







Introduction
提高感受野能获得更多的上下文信息,从而大大增益超分辨率(SR)的工作。然而通过加深网络的深度来扩大感受野会引入更多的变量,使网络更难收敛,推断时计算效率更低。另外一个简单的策略是用带有步长的卷积层或者池化层来降采样,能够很好的收集图片上下文信息,降低计算机视觉的高级应用的计算负担。然而,这次额都不适合低层次的图片处理问题因为重要的图片细节在降采样过程中损失了。LSTM将像素的预测公式化成了整个空间网格的连续化的推断问题。每个像素根据其前像素的信息来进行预测。然而,训练这样的网络很容易遇到梯度爆炸或梯度消失。因此他们目前只能用于小图片的任务(64*64).
本文最重要的贡献是information-compensated(IC) downsampling block。不像卷积层或者池化层,IC不仅能降采样,还能包吃住细节。
preliminary: 初步的
conjecture: 猜想
interleave: 夹杂
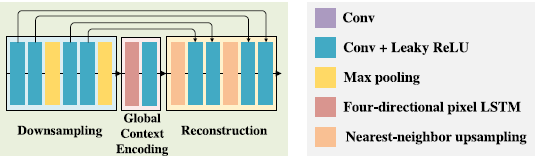
IC block
Downsampling Module:两层pooling效果最好。但只使用两层池化层是不能有效扩大感受野的,所以作者通过堆叠多个IC block来实现多层池化。
基于以上讨论,降采样模块包括4层 卷积层+Leaky ReLUs。每个卷积层的卷积核为3x3, stride为1. 池化层插入在第二,第四卷积层后面。
Global Context Encoding Module
公式化
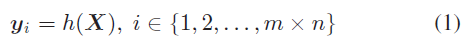
X是输入的特征图,mxn大小。在位置i的输出yi是考虑了所有位置的特征并使用映射函数h。本来h()使用的FC全连接层,但是这样参数量大大提升。所以使用了像素级别的LSTM。其处理
重构模块
使用Nearest-neighbor upsampling来上采样,后接两层Conv+Leaky ReLU。总共2次。并使用残差块。
网络结构Network Architecture
在网络第一和最后的IC block前后插入两个3x3的卷积层,用来预处理和最后的预测。所有中间的特征图的通道数都是64.输入为低分辨率的X,输出F(X)为HR图片Y与LR图片X之间的大概差别。结果Y = F(X)+X
使用mean squared error。
===================















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









