









一. Transformer介绍
1. 处理Sequence数据
要处理一个Sequence,最常想到的就是使用RNN,它的输入是一串vector sequence,输出是另一串vector sequence。假设是一个single directional的RNN,那当输出b4时,默认a1-a4都已经看过了。
RNN非常擅长于处理input是一个sequence的状况。但RNN很不容易并行化 (hard to parallel)。
为此,有人提出用CNN代替RNN。橘色的三角形表示一个filter,每次扫过3个向量a,扫过一轮以后,就输出了一排结果,使用橘色的小圆点表示。
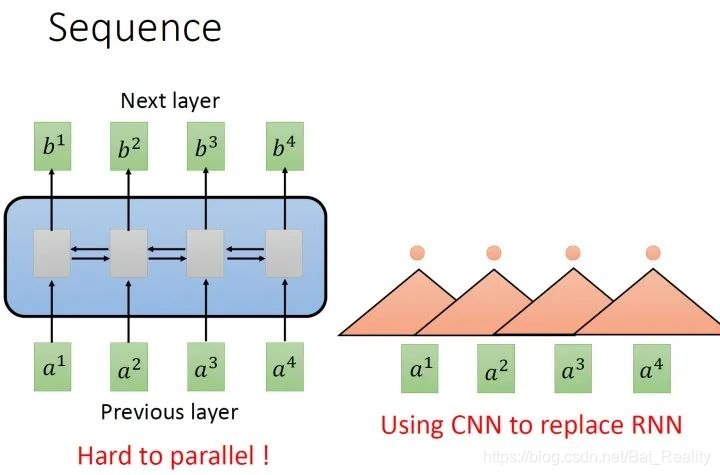
表面上CNN和RNN可以做到相同的输入和输出,但是CNN只能考虑非常有限的内容。如果想看到更多资讯,就必须要叠很多层filter,才可以看到长时的资讯。
为了解决上述问题,研究者就提出了self-attention layer。它可以并行化计算,且速度较快。
2. self-attention
a. 获得初始化矩阵
首先,每一个input (vector)先乘上一个矩阵
W
{W}
W 得到embedding。接着这个embedding进入self-attention层,权重系数与矩阵
a
{a}
a 相乘,分别得到矩阵q(查询)、k(键)、v(值)。

b. query对key做attention
每一个query对key做attention,而attention就是匹配这2个向量有多接近,可以用scaled inner product对两个向量做点积。两个向量做点积,数值越大,代表两个向量越接近。 因为q*k的数值会随着dimension的增大而增大,所以要除以√d。对于每一行来说,每一个元素表示的意义为:该行所表示的单词与其他单词的关联性。将所有字的信息融入到当前element中。,所以需要进行softmax归一化操作。




c. 获取sequence信息
得到
a
^
i
,
1
\hat{a}_{i, 1}
a^i,1后,分别与
v
i
{v}^{i}
vi相乘,即
a
^
1
,
1
\hat{a}_{1, 1}
a^1,1与
v
1
{v}^{1}
v1相乘、
a
^
4
,
1
\hat{a}_{4, 1}
a^4,1与
v
4
{v}^{4}
v4相乘。将结果都加起来就能得到
b
1
{b}^{1}
b1,所以
b
1
{b}^{1}
b1获得了整个sequence的资讯。

d. self-attention流程

3. Multi-head Self-attention
多头attention机制就是进行多次attention(此时的权重矩阵W不一样),然后对获得的值进行concat处理,最后通过一个transformation matrix调整维度。
注:embedding dimension 需要能够整除 head 的数量,多头模式实质是将原来的矩阵进行了切割。head size = embedding dimension ./ num of head



不同的head可能关注不同的信息。

4. 位置向量(Positional Encoding)
到现在,self-attention已经能够获取到sequence的全局信息,也能够实现并行化了,那它还有什么不足呢?
一个“近在咫尺”位置的单词向量和“远在天涯”位置的单词向量位效果是一样的,没有位置信息。
如果输入"A喜欢B"或者"B喜欢A"的效果,得到的效果是一样的。但是在现实中,并不是所有的人都能收获双向的爱情,像我这样的单相思还有很多。
所以,我们需要引入一个位置向量(Positional Encoding)来解决这个问题。
e
i
{e}^{i}
ei由人工设定,各不相同。

Transformer 中除了单词的 Embedding,还需要使用位置 Embedding 表示单词出现在句子中的位置。因为 Transformer 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于 NLP 来说非常重要。所以 Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置。
5. Encoder-Decoder
接下来我们看看self-attention在sequence2sequence model里面是怎么使用的,我们可以把Encoder-Decoder中的RNN用self-attention取代掉。
















 356
356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









