







 超级会员免费看
超级会员免费看
 本文详细介绍了YOLOv3模型的设计思想,包括多尺度融合和目标检测策略。通过在不同层级的特征图上生成不同大小的锚框,YOLOv3能够检测不同尺寸的目标。在高层级的特征图上进行预测,结合低层级的细节信息,以增强模型的检测能力。同时,文章阐述了从锚框到预测框的转换过程,包括中心位置和大小的调整方法。
本文详细介绍了YOLOv3模型的设计思想,包括多尺度融合和目标检测策略。通过在不同层级的特征图上生成不同大小的锚框,YOLOv3能够检测不同尺寸的目标。在高层级的特征图上进行预测,结合低层级的细节信息,以增强模型的检测能力。同时,文章阐述了从锚框到预测框的转换过程,包括中心位置和大小的调整方法。
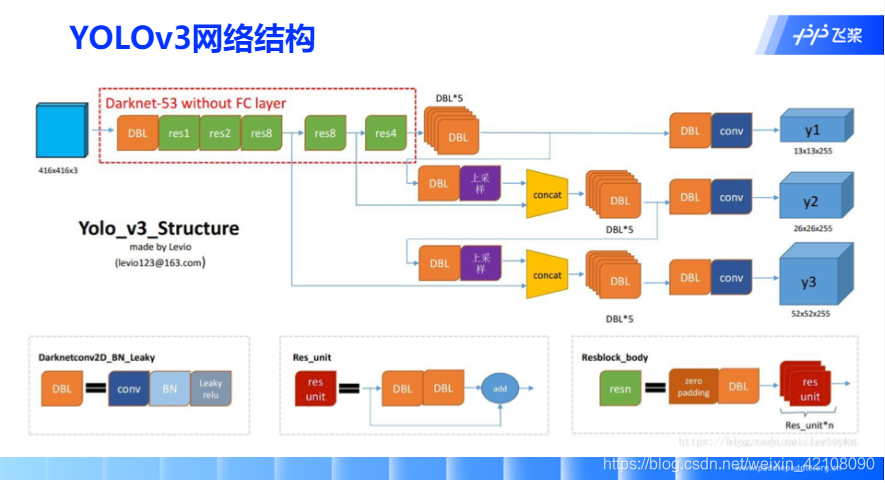
YOLO-V3 模型设计思想

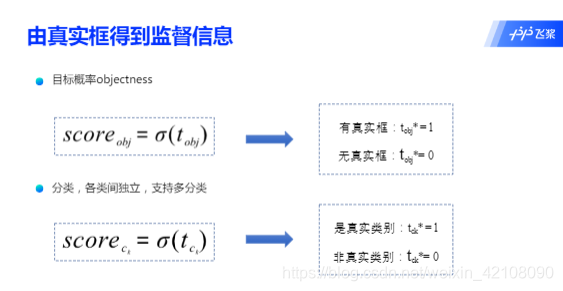
下半部分描述了生成候选区域的过程,首先将原图划分成多个小方块,每个小方块的大小是32×3232\times 3232×32,然后以每个小方块为中心分别生成一系列锚框,整张图片都会被锚框覆盖到。在每个锚框的基础上产生一个与之对应的预测框,根据锚框和预测框与图片上物体真实框之间的位置关系,对这些预测框进行标注。
这里的锚框生成方式和两阶段的算法不同,两阶段的算法通过RPN网络在特征图上生成Anchor
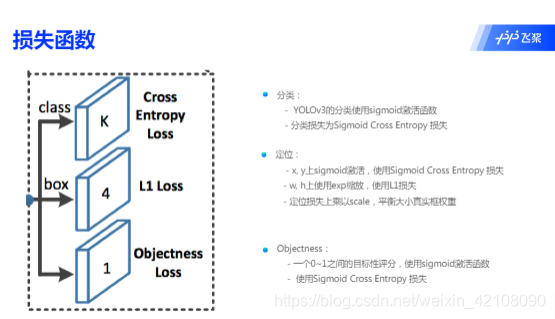
目前我们计算损失函数是在特征图P0的基础上进行的,它的步幅stride=32。特征图的尺寸比较小,像素点数目比较少,每个像素点的感受野很大,具有非常丰富的高层级语义信息,可能比较容易检测到较大的目标。为了能够检测到尺寸较小的那些目标,需要在尺寸较大的特征图上面建立预测输出。如果我们在C2或者C1这种层级的特征图上直接产生预测输出,可能面临新的问题,它们没有经过充分的特征提取,像素点包含的语义信息不够丰富,有可能难以提取到有效的特征模式。
在目标检测中,解决这一问题的方式是,将高层级的特征图尺寸放大之后跟低层级的特征图进行融合,得到的新特征图既能包含丰富的语义信息,又具有较多的像素点,能够描述更加精细的结构。

具体的网络实现方式如 图 所示:
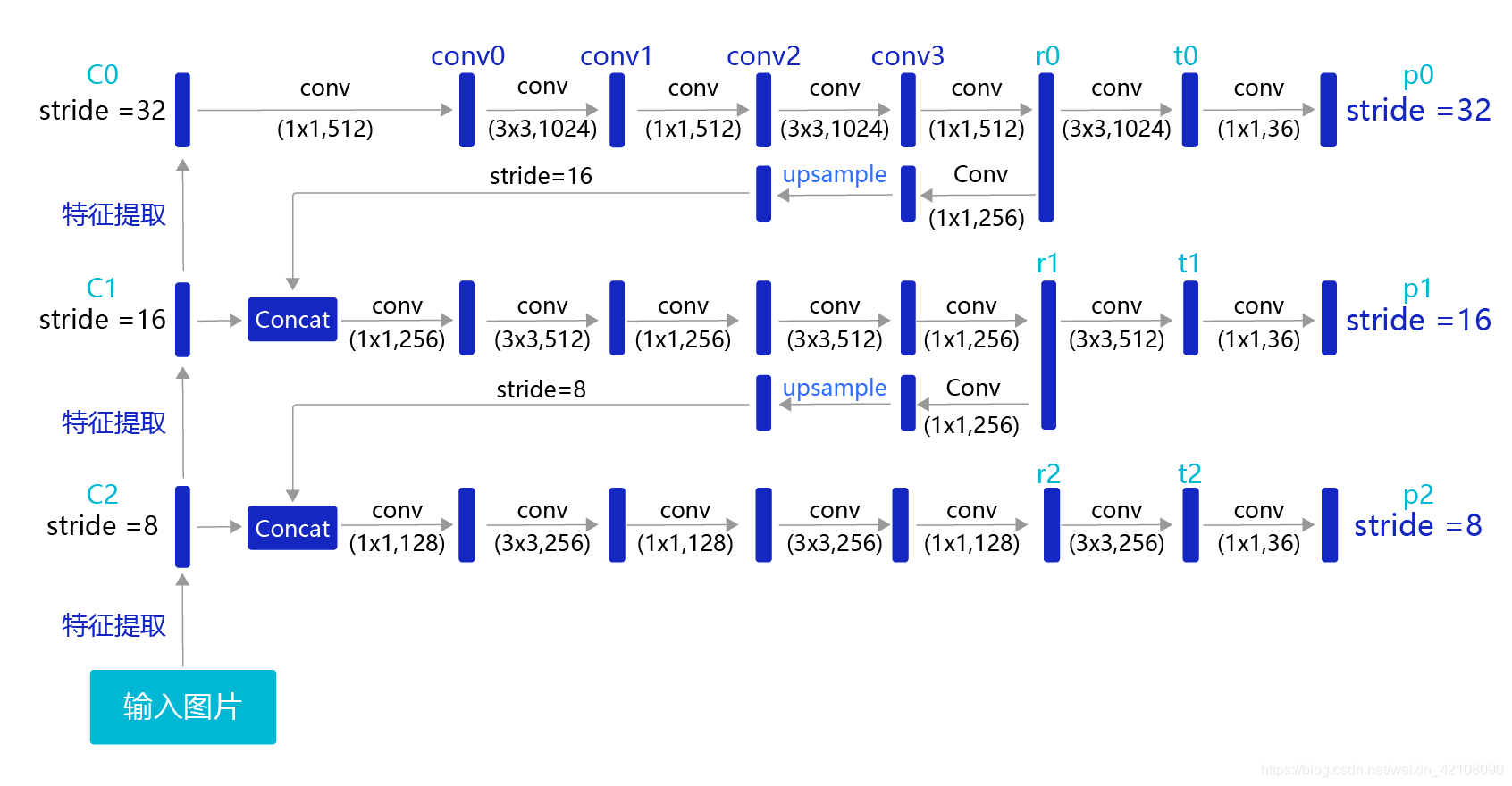
生成多层级的输出特征图P0、P1、P2
YOLO-V3在每个区域的中心位置产生3个锚框,在3个层级的特征图上产生锚框的大小分别为P2 [(10×13),(16×30),(33×23)],P1 [(30×61),(62×45),(59× 119)],P0[(116 × 90), (156 × 198), (373 × 326]。越往后的特征图上用到的锚框尺寸也越大,能捕捉到大尺寸目标的信息;越往前的特征图上锚框尺寸越小,能捕捉到小尺寸目标的信息。

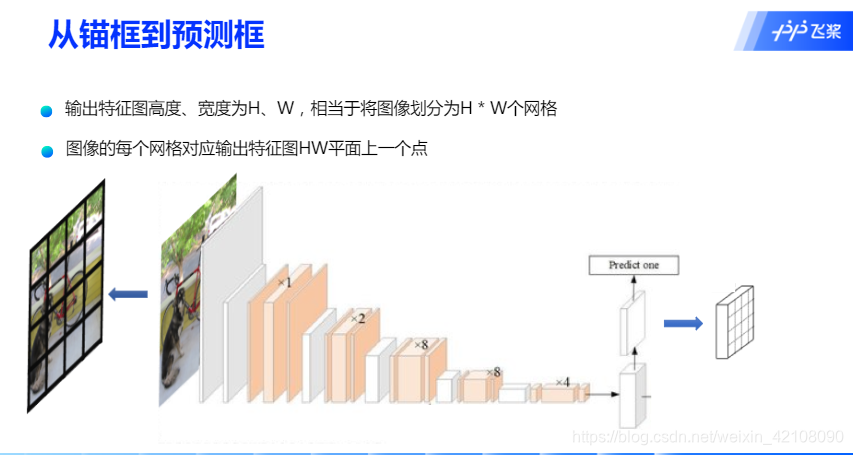
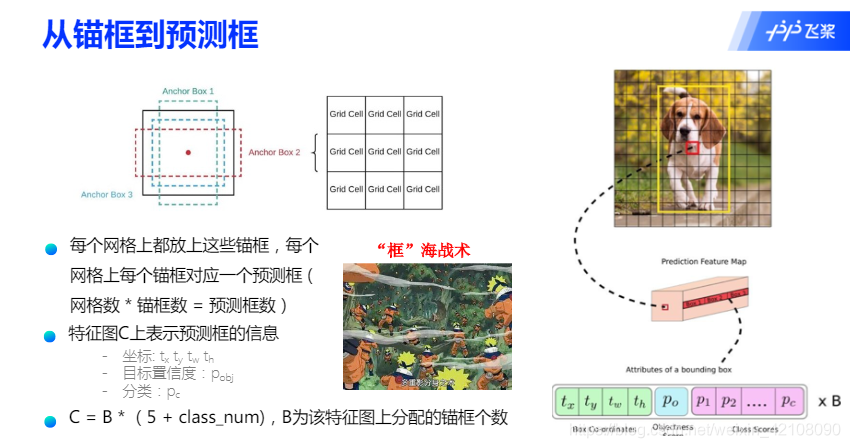
从锚框到预测框的映射关系
预测框的生成举例:
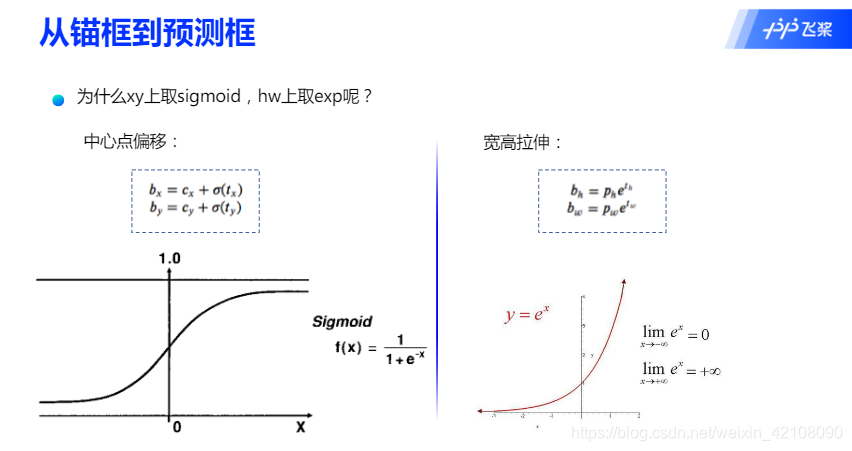
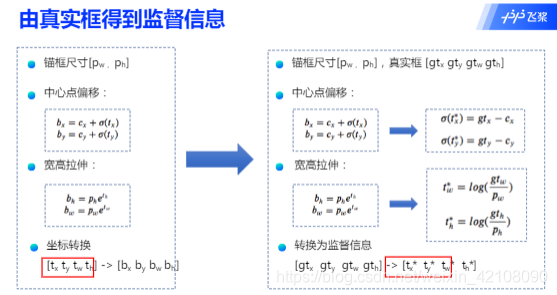
锚框的位置都是固定好的,不可能刚好跟物体边界框重合,需要在锚框的基础上进行位置的微调以生成预测框。预测框相对于锚框会有不同的中心位置和大小,采用什么方式能得到预测框呢?我们先来考虑如何生成其中心位置坐标。

比如上面图中在第10行第4列的小方块区域中心生成的一个锚框,如绿色虚线框所示。以小方格的宽度为单位长度,此小方块区域左上角的位置坐标是:
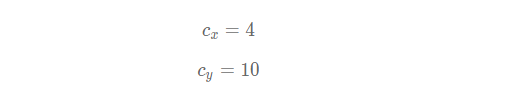
此锚框的区域中心坐标是:
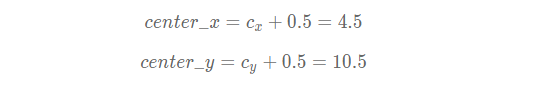
可以通过下面的方式生成预测框的中心坐标:
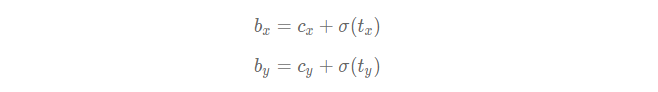
其中txt_xtx和tyt_yty 为实数
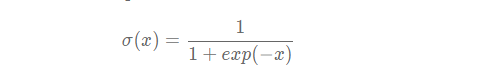
由于Sigmoid的函数值在0∼1之间,因此由上面公式计算出来的预测框的中心点总是落在第十行第四列的小区域内部。

锚框的大小是预先设定好的,在模型中可以当作是超参数,上图中画出的锚框尺寸是:
通过下面的公式生成预测框的大小:
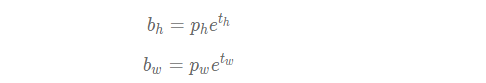




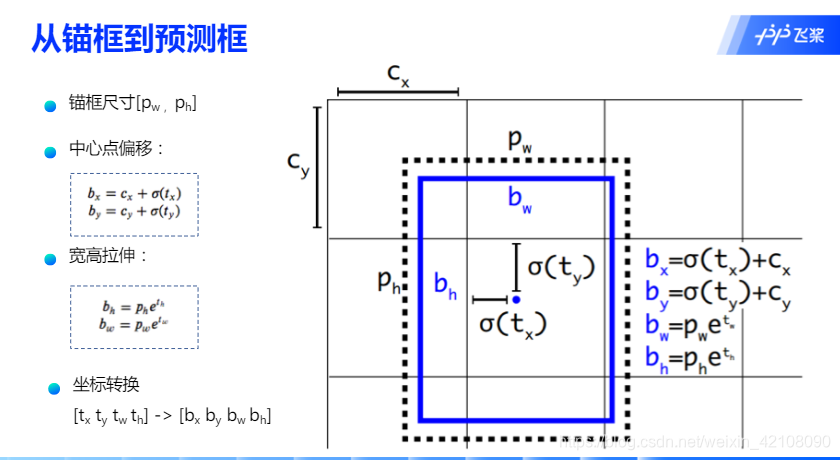
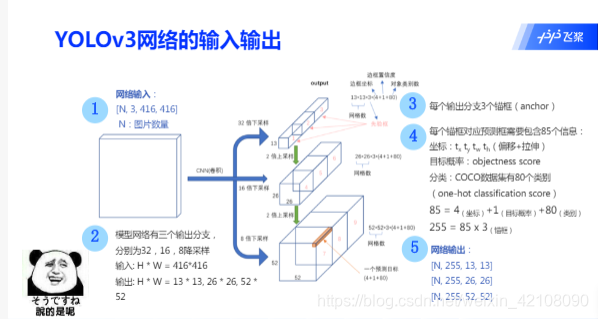
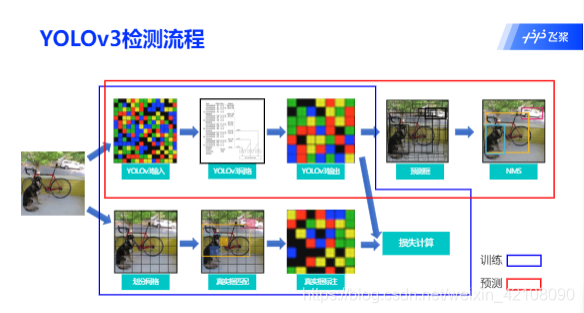


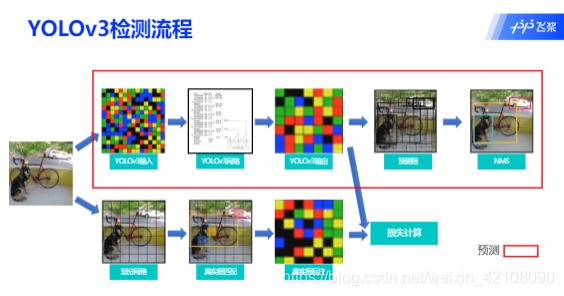

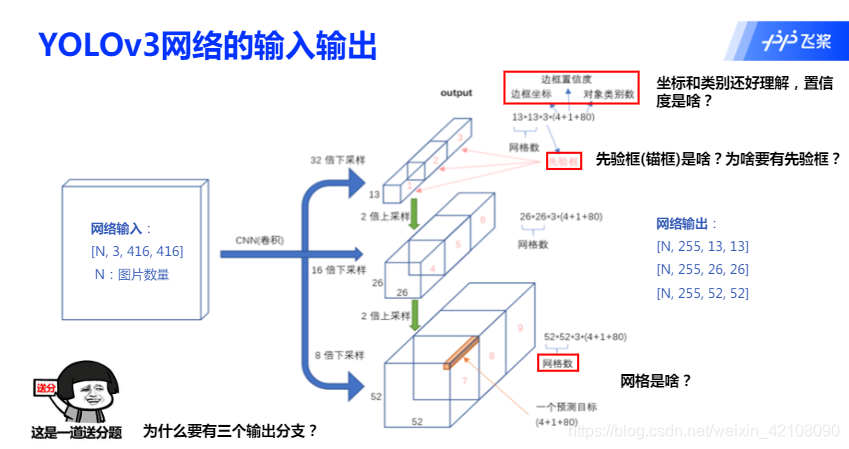
首先由特征提取网络对输入图像提取特征,得到 3 个不同大小的输出特征图,当输入图像宽高为 416416 时,三个 输出特征图为 1313、2626、5252,分别对应于输入的 32 倍、16 倍、8 倍下 采样,YOLOv3 在数据集上聚类得到 9 组 anchor。将三个输出特征图划分为 S*S 的网格,每个网格分别有 3 个预设的 anchor,当目标中心落在某个网格中时,就用该网格去检测它,并且用和 ground truth 交并比最大的 anchor 去预测,而剩余两组 anchor 则不参与预测。


















 1617
1617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











