






1. Transformer
Transformer 是当今大多数 NLP 应用程序(例如 BERT、MUM 和 GPT-3)中的主要架构。不仅在NLP领域中, Transformer的架构也大量应用于感知检测方面, 如ViT, Swin-Transformer, BEVFusion和DETR3D等。
1.1框架
Transformer 是通过对序列化数据分析来学习上下文和理解的神经网络。 Transformer 模型使用注意力或自注意力机制。 这一机制有助于确定与当前序列相隔较远的数据元素如何相互影响和依赖。整体的Transformer架构如图1.1 所示。

图1.1
Transformer 有两个主要组件:
Encoder Stacks — Nx个相同的编码器层(在论文中,Nx = 6)
Decoder Stacks — Nx个相同的解码器层(在论文中,Nx =6)
模型不包括递归或卷积,因此Encoder和Decoder之间有一个额外的位置编码层,以利用序列的顺序。
在较高的层次上,编码器将输入序列映射为抽象的连续表示,该表示保存该输入的所有学习信息。 然后,解码器采用该连续表示并逐步生成单个输出,同时还提供先前的输出。
1.2 Pipeline
1.2.1输入嵌入层
第一步是将输入词输入到词嵌入层。 单词嵌入层可以被认为是一个查找表,用于获取每个单词的学习向量表示。 神经网络通过数字进行学习,因此每个单词都会映射到一个具有连续值的向量来表示该单词。如图1.2.1所示。

图1.2.1 将单词转换为输入嵌入
1.2.2 位置编码
下一步是将位置信息注入。 由于 Transformer 编码器没有像循环神经网络那样的循环,因此必须在输入嵌入中添加一些有关位置的信息。 这是使用位置编码完成的。 作者利用正弦和余弦函数想出了一个巧妙的技巧。
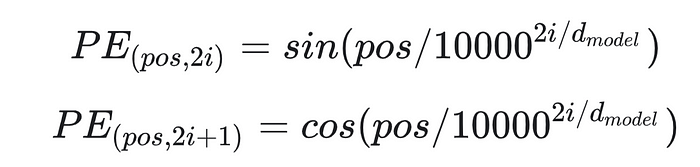
对于输入向量上的每个奇数索引,使用 cos 函数创建一个向量。对于每个偶数索引,使用 sin 函数创建一个向量。然后将这些向量添加到其相应的输入嵌入中。这成功地向网络提供了每个向量位置的信息。 串联选择正弦和余弦函数是因为它们具有模型可以轻松学习关注的线性属性。
1.2.3 编码层
现在有了编码器层。 编码器层的工作是将所有输入序列映射到一个抽象的连续表示中,该表示保存整个序列的学习信息。 它包含2个子模块,多头注意力,后面是一个全连接的网络。 两个子层周围还存在残余连接,然后进行层归一化。如图1.2.3-1所示。
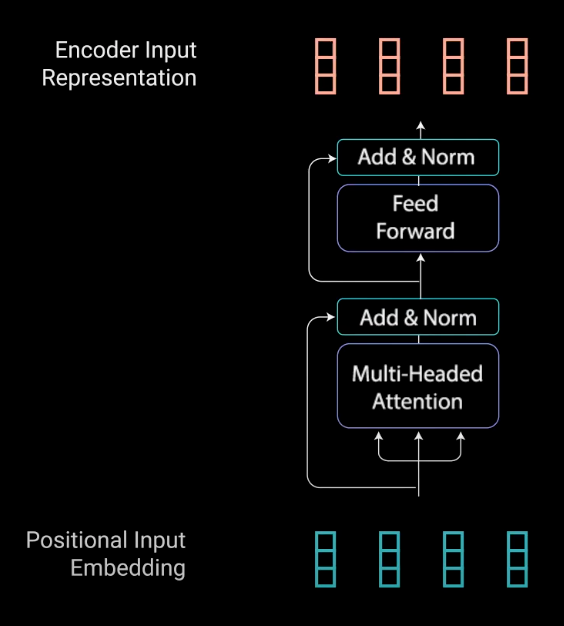
图1.2.3-1 编码器
Encoder由 6 层组成,每层有两个子层组成。 第一个是多头自注意力机制,第二个是简单的位置级全连接前馈网络。 在两个子层周围采用残差连接,然后进行层归一化。如图1.2.3-2所示。

图1.2.3-2 自注意力 & 全连接前馈网络
每个子层的输出是
LayerNorm(x + Sublayer(x)),
其中Sublayer(x)是子层本身实现的函数。
在第二个子层中,有一个完全连接的前馈网络,其中包含两个散布着修正线性单元(ReLU)激活的线性变换。

输入序列中的每个单词都由 Transformer 编码器的六层逐个翻译。 然而,每一层都使用自己的权重(W1,W2)和偏差(b1,b2)参数来发挥作用。
这两个子层周围还存在残余连接。 除了每个子层之外,还有一个归一化层,layernorm(.),其功能是对子层输入 X 以及子层输出本身 sublayer(X) 之间计算的和进行归一化
为了理解这个问题,首先看一下多头注意力模块。
1.2.3.1多头注意力
编码器中的多头注意力应用了一种称为自注意力的特定注意力机制。 自注意力允许模型将输入中的每个单词与其他单词相关联。 因此,在的示例中,的模型可能可以学习将“you”一词与“how”和“are”相关联。 该模型也有可能了解到以这种模式构建的单词通常是一个问题,因此做出适当的回答。
1.2.3.2查询、键和值向量
为了实现自注意力,将输入,输入到 3 个不同的全连接层中以创建查询、键和值向量。如图2.1.3.2所示。
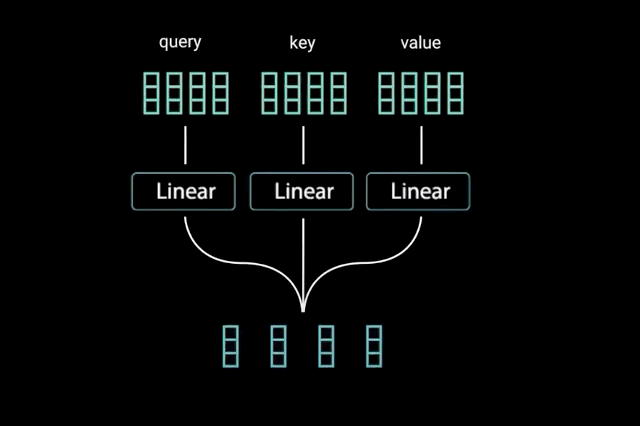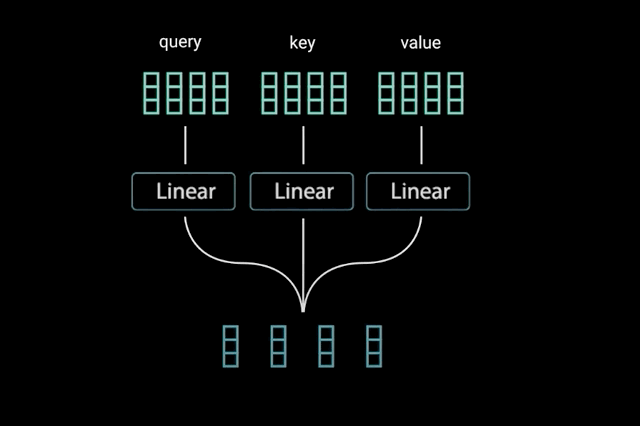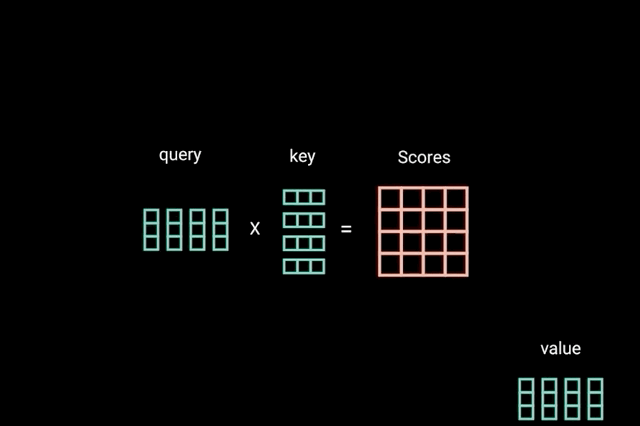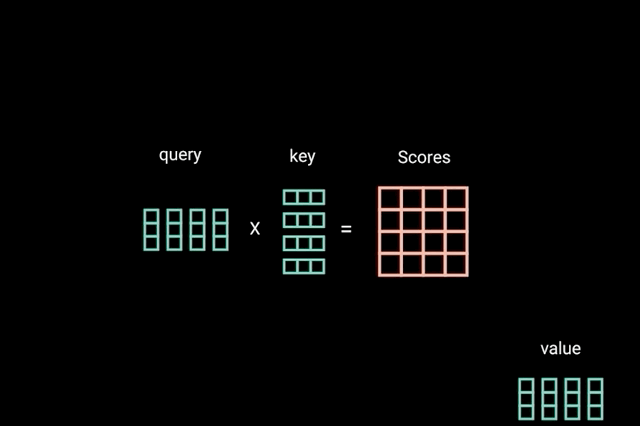
图1.2.3.2
“查询键和值的概念来自检索系统。 例如,当您输入查询来搜索 Youtube 上的某个视频时,搜索引擎会将您的查询映射到与数据库中与候选视频相关的一组键(视频标题、描述等),然后向您呈现最匹配的内容 视频(值)。
1.2.3.3查询和键的点积
在将查询、键和值向量输入线性层后,查询和键进行点积矩阵乘法以生成分数矩阵。如图1.2.3.3-1所示。

图1.2.3.3-1 查询和键的点积乘法
分数矩阵决定了一个词对其他词的关注程度。 因此,每个单词都会有一个与时间步中的其他单词相对应的分数。 分数越高越集中。 这就是查询映射到键的方式。如图1.2.3.3-2所示

图1.2.3.3-2 点积的注意力得分
1.2.3.4降低注意力分数
然后,通过除以查询和键维度的平方根来缩小分数。 这是为了获得更稳定的梯度,因为相乘的值可能会产生爆炸性的效果。计算如图1.2.3.4所示。

图1.2.3.4 降低注意力分数
1.2.3.5归一化
接下来,采用softmax 来获取注意力权重,这会为您提供 0 到 1 之间的概率值。通过进行 softmax,较高的分数会提高,较低的分数会降低。 这使得模型对于要关注哪些单词更加有信心。计算公式如图1.2.3.5所示。

图1.2.3.5 采用softmax 来获取概率值
1.2.3.6 Softmax 输出与值向量相乘
然后,获取注意力权重并将其乘以值向量以获得输出向量。 softmax 分数越高,模型学习的单词的价值就越重要。 较低的分数会淹没不相关的单词。 然后将其输出输入线性层进行处理。如图1.2.3.6所示。

图1.2.3.6
1.2.3.7多头注意力计算
为了使其成为多头注意力计算,需要在应用自注意力之前将查询、键和值拆分为 N 个向量。 然后,分割向量分别经历自注意力过程。 每个自注意力过程称为头。 每个头都会产生一个输出向量,该向量在经过最终线性层之前连接成单个向量。 理论上,每个头都会学习不同的东西,从而赋予编码器模型更多的表示能力。
总而言之,多头注意力是 Transformer 网络中的一个模块,它计算输入的注意力权重,并生成一个输出向量,其中包含有关每个单词应如何关注序列中所有其他单词的编码信息。
1.2.3.8剩余连接、层标准化和前馈网络
将多头注意力输出向量添加到原始位置输入嵌入中。 这称为残差连接。 残差连接的输出经过层归一化。
归一化的残差输出通过逐点前馈网络进行投影以进行进一步处理。 逐点前馈网络是几个线性层,中间有一个 ReLU 激活。 然后,其输出再次添加到逐点前馈网络的输入并进一步归一化。
残余连接允许梯度直接流经网络,从而帮助网络训练。 层归一化用于稳定网络,从而大大减少所需的训练时间。 逐点前馈层用于投影注意力输出,可能为其提供更丰富的表示。
1.2.3.9 编码器层总结
所有这些操作都是将输入编码为带有注意力信息的连续表示。 这将有助于解码器在解码过程中专注于输入中的适当单词。 您可以将编码器堆叠 N 次以进一步编码信息,其中每一层都有机会学习不同的注意力表示,因此有可能提高 Transformer 网络的预测能力。
1.2.4解码器
解码器的工作是生成文本序列。 解码器具有与编码器类似的子层。 它有两个多头注意力层、一个点前馈层、残差连接以及每个子层之后的层归一化。 这些子层的行为与编码器中的层类似,但每个多头注意力层都有不同的工作。 解码器由充当分类器的线性层和用于获取单词概率的 softmax 覆盖。解码器框架如图1.2.4所示。

图1.2.4 解码器层
解码器是自回归的,它以开始标记开始,并接受先前输出的列表作为输入,以及包含来自输入的注意信息的编码器输出。 当解码器生成令牌作为输出时,解码器停止解码。
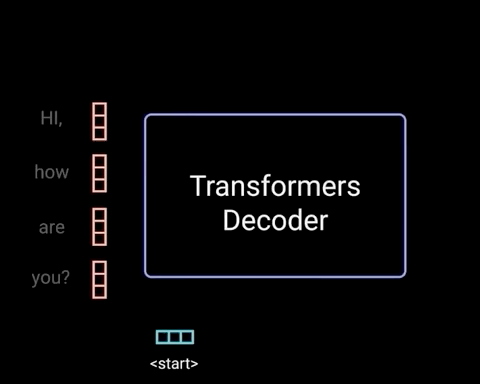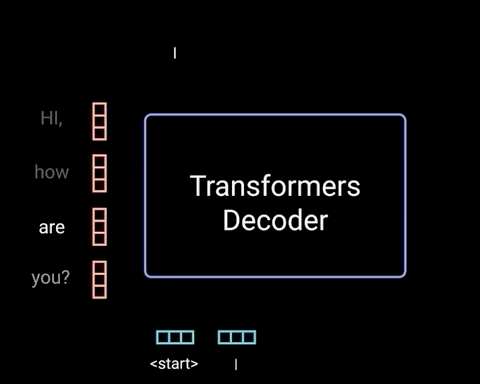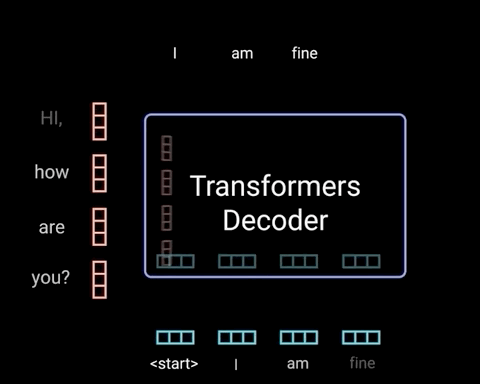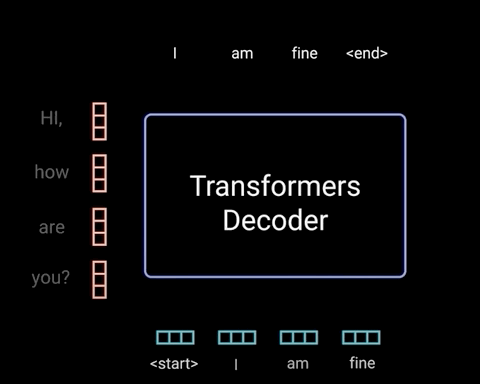
解码器是自回归的,因为它在输入之前的输出时一次生成一个令牌 1。
1.2.4.1解码器输入嵌入和位置编码
解码器的开始与编码器几乎相同。 输入经过嵌入层和位置编码层以获得位置嵌入。 位置嵌入被输入到第一个多头注意力层,该层计算解码器输入的注意力分数。
1.2.4.2解码器首次多头注意力
这个多头注意力层的运作方式略有不同。 由于解码器是自回归的并逐字生成序列,因此您需要防止它对未来的标记进行调节。 例如,当计算单词“am”的注意力分数时,您不应该访问单词“fine”,因为该单词是之后生成的未来单词。 “am”这个词只能访问它本身和它前面的单词。 对于所有其他单词都是如此,它们只能关注前面的单词。

Decoder 的第一个多头注意力的描述缩放了注意力分数。 “am”一词不应代表“fine”一词。 对于所有其他词来说都是如此。
需要一种方法来防止计算未来单词的注意力分数。 这种方法称为掩蔽。 为了防止解码器查看未来的令牌,您可以应用前瞻掩码。 在计算 softmax 之前和缩放分数之后添加掩码。 让看看这是如何工作的。
1.2.4.3前瞻掩模
掩码是一个与注意力分数大小相同的矩阵,其中填充了 0 和负无穷值。 将掩码添加到缩放后的注意力分数时,会得到一个分数矩阵,其中右上角的三角形填充了负无穷大。

将前瞻掩码添加到缩放分数中
使用掩码的原因是,一旦采用掩码分数的 softmax,负无穷大就会被清零,为未来的标记留下零注意力分数。 如下图所示,“am”的注意力分数对其本身及其之前的所有单词都有值,但单词“fine”的注意力分数为零。 这本质上告诉模型不要关注这些单词。

这种掩蔽是第一个多头注意力层中注意力分数计算方式的唯一区别。 该层仍然有多个头,在连接并通过线性层进行进一步处理之前,将对其应用掩模。 第一个多头注意力的输出是一个掩码输出向量,其中包含有关模型应如何参与解码器输入的信息。

1.2.4.4输出概率的线性分类器和最终 Softmax
最终逐点前馈层的输出经过最终线性层,该线性层充当分类器。 分类器的大小与您拥有的类的数量一样大。 例如,如果您有 10,000 个单词的 10,000 个类,则该分类器的输出大小将为 10,000。 然后分类器的输出被输入到 softmax 层,该层将产生 0 到 1 之间的概率分数。采用最高概率分数的索引,它等于的预测单词。
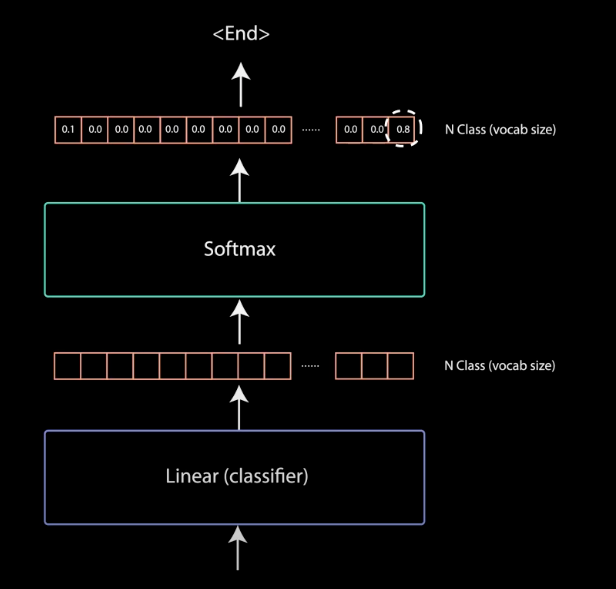
使用 Softmax 的线性分类器来获取输出概率
然后解码器获取输出,将其添加到解码器输入列表中,并再次继续解码,直到预测到令牌为止。 对于的例子,最高概率的预测是分配给结束标记的最终类别。
解码器还可以堆叠 N 层,每一层接收来自编码器及其之前各层的输入。 通过堆叠各层,模型可以学习从其注意力头中提取并关注不同的注意力组合,从而可能提高其预测能力。
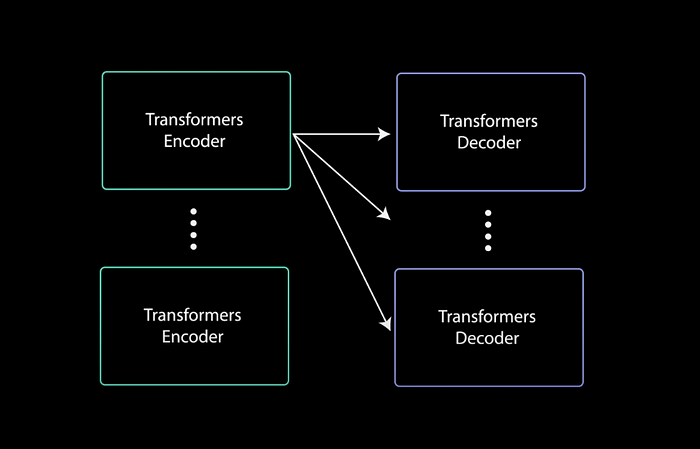
堆叠式编码器和解码器















 2342
2342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











