







介绍
本文将介绍CapsNet的体系结构,我同时尝试计算CapsNet的可训练参数数目。结果是大约820万可训练参数,与论文中的数字(113万6千)不同。论文本身不是很详细,没有涉及一些网络实现的具体设定,因此有一些问题我至今没有搞清楚(论文作者没有提供代码)。不管怎么说,我仍然认为计算网络的参数本身是一个很好的学习过程,因为它帮助人们理解特定架构的所有构建模块。
CapsNet由两部分组成:编码器和解码器。前3层是编码器,后3层是解码器:
- 第一层:卷积层
- 第二层:PrimaryCaps(主胶囊)层
- 第三层:DigitCaps(数字胶囊)层
- 第四层:第一全连接层
- 第五层:第二全连接层
- 第六层:第三全连接层
第一部分 编码器
 CapsNet编码器架构,图片来源:原论文
CapsNet编码器架构,图片来源:原论文
上图中,网络的编码器部分接受一张28x28的MNIST数字图像作为输入,学习将它编码为由实例参数构成的16维向量(本系列前面几篇文章解释了这一过程),这也是胶囊进行工作的所在。预测输出是由DigitCaps输出的长度构成的10维向量。
第一层 卷积层
输入:28x28图像(单色)
输出:20x20x256张量
参数:20992
卷积层检测2D图像的基本特征。在CapsNet中,卷积层有256个步长为1的9x9x1核,使用ReLU激活。如果你不明白这句话是什么意思,这里有一些很棒的资源让你快速掌握卷积背后的关键概念。计算参数时,别忘了卷积层中的每个核有1个偏置项。因此这一层共有(9x9+1)x256 = 20992个可训练参数。
第二层 PrimaryCaps层
输入:20x20x256张量
输出:6x6x8x32张量
参数:5308672
这一层包含32个主胶囊,接受卷积层检测到的基本特征,生成特征的组合。这一层的32个主胶囊本质上和卷积层很相似。每个胶囊将8个9x9x256卷积核应用到20x20x256输入张量,因而生成6x6x8输出张量。由于总共有32个胶囊,输出为6x6x8x32张量。这一层共有5308672个可训练参数(计算过程与上一层类似)。
第三层 DigitCaps层
输入:6x6x8x32张量
输出:16x10矩阵
参数:1497600
这一层包含10个数字胶囊,每个胶囊对应一个数字。每个胶囊接受一个6x6x8x32张量作为输入。你可以把它看成6x6x32的8维向量,也就是1152输入向量。在胶囊内部,每个输入向量通过8x16权重矩阵将8维输入空间映射到16维胶囊输出空间。因此,每个胶囊有1152矩阵,以及用于动态路由的1152 c系数和1152 b系数。乘一下:1152 x 8 x 16 + 1152 + 1152,每个胶囊有149760可训练参数,乘以10得到这一层最终的参数数目。
损失函数
损失函数乍一看很复杂,但实际上并非如此。 它与SVM损失函数很像。回想一下,DigitCaps层的输出是10个16维向量,这有助于理解损失函数是如何工作的。训练时,对于每个训练样本,根据下面的公式计算每个向量的损失值,然后将10个损失值相加得到最终损失。我们正在讨论监督学习,所以每个训练样本都有正确的标签,在这种情况下,它将是一个10维one-hot编码向量,该向量由9个零和1个一(正确位置)组成。在损失函数公式中,正确的标签决定了Tc的值:如果正确的标签与特定DigitCap的数字对应,Tc为1,否则为0。
 给原论文中的公式加上色彩
给原论文中的公式加上色彩
假设正确的标签是1,这意味着第一个DigitCap负责编码数字1的存在。这一DigitCap的损失函数的Tc为1,其余9个DigitCap的Tc为0。当Tc为1时,损失函数的第二项为零,损失函数的值通过第一项计算。在我们的例子中,为了计算第一个DigitCap的损失,我们从m+减去这一DigitCap的输出向量,其中,m+取固定值0.9。接着,我们保留所得值(仅当所得值大于零时)并取平方。否则,返回0。换句话说,当正确DigitCap预测正确标签的概率大于0.9时,损失函数为零,当概率小于0.9时,损失函数不为零。
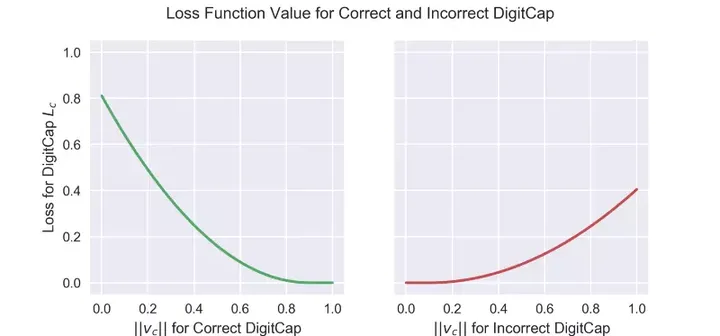 正确与不正确DigitCap的损失函数的值。注意,红线没有绿线那么陡峭,这是由于等式中的lambda系数
正确与不正确DigitCap的损失函数的值。注意,红线没有绿线那么陡峭,这是由于等式中的lambda系数
对不匹配正确标签的DigitCap而言,Tc为零,因此将演算第二项。在这一情形下,DigitCap预测不正确标签的概率小于0.1时,损失函数为零,预测不正确标签的概率大于0.1时,损失函数不为零。
最后,公式包括了一个lambda系数以确保训练中的数值稳定性(lambda为固定值0.5)。这两项取平方是为了让损失函数符合L2正则,看起来作者们认为这样正则化一下效果更好。
第二部分 解码器
 CapsNet解码器架构,来源:原论文
CapsNet解码器架构,来源:原论文
解码器从正确的DigitCap中接受一个16维向量,并学习将其解码为数字图像(请注意,它在训练时仅使用正确的DigitCap向量,忽略不正确的DigitCap)。解码器被用来作为正则子,它接受正确的DigitCap的输出作为输入,并学习重建一张28×28像素的图像,损失函数为重建图像与输入图像之间的欧氏距离。解码器强制胶囊学习对重建原始图像有用的特征。重建图像越接近输入图像越好。下图展示了一些重建图像的例子。
 上为原始图像,下为重建图像。来源:原论文
上为原始图像,下为重建图像。来源:原论文
第四层 第一全连接层
输入:16x10
输出:512
参数:82432
低层的每个输出加权后传导至全连接层的每个神经元作为输入。每个神经元同时具备一个偏置项。16x10输入全部传导至这一层的512个神经元中的每个神经元。因此,共有(16x10 + 1)x512可训练参数。
以下两层的计算与此类似:参数数量 = (输入数 + 偏置) x 层中的神经元数。
第五层 第二全连接层
输入:512
输出:1024
参数:525312
第六层 第三全连接层
输入:1024
输出:784(重整后重建28x28解码图像)
参数:803600
网络中的参数总数:8238608
转自知乎:https://zhuanlan.zhihu.com/p/33955995















 2301
2301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









