







YoloV3:An Incremental Improvement
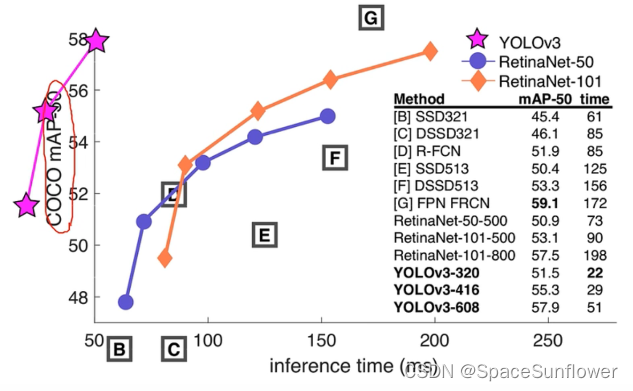
COCO AP
在这里插入图片描述
COCO mAP-50
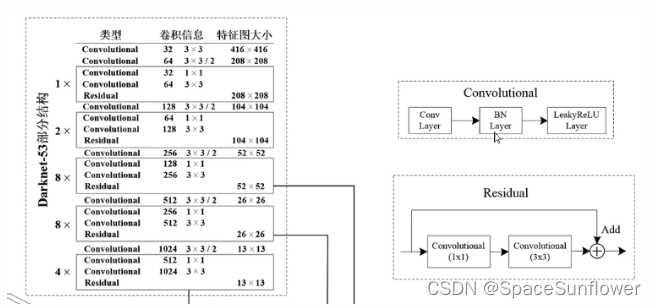
网络结构 Darknet-53
使用更深,性能更好的Backbone:Darknet-53
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
Darknet相较于Resnet效果更好一些:使用卷积层代替最大池化层,效果更好;同时参数量更小一点;
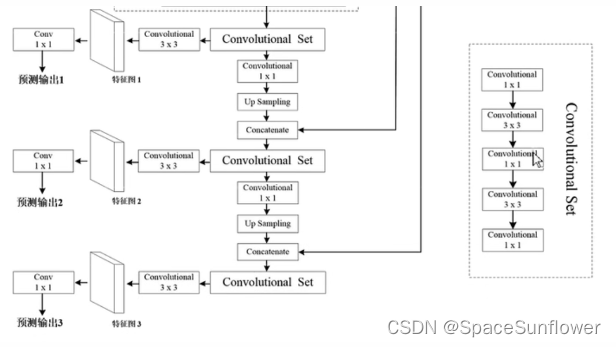
convolutional不是简单的卷积,而是卷积+BN层+LeakyReLU层;
Residual残差结构;
anchor box
使用K-means聚类得到九类,分别对应三个尺寸,每个尺寸对应三个框;
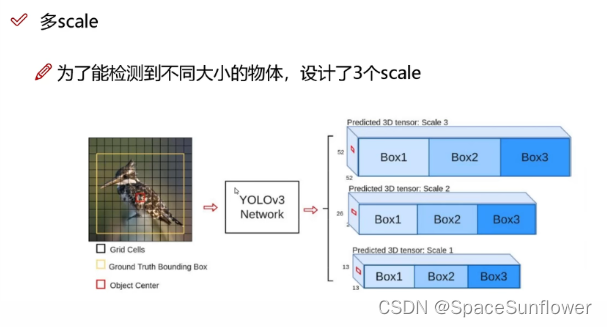
特征融合
在最后的预测过程中
特征图1为13 * 13,预测更大的图像
特征图2为26 * 26
特征图3为52 * 52,预测细粒度更高的图像
目标预测框的预测
Cx对应当前的左上角点的x坐标
Cy对应当前的左上角点的y坐标
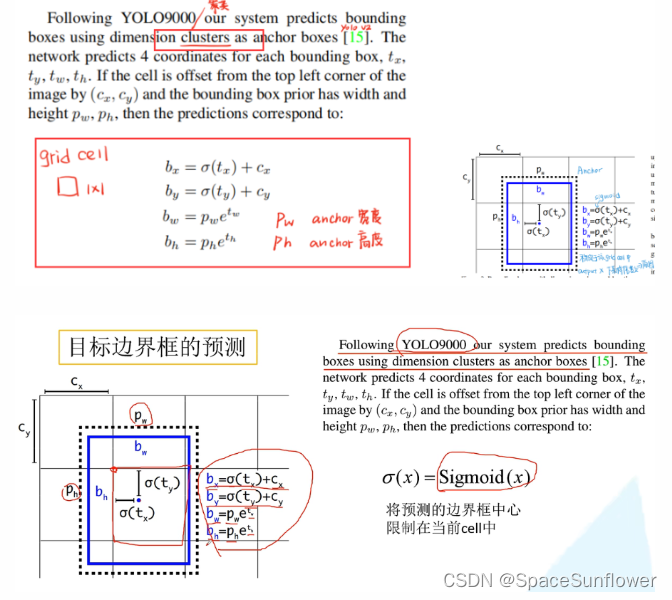
限制当前的边界框在cell中,可以加快收敛;
正负样本的匹配
采用重合程度最大的作为正样本;
有多少个object需要预测,就有多少个正样本;
如果非正样本,没有定位损失和类别损失,只有objectness
出现问题:正样本太少不好训练
每一个GT和Anchor Template模板进行计算
设置阈值,如果超过阈值就认为是正样本;
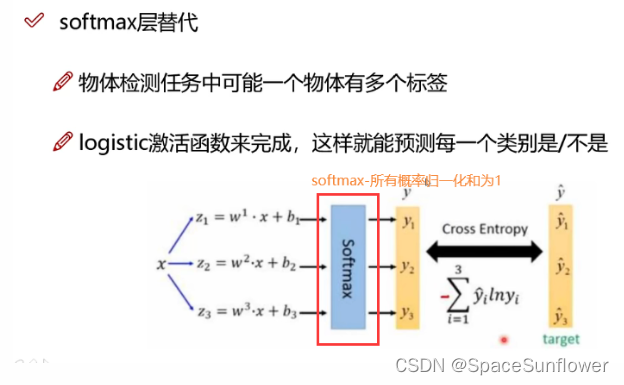
Softmax
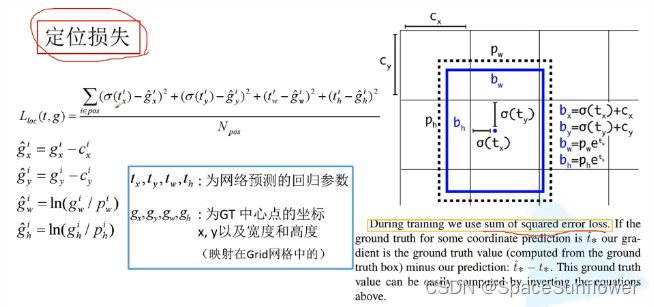
损失计算

置信度损失:二值交叉熵损失

类别损失:二值交叉熵损失
















 4752
4752











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











