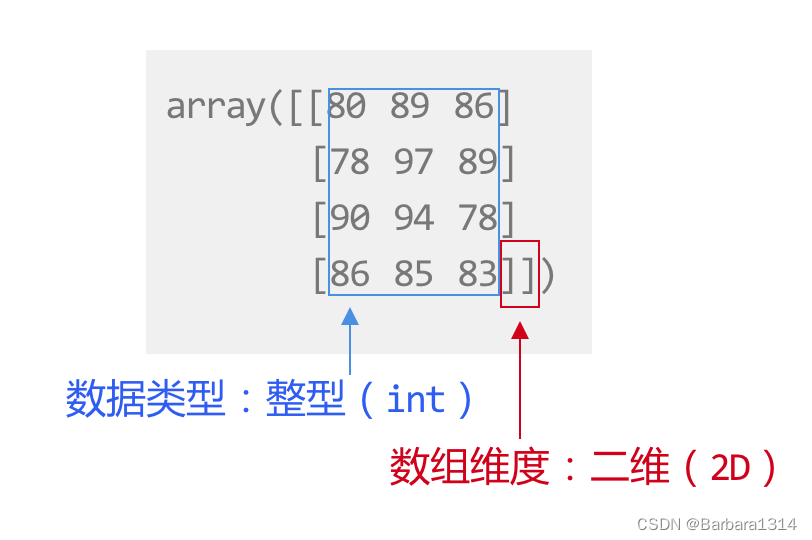
[…]表示一维数组,和Python中的列表长得很像。
在使用print()输出时,它们的区别在于数组之间的元素是用空格分隔,而列表是以逗号分隔。
一维数组的所有元素都在同一行里,一行可以有多个元素。
导入numpy
在终端上输入:pip install numpy即可
创建一维数组
最简单的方式是NumPy中的array()函数
arr = np.array([1,2,3,4,5])
print(arr) #输出:[1 2 3 4 5]
注意:
array()参数为任意序列型对象,也就是列表,元组,数组等数据结构,都可以作为参数传入,函数返回的一维数组赋值给了变量arr
数组打印出来后,数组之间的元素是用空格分隔。
数组算数
import numpy as np
arrOne = np.array([[0.2,0.9],[0.5,0.1],[0.1,0.7]])
arrTwo = np.array([[10,5],[20,5],[1,3]])
print(arrOne+2)
print(arrOne+arrTwo)

注意:
当数组和数字计算时,NumPy会将该数字的计算过程应到数组的所有元素上
当相同形状的数组进行计算时,运算也是在相应的元素上进行。
Pandas
安装Pandas
在终端输入:pip install pandas
Series
定义:
Series,中文叫做序列,pandas模块的一种数据类型,是一个一维的,带索引的数组对象
注意点:
- Series的值可以是多种数据类型:字符串,整型,浮点型,布尔型
- 一个Series在print输出时,值的数据类型在底部,用dtype表示出来
- 一个Series里的所有值,数据类型都是一样的
import pandas as pd
# 构建一个Series数据
info = pd.Series([111,222,333,444],index = ['F','S','T','F'])
# 位置索引
print(info[0]) # 输出111
# 标签索引
print(info["S"]) # 输出222
1.位置索引访问。这种访问方式和列表相同,是基于元素自身的下标来进行访问。
2.索引标签访问。这种访问方式和字典相同,把index中的索引标签当做字典的key
Series的三种属性
1.dtype
我们访问Series对象的dtype属性,可以返回Series对象的数据类型,
2.values
我们访问Series对象的values属性,会以数组的形式返回Series对象的值values
3.index
我们访问Series对象的index属性,可以返回这个Series的索引index。
import pandas as pd
info = pd.Series([111,222,333,444],index = ['FI',"SE","TH","FO"])
# 输出了info中的数据的类型
print(info.dtype)
# 输出了info中的值values
print(info.values)
# 输出了info的索引index
print(info.index)

DataFrame
DataFrame的轴
轴:是用来为超过一维的数组定义属性
对于DataFrame而言:
第0轴垂直向下,即axis=0是垂直方向的操作
第1轴水平向右,即axis=1是水平方向进行操作
DataFrame的定义
中文是数据框
是一个二维的矩阵数据表,通过行和列。可以定位一个值
定位
既有行索引(index),可以用来定位到具体的某一行
也有列索引(columns),用来定位到具体的某一列
通过index和columns,可以定位到一个值,能快速进行数据的筛选和定位到一个值,能快速进行数据的筛选和定位
DataFrame构造函数
df = pd.DataFrame(data,index=city)
第一个参数:
data,表示需要传入的数据,可以使字典,列表等。若不传入,会生成一个空的DataFrame。
第二个参数:
index,用于定义DataFramed的行索引。只需要将一个列表赋值给参数index.
如果不传入参数,index就会从0开始生成
import pandas as pd
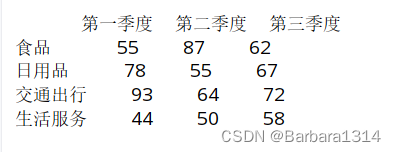
data = {'第一季度':[55,78,93,44],'第二季度':[87,55,64,50],'第三季度':[62,67,72,58]}
cost = ["食品","日用品","交通出行","生活服务"]
df = pd.DataFrame(data,index=cost)
print(df)
DataFrame的3中常用属性
1.dtypes
访问dtypes,可以返回DataFrame的每一列数据的数据类型
2.values
访问values,会以数组的形式返回DataFrame对象的值
3.index
访问index,获取它的行索引index
import pandas as pd
data = {'rank':[1,2,3,4],'GDP':[80888,77754,68452,47854]}
city = ['GD','JS','SD','ZH']
# 构造DataFrame赋值给df
df = pd.DataFrame(data,index=city)
# 输出dtypes属性
print(df.dtypes)
# 输出values属性
print(df.values)
# 输出index属性
print(df.index)
















 924
924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









